






 本文探讨了如何利用InternLM和LangChain搭建知识库,对比了RAG(检索增强生成)与Fine-tuning方法在获取最新知识、专业能力及定制化成本上的优缺点,重点介绍了RAG的工作原理和在WebDemo中的部署过程。
本文探讨了如何利用InternLM和LangChain搭建知识库,对比了RAG(检索增强生成)与Fine-tuning方法在获取最新知识、专业能力及定制化成本上的优缺点,重点介绍了RAG的工作原理和在WebDemo中的部署过程。
基于 InternLM 和 LangChain 搭建你的知识库

大模型开发范式
LLM的局限性:知识时效性受限:如何让LLM能够获取最新的知识;专业能力有限:如何打造垂域大模型;定制化成本高:如何打造个人专属的LLM应用
RAG VS Finetune
-
RAG(Retrieval-Augmented Generation):RAG是一种基于检索增强生成的方法。它结合了检索模型和生成模型的优势,通过从大规模文本语料库中检索相关信息来辅助生成文本。RAG使用预训练的检索模型来检索相关的上下文,然后将检索到的信息与生成模型结合,生成最终的输出。
大基座模型的能力上限,极大程度决定的RAG应用的能力天花板,同时RAG应用每次需要将检索到的相关文档和用户提问—起交给大模型进行回答,占用了大量的模型上下文,因此回答知识有限,对于一些需要大跨度收集知识进行总结性回答的问题表现不佳其核心优势在于可个性化微调且知识覆盖面广。
-
Fine-tuning(微调):Fine-tuning是指在预训练模型的基础上,使用特定任务的数据进行进一步的训练和调整。预训练模型通常是在大规模的通用语料上进行无监督训练得到的,具有一定的语言理解能力。