







文章目录
参考官网文档:
【 ES创建自定义词语分析器(自定义分析器接收参数,demo示例)】
【 ES创建索引时Mapping映射配置analyzer参数(为字段配置不同的分析器,demo示例)】
环境
- elasticsearch6.8.6版本:已安装ik分词器、icu分词器、pinyin分词器(分词器版本要和es版本一致)
- postman测试工具
- 视图工具elasticsearch-head(https://github.com/mobz/elasticsearch-head)
注!
以下postman截图中{{domain}}等于 http://127.0.0.1:9200
创建索引:配置自定义分词器、字段指定分词器
配置的分词器使用专业的中文分词器(IK分词器),配置分词模式为(ik_smart),配置字符过滤(char_filters)、过滤令牌(filter)。
自定义分词器参数说明
【ES官网关于自定义分词器的参数说明】
【ES官网关于定义分词器,type参数说明】
【ES官网关于构建内置或者自定义分词器tokenizer参数说明】
【ES官网关于char-filters字符过滤配置】
创建索引:custom_analyzer_comment
postman请求:
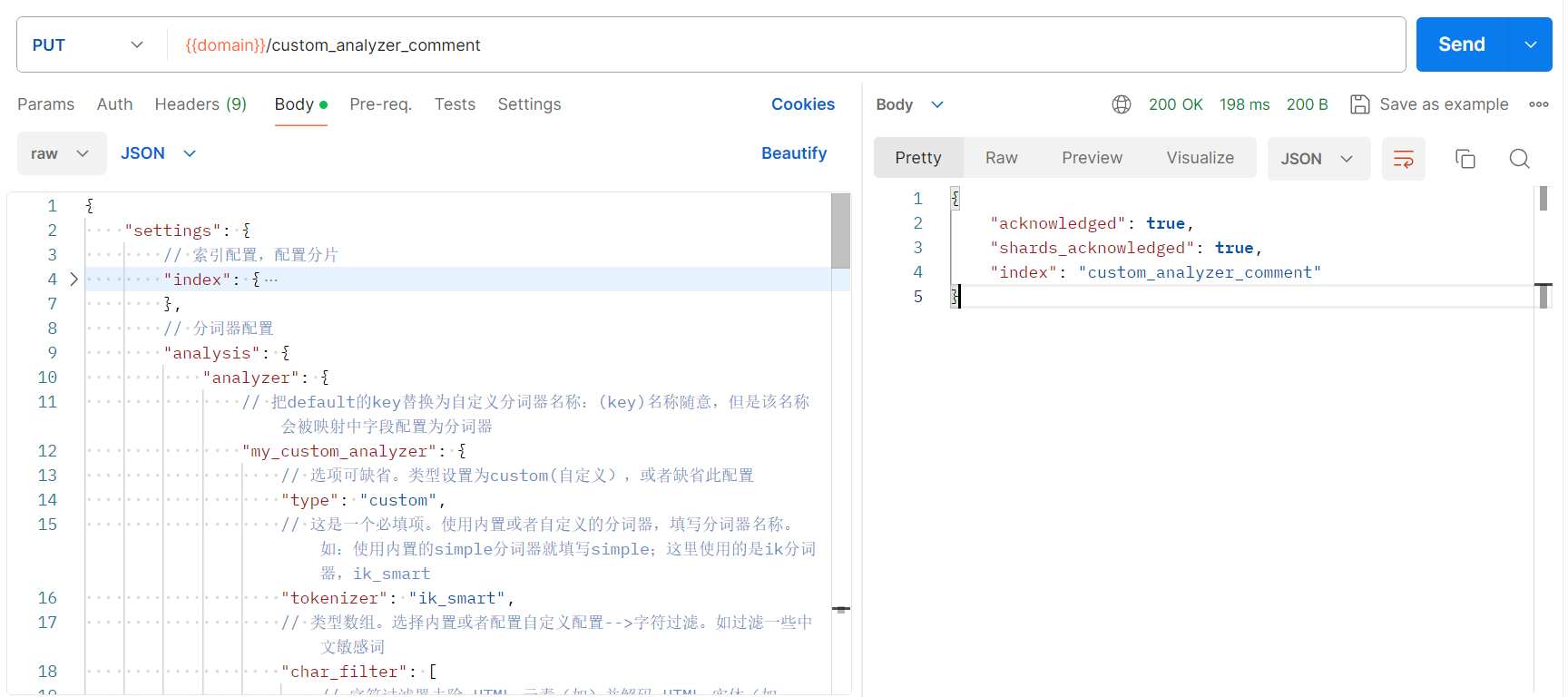
发送创建索引命令:参数有注释
# 创建索引:custom_analyzer_comment
PUT {{domain}}/custom_analyzer_comment
# 创建索引的参数:分词器配置、mapping字段映射配置
{
"settings": {
// 索引配置,配置分片
"index": {
"number_of_shards": "5",
"number_of_replicas": "1"
},
// 分词器配置
"analysis": {
"analyzer": {
// 把default的key替换为自定义分词器名称:(key)名称随意,但是该名称会被映射中字段配置为分词器
"my_custom_analyzer": {
// 选项可缺省。类型设置为custom(自定义),或者缺省此配置
"type": "custom",
// 这是一个必填项。使用内置或者自定义的分词器,填写分词器名称。如:使用内置的simple分词器就填写simple;这里使用的是ik分词器,ik_smart
"tokenizer": "ik_smart",
// 类型数组。选择内置或者配置自定义配置-->字符过滤。如过滤一些中文敏感词
"char_filter": [
// 字符过滤器去除 HTML 元素(如)并解码 HTML 实体(如 <b> & )
"html_strip",
// 字符筛选器将指定字符串的任何匹配项替换为指定的替换项
// 同时也支持自定义名称,需要到与analyzer对象同级的char_filter做单独配置
// 敏感词过滤配置
"my_sensitive"
],
// 类型数组。选择内置或者配置自定义配置--> 令牌筛选过滤
"filter": [
// 英文全部转为小写的令牌过滤标记,此项内置。
"lowercase",
// 配置一个自定义的中文停用词
"chinese_stop_word"
