











🎉AI学习星球推荐: GoAI的学习社区 知识星球是一个致力于提供《机器学习 | 深度学习 | CV | NLP | 大模型 | 多模态 | AIGC 》各个最新AI方向综述、论文等成体系的学习资料,配有全面而有深度的专栏内容,包括不限于 前沿论文解读、资料共享、行业最新动态以、实践教程、求职相关(简历撰写技巧、面经资料与心得)多方面综合学习平台,强烈推荐AI小白及AI爱好者学习,性价比非常高!加入星球➡️点击链接
【 书生·浦语大模型实战营】学习笔记(三):“茴香豆” 搭建你的RAG 智能助理
👨💻导读: 本篇笔记内容主要分为RAG理论介绍和“茴香豆” RAG 智能助理实战。前半部分对RAG流程、向量数据库、优化等展开介绍,后半部分实战任务分为以web页面及Internlm框架进行茴香豆实战,欢迎大家交流学习!
本次作业相关资料
1.视频地址:茴香豆:搭建你的 RAG 智能助理_哔哩哔哩_bilibili
2.文档链接:Tutorial/huixiangdou/readme.md
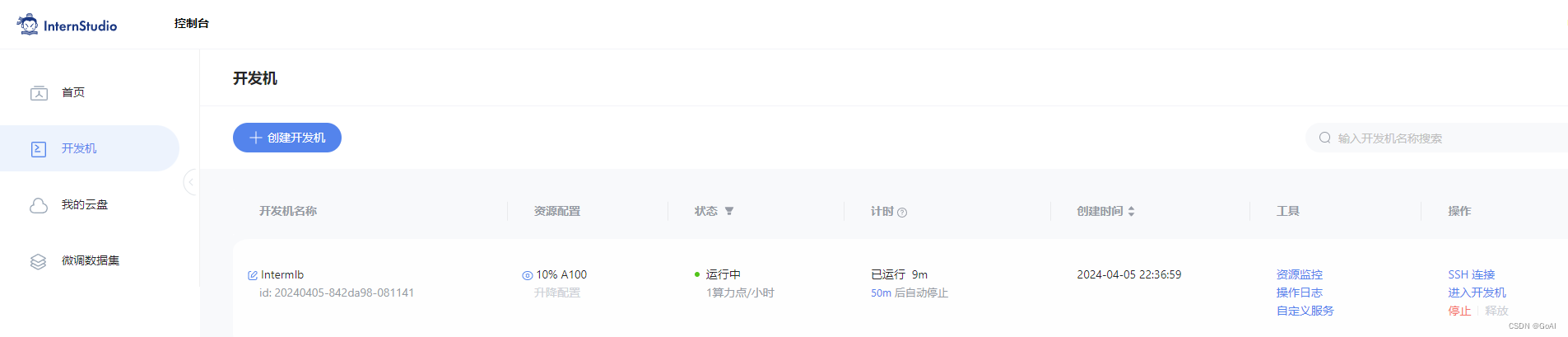
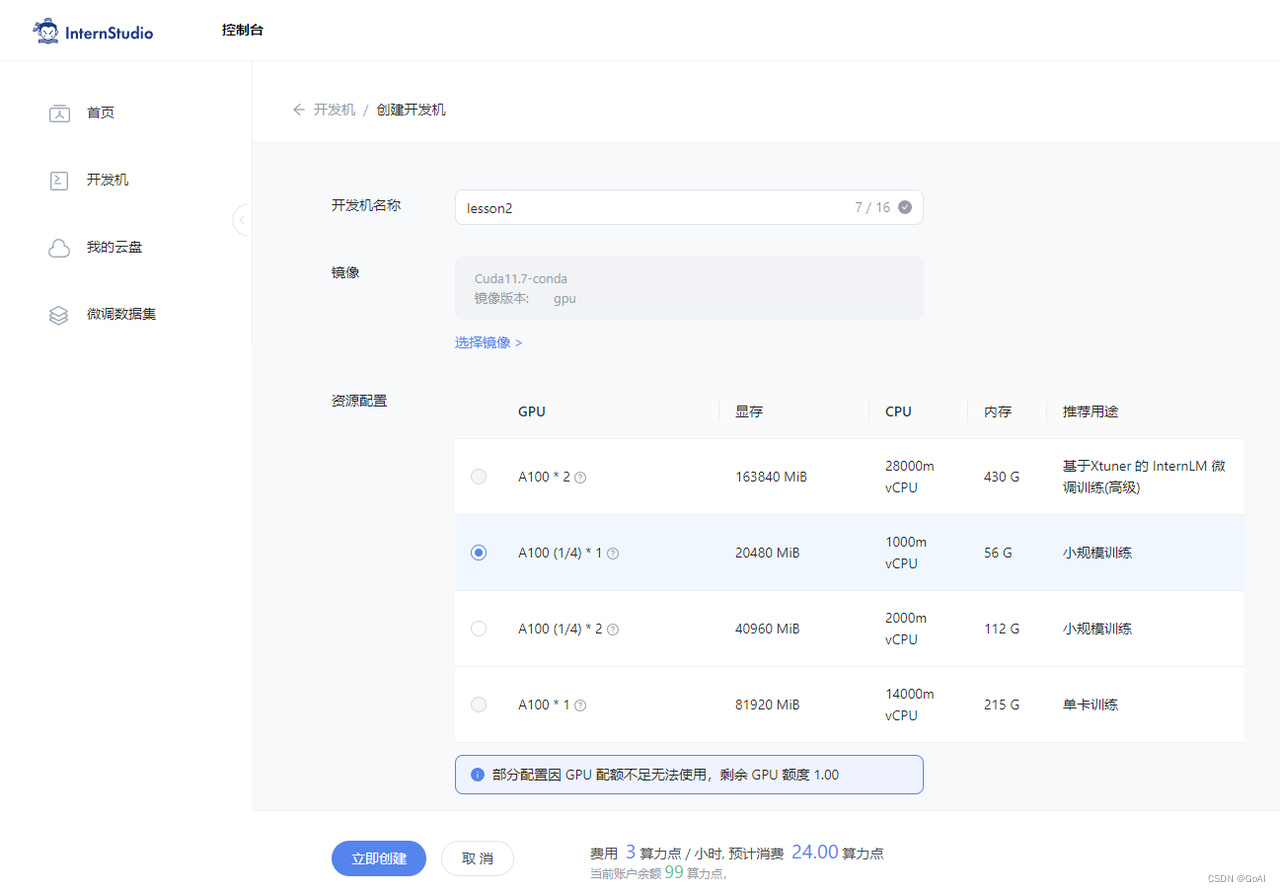
3.本次学习开发机环境:InternStudio 开发机用的30%
RAG概念
论文:《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》
一句话总结:RAG检索增强技术重点引入外部知识生成更精确回答,用于解决大模型幻觉问题,相当于人的外置大脑。
RAG简单流程:
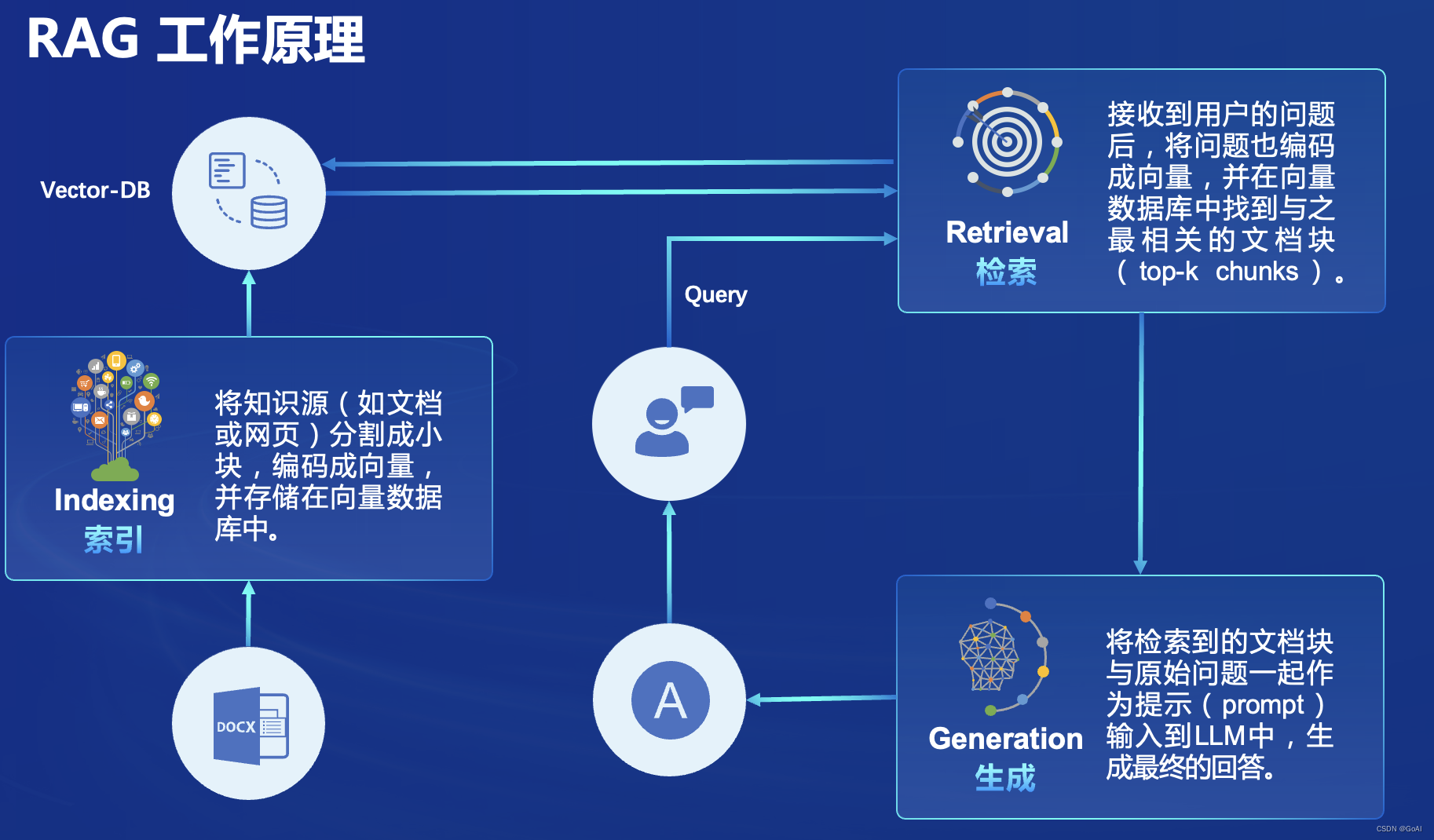
总结简单三个流程:
1.建索引
2.检索
3.生成
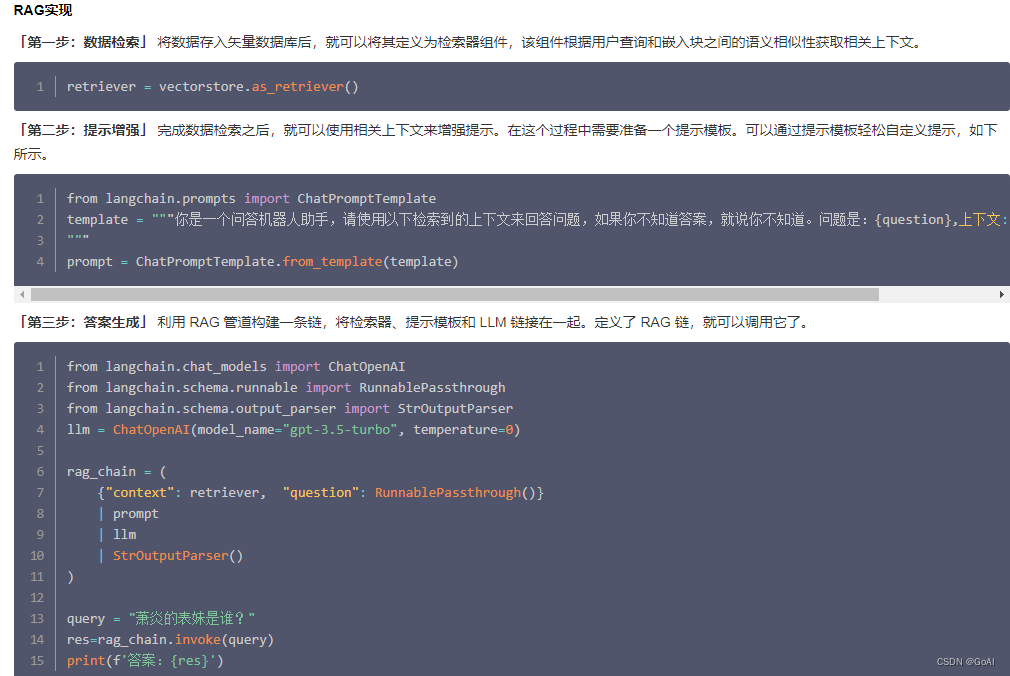
以langchain框架为例的对应上述RAG代码:
官方文章流程(详细版):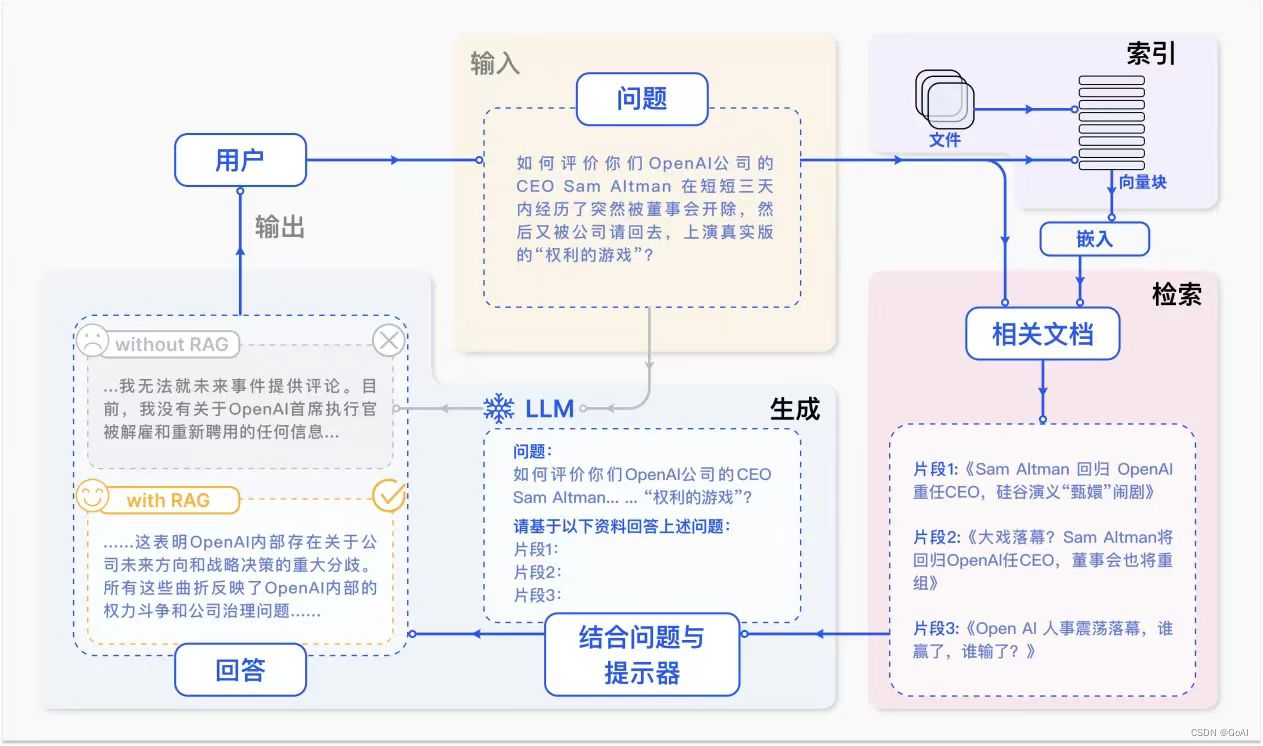
RAG流程思维导图总结:
注:下图参考网络资料,侵权联系删除
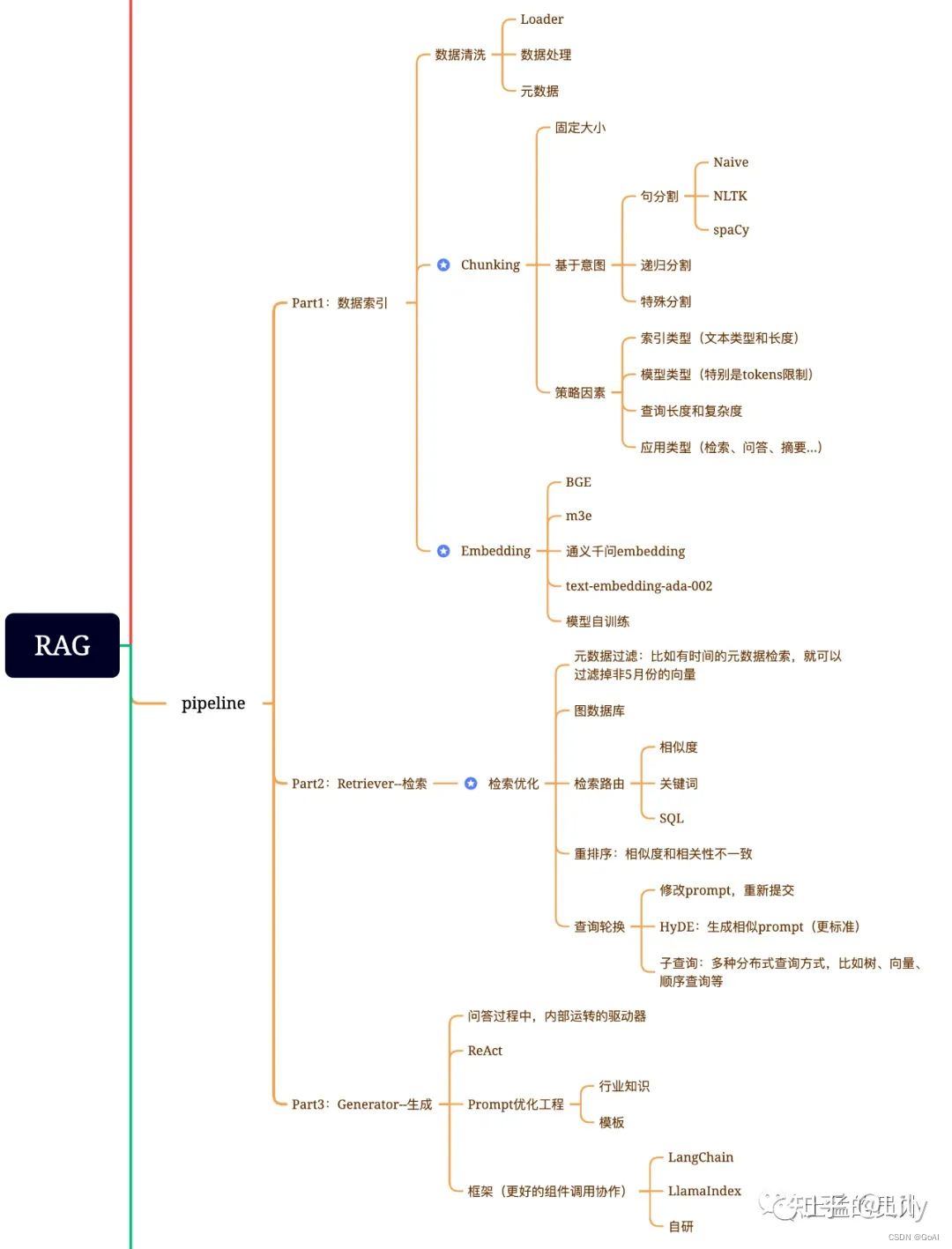
RAG的主要组成:数据提取——embedding(向量化)——创建索引——检索——自动排序(Rerank)——LLM归纳生成。
1.Indexing:清洗和提取原始数据,将各种文件格式(如 PDF、HTML、Word 和 Markdown)转换为标准化的纯文本。为适应语言模型的上下文窗口限制,需要将文本分割成更小、更易于管理的块。这些块随后通过嵌入模型转换为向量表示。最后,创建索引,将这些文本块及其向量嵌入存储为键值对,从而实现高效且可扩展的搜索功能.
