







大家好啊,我是董董灿。
今天分享一个上海蔚来汽车的AI算法岗位面试经验总结帖,面试岗位为算法工程师。
这次面试提到的问题,除了与实习相关内容和反问之外,面试官总共问了8个问题,主要集中在深度学习基础概念的理解上,在聚焦一点讲是集中在自然语言处理相关的算法理解上。

看了这个面经贴,我突然想到帖子中到的很多知识点,我写的文章都提到过。
比如梯度消失和梯度爆炸的原因,这一点在介绍激活函数时曾经提到过(点这里),LSTM 的更新门的原理(点这里)。
除了一些较简单的算法理解之外,面试中还重点问到了注意力机制的内容。
正好最近我在整理和撰写注意力机制相关的文章,比如如何理解AI模型的“注意力”?、用矩阵乘法来揭示注意力的分配、当注意力遇到 AI 模型等。
你可以点击上面的三个链接看一下相关的文章,相信你会对注意力这一重要的机制有更深刻的认识。
接下来,我将通过两个论文中的例子,来展示一下在AI模型中,注意力机制时如何帮助模型完成对于输入数据的注意的。
1、文本阅读
论文地址:
https://arxiv.org/pdf/1601.06733
文本阅读任务是让AI完成文本的阅读,并且可以理解文本所表达的意思,在这篇论文中,作者使用自注意力机制来完成机器阅读的任务。
所谓自注意力(Self-Attention)的关键是:计算同一个序列中不同位置的注意力关系,自注意力在文本阅读/文本总结/图像描述等场景中非常有效。
下面的图像展示了模型在完成文本阅读过程中,处理每个单词时更加关注其他的哪些单词,以此来提取词与词之间的关系,从而更好地理解句子。

上图中,红色的词为模型当前正在识别的词,蓝色阴影的词表示此时模型更加关注的其他词,也就是说和红色的词更加有关联的词。
可以看到,当模型观察到 chasing 单词时,会注意到与 chasing 更加有关系的是 FBI 和 is.
2、文本描述
论文地址:
https://proceedings.mlr.press/v37/xuc15.pdf
这篇论文完成的是图像描述任务(输入一张图像,输出对于这张图像的描述语言)。
作者利用注意力机制来完成图像的信息捕捉。使用的仍然是典型的 Encoder-Decoder 架构。只不过因为输入数据是图像这种结构化的数据,因此,Encoder 采用的 CNN 来完成图像的特征提取,而 Decoder则采用了 LSTM 完成图像特征到描述文字的转换。
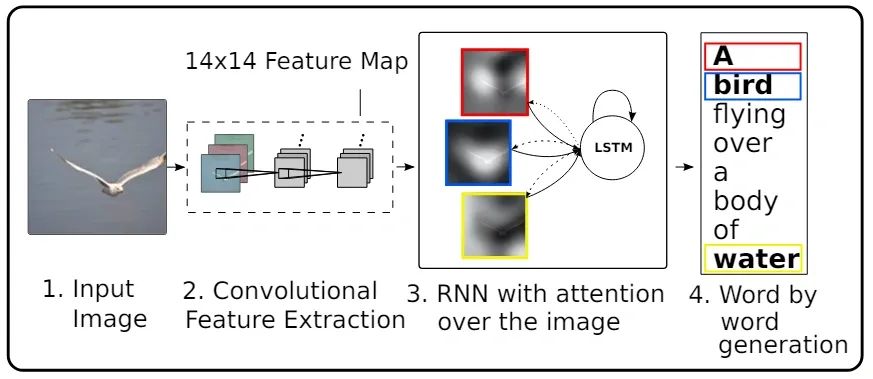
下图展示了在这个过程中,模型在输出每个描述单词时,其注意力更多地关注在图像中的哪些地方。

模型在看到上述的图像后,输出的描述为:A woman is throwing a frisbee in a park。可以看到,当输出 woman 的时候,模型更加关注图中的人物,而当输出 a frisbee(一个飞盘)时,模型更加关注图中的红色飞盘部分。
说明注意力机制在处理图像这种结构化的数据中也具有非常好的效果。
我的技术专栏已经有几百位朋友加入了,如果你也希望了解AI技术,学习AI视觉或者大语言模型,戳下面的链接加入吧,这可能是你学习路上非常重要的一次点击呀!
这里还有一个AI视觉入门的1对1训练营,训练营将带你深入理解AI视觉算法、从零手写AI视觉模型。如果你希望快速入门AI视觉,可以点这里查看训练营介绍。
最后,送一句话给大家:生活不止眼前,还有诗和远方,共勉~




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