],
// 配置编制索引时的间隙:缺省值100,详情看官网
"position_increment_gap": 100
},
// 配置第二个英文停用词分析器
"my_custom_analyzer_enstop": {
// 自定义分词器
"type": "custom",
// 同样使用ik分词器
"tokenizer": "ik_smart",
"filter": [
"lowercase",
// 英文停用词过滤
"english_stop_sord"
]
}
},
// 把字符过滤放在和analyzer同级,为mapping类型字符映射做自定义配置
"char_filter": {
"my_sensitive": {
// 为analyzer.my_custom_analyzer.char_filter.my_sensitive做单独配置
"type": "mapping",
// 比如做敏感词替换
"mappings": [
"操 => *",
"我操 => **",
"草 => 艹"
]
}
},
// 令牌过滤放在和analyzer同级,为filter中chinese_stop_word做自定义配置
"filter": {
// 配置自定义的中文停用词
// 这个名字是analyzer中定义的中文停用词配置
"chinese_stop_word": {
"type": "stop",
"stopwords": [
"嗯",
"啊",
"这",
"是",
"哦",
"噢",
"那"
]
},
"english_stop_sord": {
"type": "stop",
"stopwords": "_english_"
}
}
}
},
// 配置字段映射关系、配置字段类型、配置字段指定分词器
"mapping": {
"_doc": {
"properties": {
// 评论ID
"id": {
"type": "long"
},
// 用户网名
"username": {
"type": "text",
// 以下三个分词器同时生效:新增字段索引时、字段查询时
// analyzer:将索引指向my_custom_analyzer分词器
"analyzer": "my_custom_analyzer",
// search_analyzer:指向my_custom_analyzer_enstop分词器
"search_analyzer": "my_custom_analyzer_enstop",
// 指向my_custom_analyzer分词器,并保证不从一个被引用的短语中删除停用词
// 如:被引号括起来的短语“This is a sanmao”这里面的停用词不会被删除
"search_quote_analyzer": "my_custom_analyzer"
},
// 评论内容
"comment_content": {
"type": "text",
"analyzer": "my_custom_analyzer",
"search_analyzer": "my_custom_analyzer_enstop",
"search_quote_analyzer": "my_custom_analyzer"
},
// 评论创建时间