而通过在特定任务的数据集上进行微调,预训练模型可以适应特定任务的要求,提高性能并增强模型的表现。
Fine-tuning范式的应用将在个性化数据上微调因此可以充分理合个性化数据,尤其是对于非可见知识,同时Fine-tuning范式的应用是─个新的个性化大模型,其仍然具有大问题的广阔知识欲。因此可以回答的问题知识覆盖面广,但是Fine-tuning需要在新的数据集上进行训练成本高昂,需要很多的GPU算力和个性化数据。同时Fine-tuning是无法解决实时更新的问题,因为其更新的成本仍然很高
两者优劣对比如下:

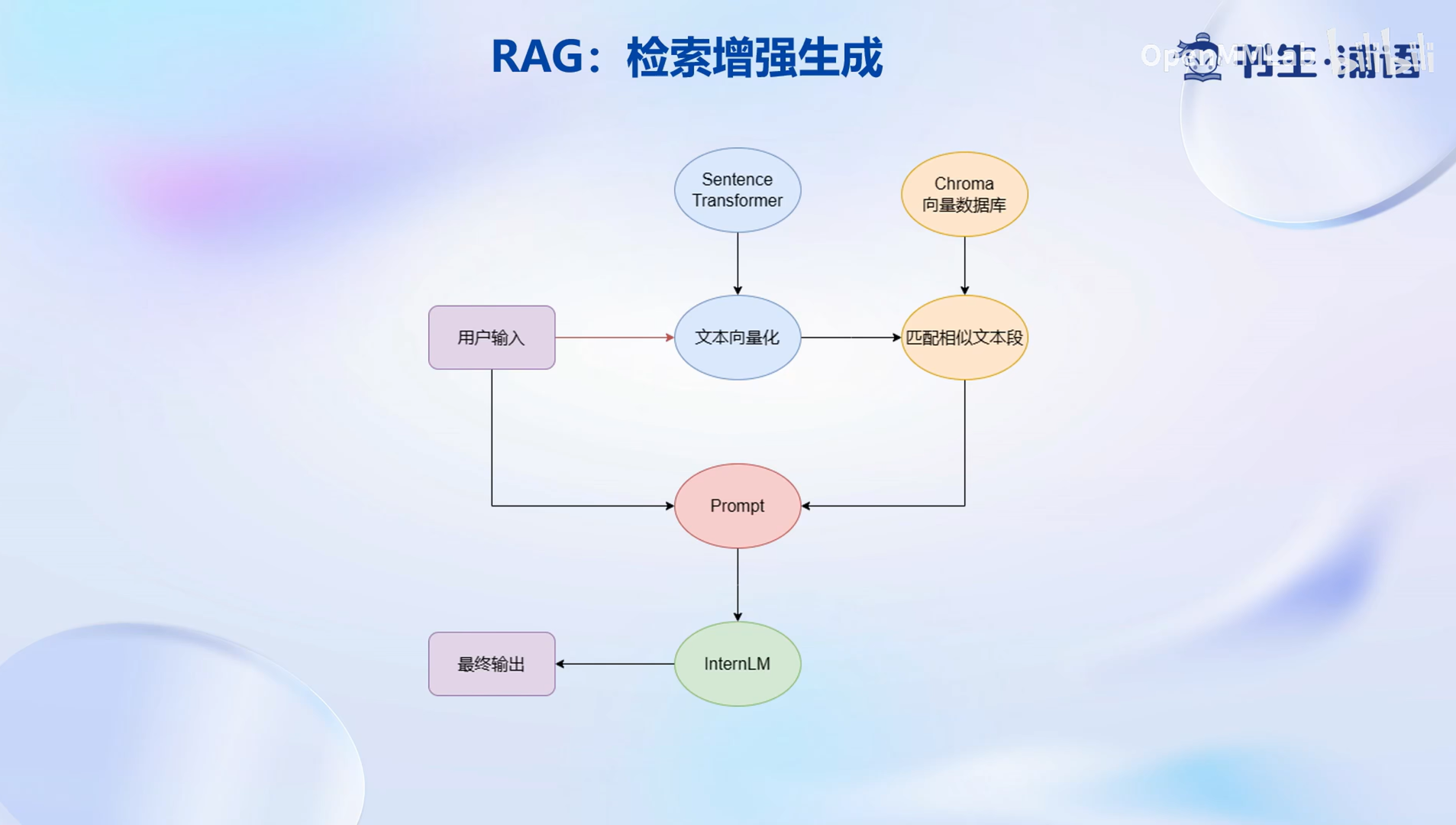
RAG的基本思想