"create_date": {
"type": "date"
},
// 评论展示状态:1 允许展示 0 评论被屏蔽
"show_status": {
"type": "int"
},
// 评论是否删除 1 已删除、0未删除
"deleted": {
"type": "int"
}
}
}
}
}
使用索引中自定义的分词器进行分词分析
自定义分词器my_custom_analyzer分词测试:
分词结果查询:
【ES6.8.6 分词器安装&使用、查询分词结果(内置分词器、icu、ik、pinyin分词器)-CSDN博客】
my_custom_analyzer分词器:使用了ik_smart粗粒度分词器,支持过滤html标签、支持替换敏感词(替换的敏感词见请求参数)、支持英文全转为小写、支持中文停用词(自定义中文停用词,停用词见请求参数)
测试中文停用词、英文字母转小写
postman请求: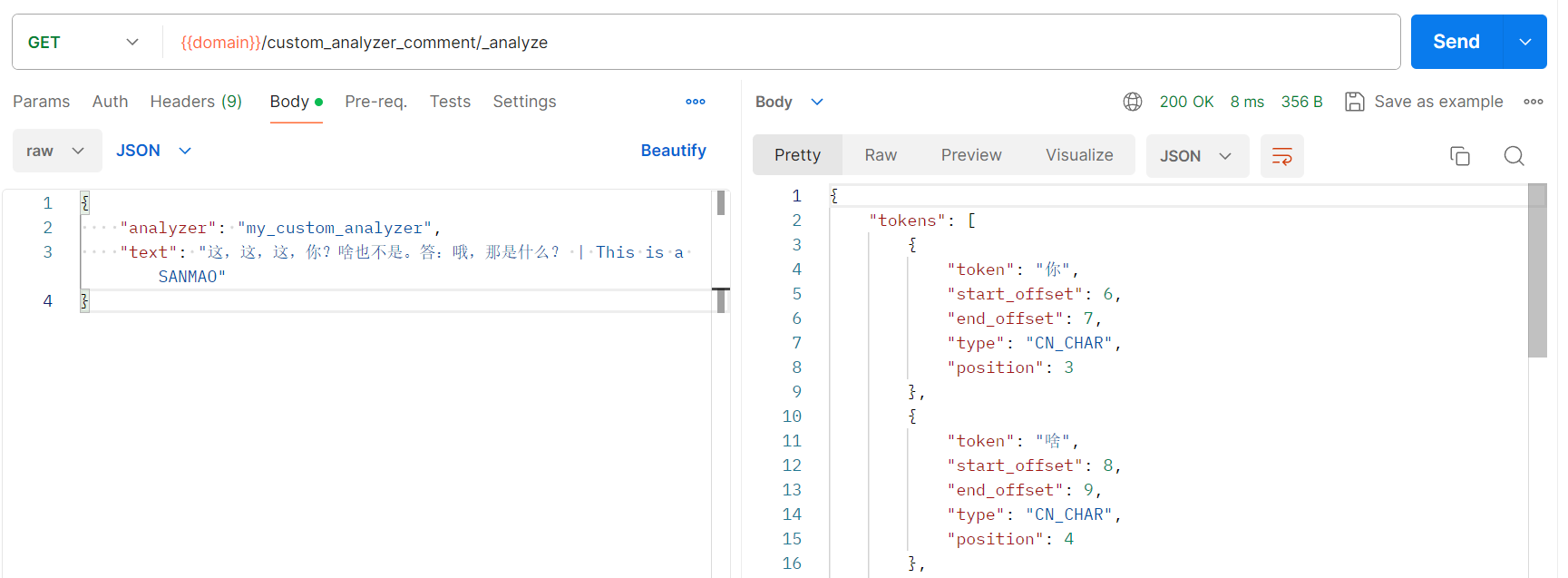
请求命令:
GET /custom_analyzer_comment/_analyze
参数===>
{
"analyzer": "my_custom_analyzer",
"text": "这,这,这,你?啥也不是。答:哦,那是什么? | This is a SANMAO"
}
预期结果===>
"这",被停用,在分词中被删除;
"哦",被停用,在分词中被删除;
"那",被停用,在分词中被删除;(实际与预期不符,"那是"被分词为短语,所以"那"没有被停用)
分词结果:
根据filter->chinese_stop_word中配置的停用词,未被组成短语的,都被在分词中删除,英文字母也都被转为了小写,返回结果符合预期。但是根据返回结果看,不止配置的中文停用词,英文停用词也在分词结果中被删除。
{
"tokens": [
{
"token": "你",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 3
},
{
"token": "啥",
"start_offset": 8,
"end_offset": 9,
"type": "CN_CHAR",
"position": 4
},
{
"token": "也",
"start_offset": 9,
"end_offset": 10,
"type": "CN_CHAR",
"position": 5
},
{
"token": "不是",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 6
},
{
"token": "答",
"start_offset": 13,
"end_offset": 14,
"type": "CN_CHAR",
"position": 7
},
{
"token": "那是",
"start_offset": 17,
"end_offset": 19,
"type": "CN_WORD",
"position": 9
},
{
"token": "什么",
"start_offset": 19,
"end_offset": 21,
"type": "CN_WORD",
"position": 10
},
{
"token": "sanmao",
"start_offset": 35,
"end_offset": 41,
"type": "ENGLISH",
"position": 11
}
]
}
测试敏感词替换:根据分词字符过滤配置替换敏感词
postman请求:
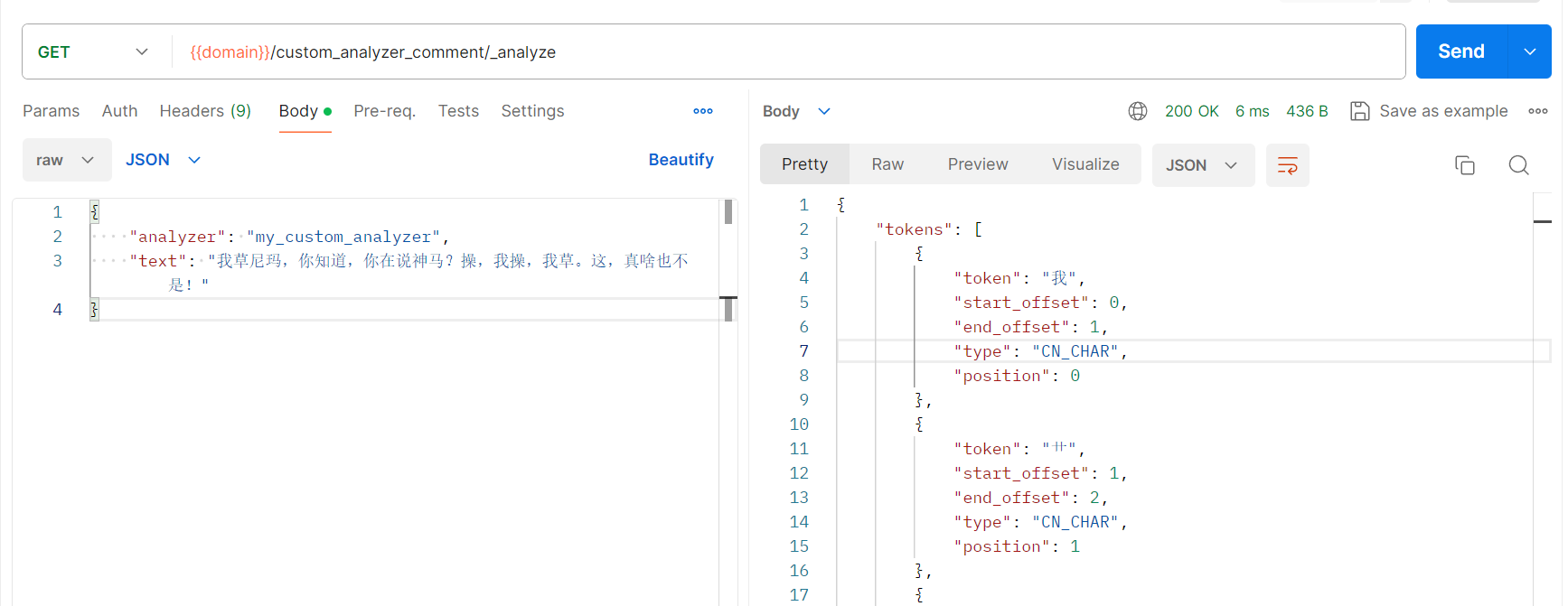
请求命令:
GET /custom_analyzer_comment/_analyze
参数===>
{
"analyzer": "my_custom_analyzer",
"text": "我草尼玛,你知道,你在说神马?操,我操,我草。这,真啥也不是!"
}
预期结果===>
"草",被替换"艹";
"操",被替换"*";(实际不符合预期,直接被删除了)
"我操",被替换"**";(实际不符合预期,直接被删除了)
"我草",被替换"我艹";
分词结果:
敏感词替换分词生效。但是替换的星号直接在分词结果中被删除。
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "艹",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "尼玛",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "你",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 3
},
{
"token": "知道",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 4
},
{
"token": "你",
"start_offset": 9,
"end_offset": 10,
"type": "CN_CHAR",
"position": 5
},
{
"token": "在说",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 6
},
{
"token": "神马",
"start_offset": 12,
"end_offset": 14,
"type": "CN_WORD",
"position": 7
},
{
"token": "我",
"start_offset": 20,
"end_offset": 21,
"type": "CN_CHAR",
"position": 8
},
{
"token": "艹",
"start_offset": 21,
"end_offset": 22,
"type": "CN_CHAR",
"position": 9
},
{
"token": "真",
"start_offset": 25,
"end_offset": 26,
"type": "CN_CHAR",
"position": 11
},
{
"token": "啥",
"start_offset": 26,
"end_offset": 27,
"type": "CN_CHAR",
"position": 12
},
{
"token": "也",
"start_offset": 27,
"end_offset": 28,
"type": "CN_CHAR",