对于每—个用户输入,应用会首先将基于向量模型Sentence transformer将输入文本转化为向量,并在向量数据库中匹配相似的文本段,在这里我们认为与问题相似的文本段大概率包含了问题的答案,然后我们会将用户的输入和检索到的相似文本段一起嵌入到模型的prompt中传递给InternLM,要求他对问题作出最终的回答作为最后的输出
LangChain框架

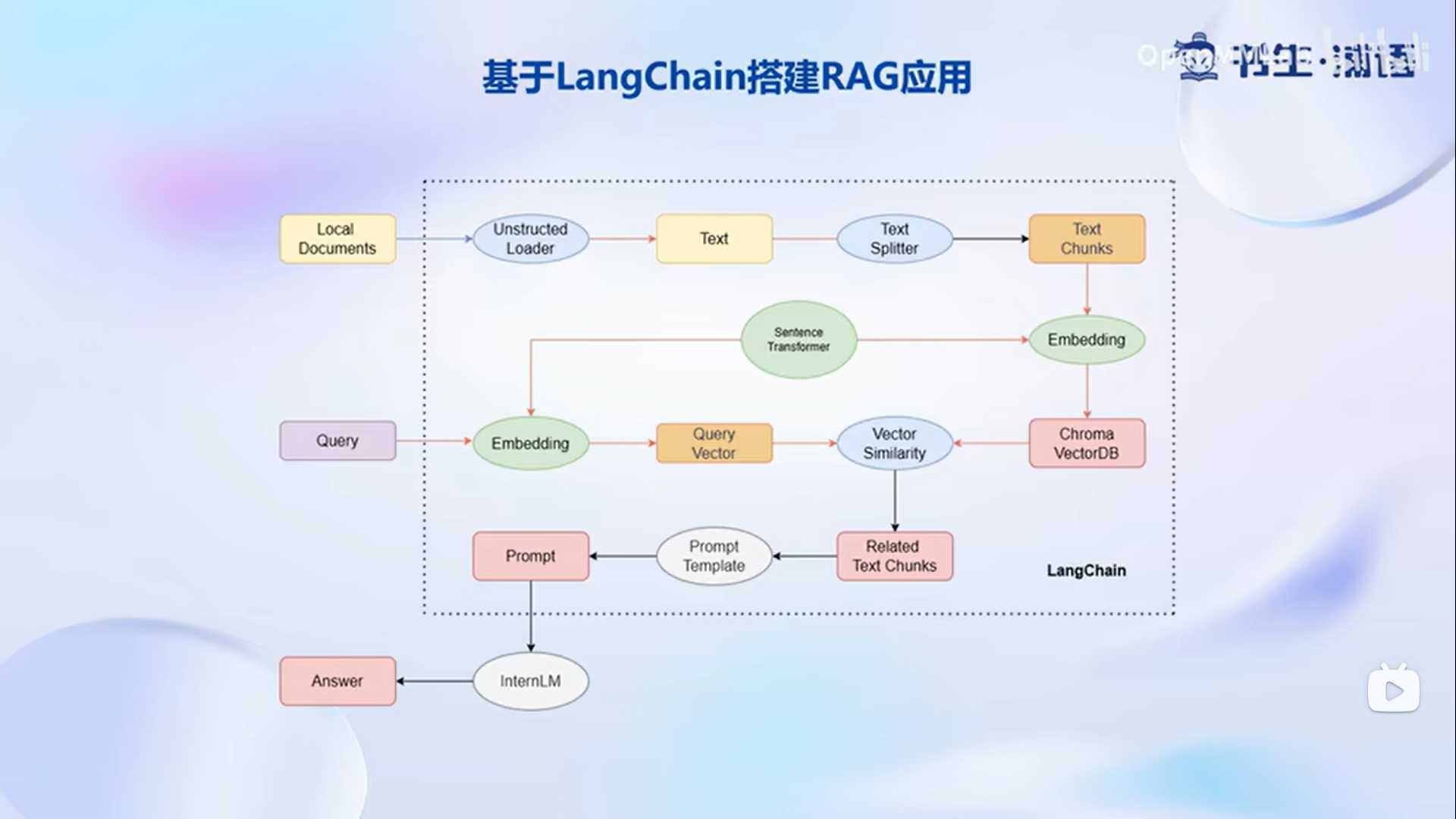
基于LangChain搭建RAG应用
我们首先需要确定原文档的类型针对不同的类型的源文件选用不同的加载器,将带格式的文本转化为无格式的字符串。然后由于大模型的输入上下文往往都是有限的,单个文档的长度往往会超过模型上下文的上限我们需要对加载的文本进行切分,将它划分到多个不同的创客
后续检索相关的Chunk来实现问答文本分割。最后为了使用向量数据库来支持语义检索也就是我们想要输入问题,检索到相关的答案。