"position": 13
},
{
"token": "不是",
"start_offset": 28,
"end_offset": 30,
"type": "CN_WORD",
"position": 14
}
]
}
自定义分词器my_custom_analyzer_enstop分词测试
my_custom_analyzer_enstop分词器:使用了ik_smart粗粒度分词器,支持英文全转为小写、支持英文停用词。
postman测试:综合测试,敏感词,中文停用词、大小写是否会如预期被分词器处理。
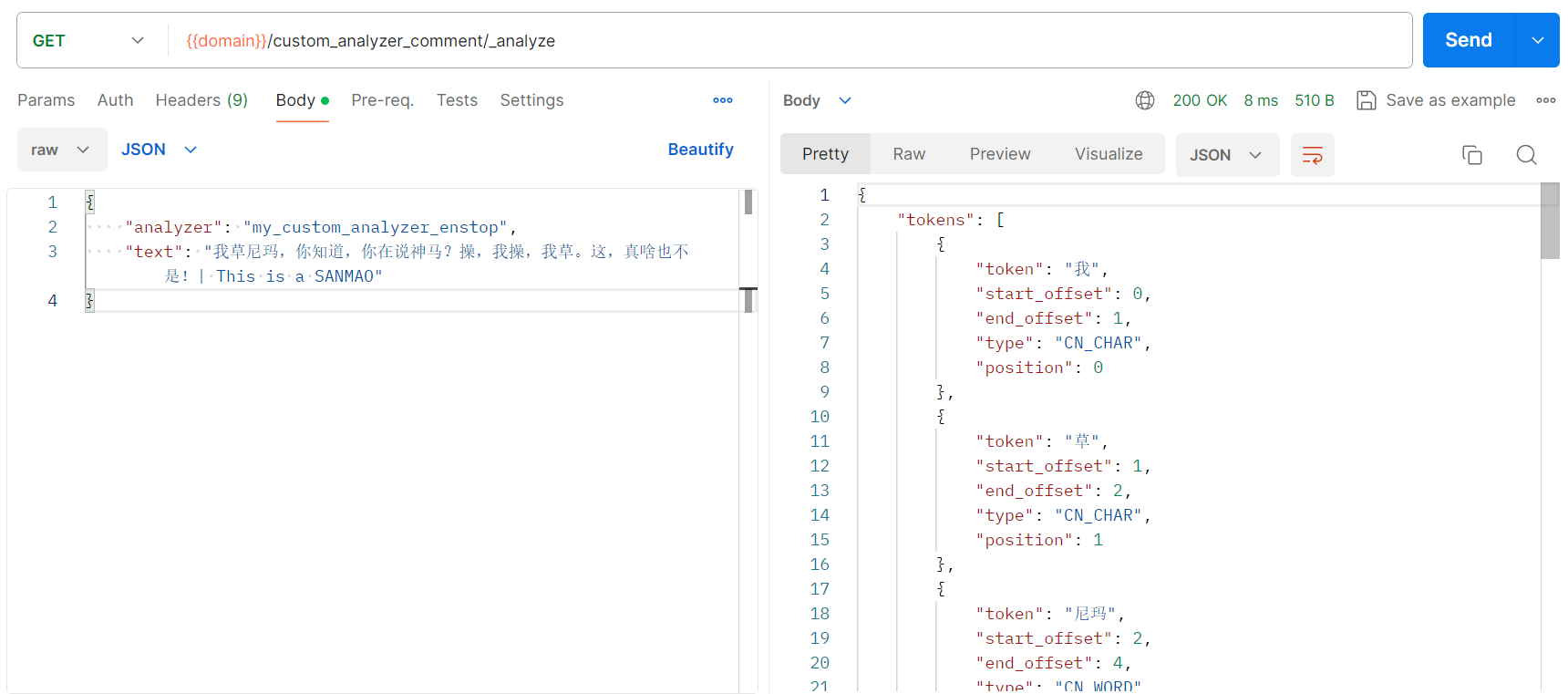
请求命令:
# 测试分词结果
GET /custom_analyzer_comment/_analyze
# 参数 ==>
{
"analyzer": "my_custom_analyzer_enstop",
"text": "我草尼玛,你知道,你在说神马?操,我操,我草。这,真啥也不是!| This is a SANMAO"
}
分词结果:
敏感词没有替换、中文停用词没有替换,符合预期分词;
英文停用词删除、英文大小转小写,符合预期分词;
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "草",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "尼玛",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "你",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 3
},
{
"token": "知道",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 4
},
{
"token": "你",
"start_offset": 9,
"end_offset": 10,
"type": "CN_CHAR",
"position": 5
},
{
"token": "在说",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 6
},
{
"token": "神马",
"start_offset": 12,
"end_offset": 14,
"type": "CN_WORD",
"position": 7
},
{
"token": "操",
"start_offset": 15,
"end_offset": 16,
"type": "CN_CHAR",
"position": 8
},
{
"token": "我",
"start_offset": 17,
"end_offset": 18,
"type": "CN_CHAR",
"position": 9
},
{
"token": "操",
"start_offset": 18,
"end_offset": 19,
"type": "CN_CHAR",
"position": 10
},
{
"token": "我",
"start_offset": 20,
"end_offset": 21,
"type": "CN_CHAR",
"position": 11
},
{
"token": "草",
"start_offset": 21,
"end_offset": 22,
"type": "CN_CHAR",
"position": 12
},
{
"token": "这",
"start_offset": 23,
"end_offset": 24,
"type": "CN_CHAR",
"position": 13
},
{
"token": "真",
"start_offset": 25,
"end_offset": 26,
"type": "CN_CHAR",
"position": 14
},
{
"token": "啥",
"start_offset": 26,
"end_offset": 27,
"type": "CN_CHAR",
"position": 15
},
{
"token": "也",
"start_offset": 27,
"end_offset": 28,
"type": "CN_CHAR",
"position": 16
},
{
"token": "不是",
"start_offset": 28,
"end_offset": 30,
"type": "CN_WORD",
"position": 17
},
{
"token": "sanmao",
"start_offset": 43,
"end_offset": 49,
"type": "ENGLISH",
"position": 18
}
]
}
附录
在创建索引时出现的异常
可能因es版本不同,出现配置字段类型不一样。
illegal_state_exception --> only value lists are allowed in serialized settings
错误原因:在序列化设置中仅允许值列表。分析是某个配置字段接收的参数类型不正确。
错误返回:
{
"error": {
"caused_by": {
"reason": "only value lists are allowed in serialized settings",
"type": "illegal_state_exception"
},
"reason": "Failed to load settings from [{\"index\":{\"number_of_shards\":\"5\",\"number_of_replicas\":\"1\"},\"analysis\":{\"filter\":[{\"chinese_stop_word\":{\"type\":\"stop\",\"stopwords\":[\"嗯\",\"啊\",\"这\",\"是\",\"哦\",\"噢\",\"那\"]}}],\"char_filter\":[{\"mappings\":[\"操 => *\",\"我操 => **\",\"草 => 