构建向量数据库

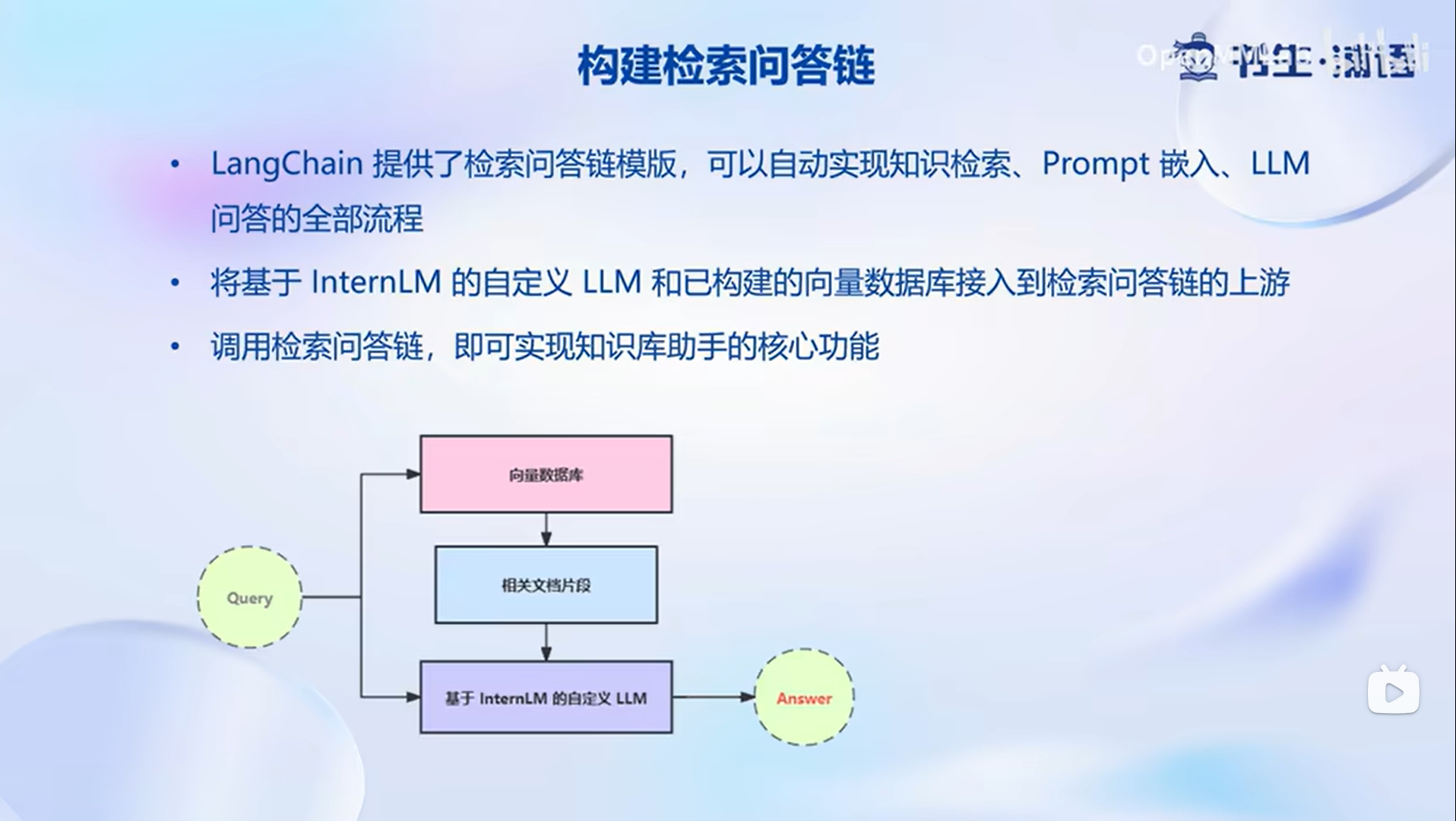
搭建知识库助手
这是一个最简单的知识库助手其问答的性能还是有所局限,基于RNG的问答系统性能核心受限于两个因素一个是检索精度,一个是prompt的性能


Web Demo部署
动手实战
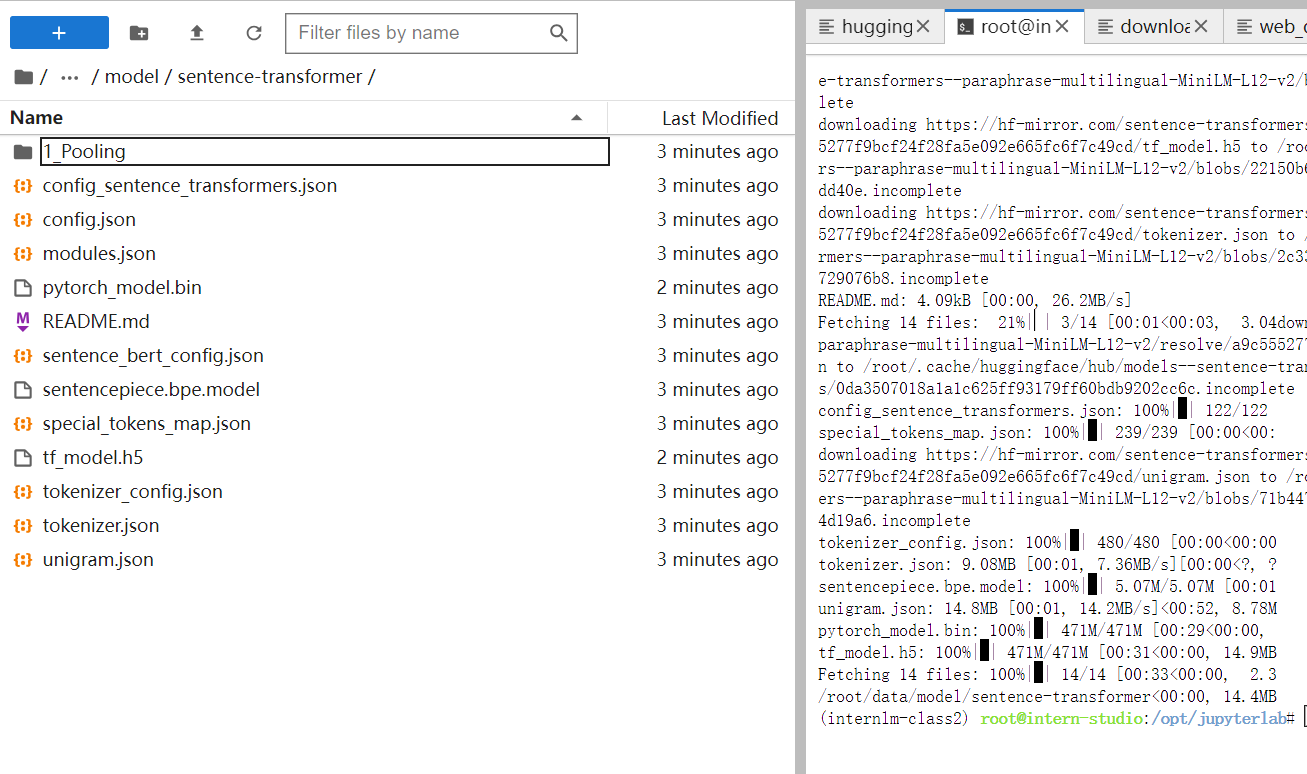
创建download_hf.py 使用 huggingface 镜像下载开源词向量模型 Sentence Transformer 。

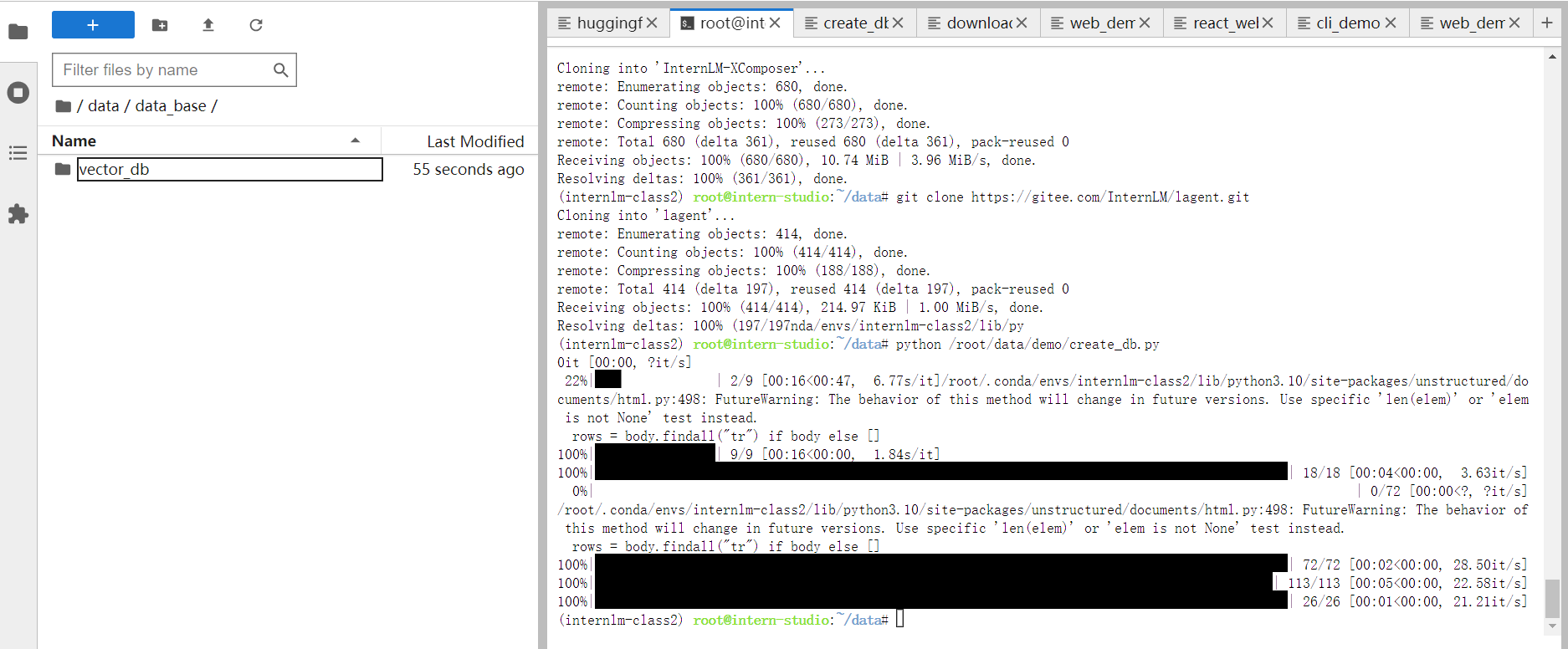
创建create_db.py文件 下载语料库:
InternLM 接入 LangChain,构建检索问答链,LangChain 通过初始化时填入已构建的数据库和自定义 