艹\"],\"type\":\"mapping\"}],\"analyzer\":{\"my_custom_analyzer_enstop\":{\"filter\":[\"lowercase\",\"english_stop\"],\"type\":\"custom\",\"tokenizer\":\"ik_smart\"},\"my_custom_analyzer\":{\"filter\":[\"lowercase\",\"chinese_stop_word\"],\"char_filter\":[\"html_strip\",\"mapping\"],\"position_increment_gap\":100,\"type\":\"custom\",\"tokenizer\":\"ik_smart\"}}}}]",
"root_cause": [
{
"reason": "Failed to load settings from [{\"index\":{\"number_of_shards\":\"5\",\"number_of_replicas\":\"1\"},\"analysis\":{\"filter\":[{\"chinese_stop_word\":{\"type\":\"stop\",\"stopwords\":[\"嗯\",\"啊\",\"这\",\"是\",\"哦\",\"噢\",\"那\"]}}],\"char_filter\":[{\"mappings\":[\"操 => *\",\"我操 => **\",\"草 => 艹\"],\"type\":\"mapping\"}],\"analyzer\":{\"my_custom_analyzer_enstop\":{\"filter\":[\"lowercase\",\"english_stop\"],\"type\":\"custom\",\"tokenizer\":\"ik_smart\"},\"my_custom_analyzer\":{\"filter\":[\"lowercase\",\"chinese_stop_word\"],\"char_filter\":[\"html_strip\",\"mapping\"],\"position_increment_gap\":100,\"type\":\"custom\",\"tokenizer\":\"ik_smart\"}}}}]",
"type": "settings_exception"
}
],
"type": "settings_exception"
},
"status": 500
}
错误修改:
...
"char_filter": [
{
// 为analyzer.my_custom_analyzer.char_filter.mapping做单独配置
"type": "mapping",
// 比如做敏感词替换
"mappings": [
"操 => *",
"我操 => **",
"草 => 艹"
]
}
]
...
修改为
...
"char_filter": {
"my_sensitive": {
// 为analyzer.my_custom_analyzer.char_filter.my_sensitive做单独配置
"type": "mapping",
// 比如做敏感词替换
"mappings": [
"操 => *",
"我操 => **",
"草 => 艹"
]
}
}
...

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