LLM 作为参数,来简便地完成基于用户提问进行检索、获取相关文档、拼接为合适的 Prompt 并交给 LLM 问答的检索增强问答全部流程。将完成这些功能抽象为向量数据库加载, 实例化自定义 LLM 与 Prompt Template,构建检索问答链 的功能代码并封装为一个返回构建的检索问答链对象的函数,使得可以第一时间调用该函数得到检索问答链对象,后续直接使用该对象进行问答对话,从而避免重复加载模型。最后利用Gradio 框架将其部署到 Web 网页:
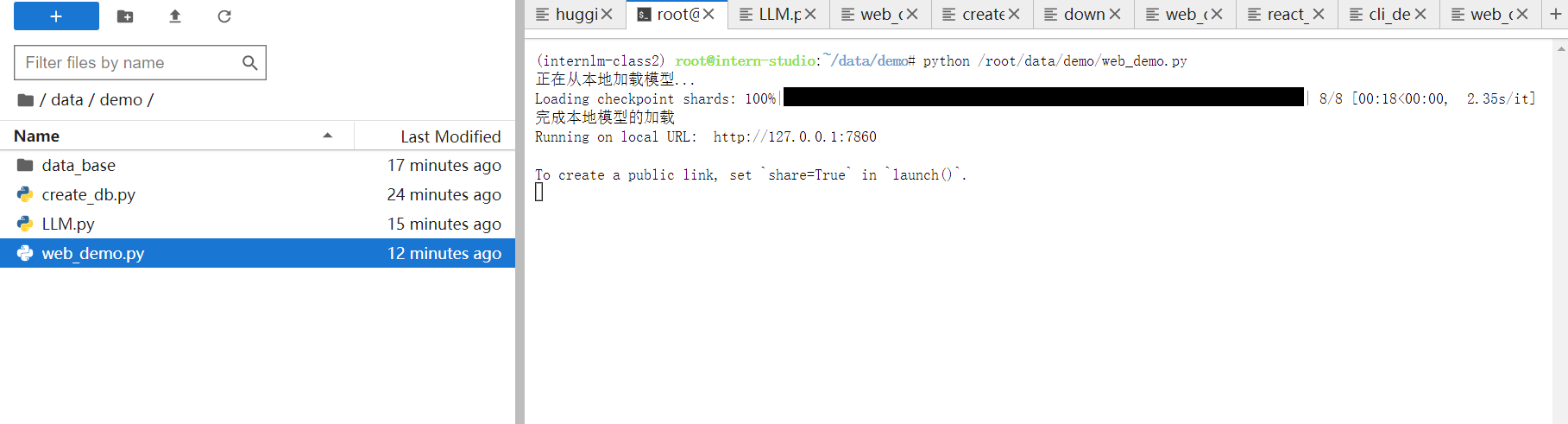
最终经过端口映射后,在本地可以使用经过检索增强问答的InternLM模型


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