2.Retrieval:在收到用户查询后,使用与索引阶段相同的嵌入模型,将查询转换为向量表示,然后计算查询向量与“索引语料库”中的向量块之间的相似性分数。系统会优先处理并检索与查询相似度最高的前个块。这些块随后被用作用户查询的上下文
3.Generation:查询和选定的文档被合成一个prompt,输入LLM生成回答。在正在进行的对话中,任何现有的对话历史记录都可以集成到prompt中,使模型能多轮对话交互
RAG形式变化:
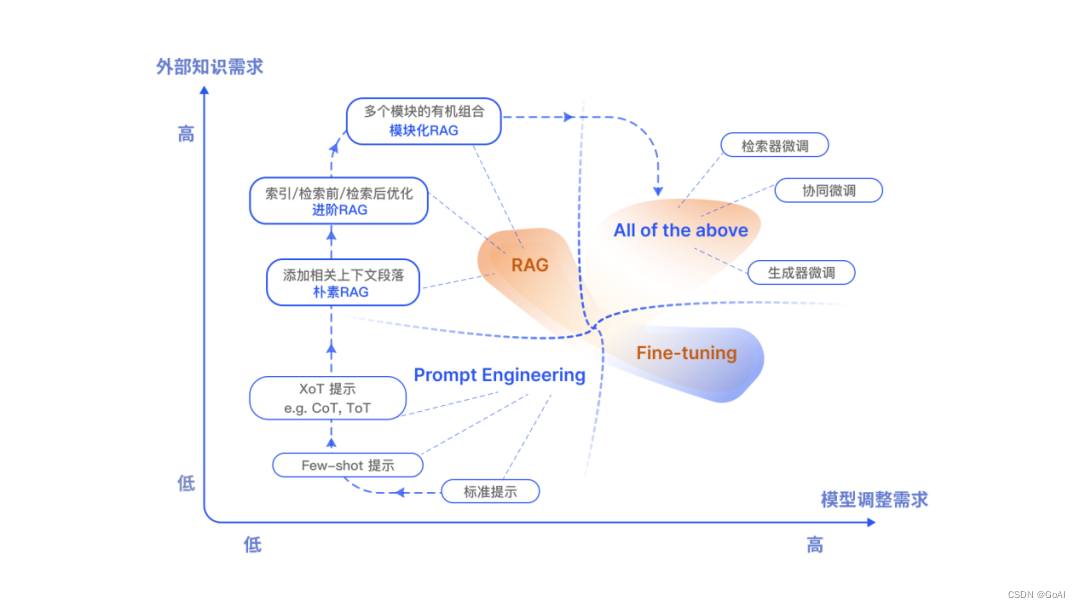
RAG和微调区别:
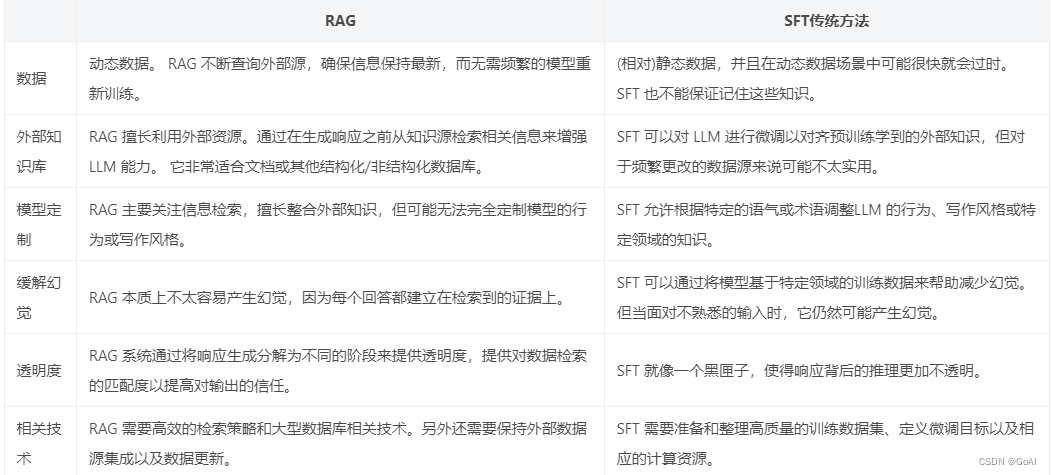
RAG评估:
RAG 三元组评估模式关注三个核心指标:答案的准确性、答案的相关性和上下文的相关性。分别是对问题的检索内容相关性、答案的基于性(即大语言模型的答案在多大程度上被提供的上下文的支持)和答案对问题的相关性。
1.答案准确性:这个指标强调模型生成的答案必须忠实于给定的上下文,确保答案与上下文信息相符,没有出入或矛盾。这一评价方面对于避免大型模型产生误导至关重要。
2.答案相关性:这个指标要求生成的答案必须直接针对所提出的问题。
3.上下文相关性:这个指标要求检索到的上下文信息必须尽可能精准和相关,避免引入无关内容。毕竟,处理长篇幅的文本对大语言模型来说是一项高成本工作,过多的无关信息会降低大语言模型处理上下文的效率。
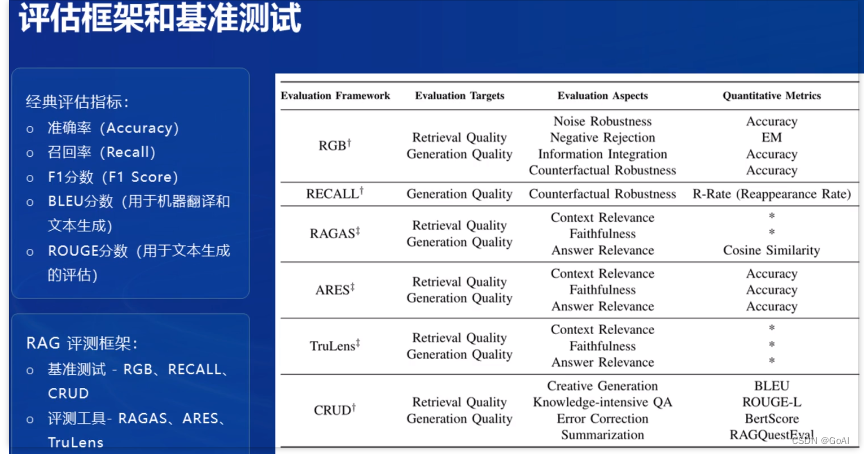
常见评估框架:
-
RGB:这一工作系统地研究了检索增强生成对大型语言模型的影响。它分析了不同大型语言模型在RAG所需的4项基本能力方面的表现,包括噪声鲁棒性、拒答、信息整合和反事实鲁棒性,并建立了检索增强生成基准。此外,现在做RAG都是做的pipeline,涉及到切块、相关性召回、拒答等多个环节,每个环节都可以单独做评测,文中提到的4个能力其实可以影射到每个环节当中。
-
RAGAS:该工作提出了一种对检索增强生成(RAG)pipeline进行无参考评估的框架。该框架考虑检索系统识别相关和重点上下文段落的能力, LLM以忠实方式利用这些段落的能力,以及生成本身的质量。目前,该方法已经开源,具体可以参见github: GitHub - exploding gradients/ragas: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines
-
Llamalindex-Evaluating :LlamaIndex提供了衡量生成结果质量的关键模块。同时,还提供关键模块来衡量检索质量。
以下为课程中的评估框架和基础测试:
RAG学习资料推荐:https://www.zhihu.com/people/zico-53-18
Task1 在茴香豆 Web 版中创建自己领域的知识问答助手
登录web网页:https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web
上传对应文档:


Task2 在 InternLM Studio 上部署茴香豆技术助手
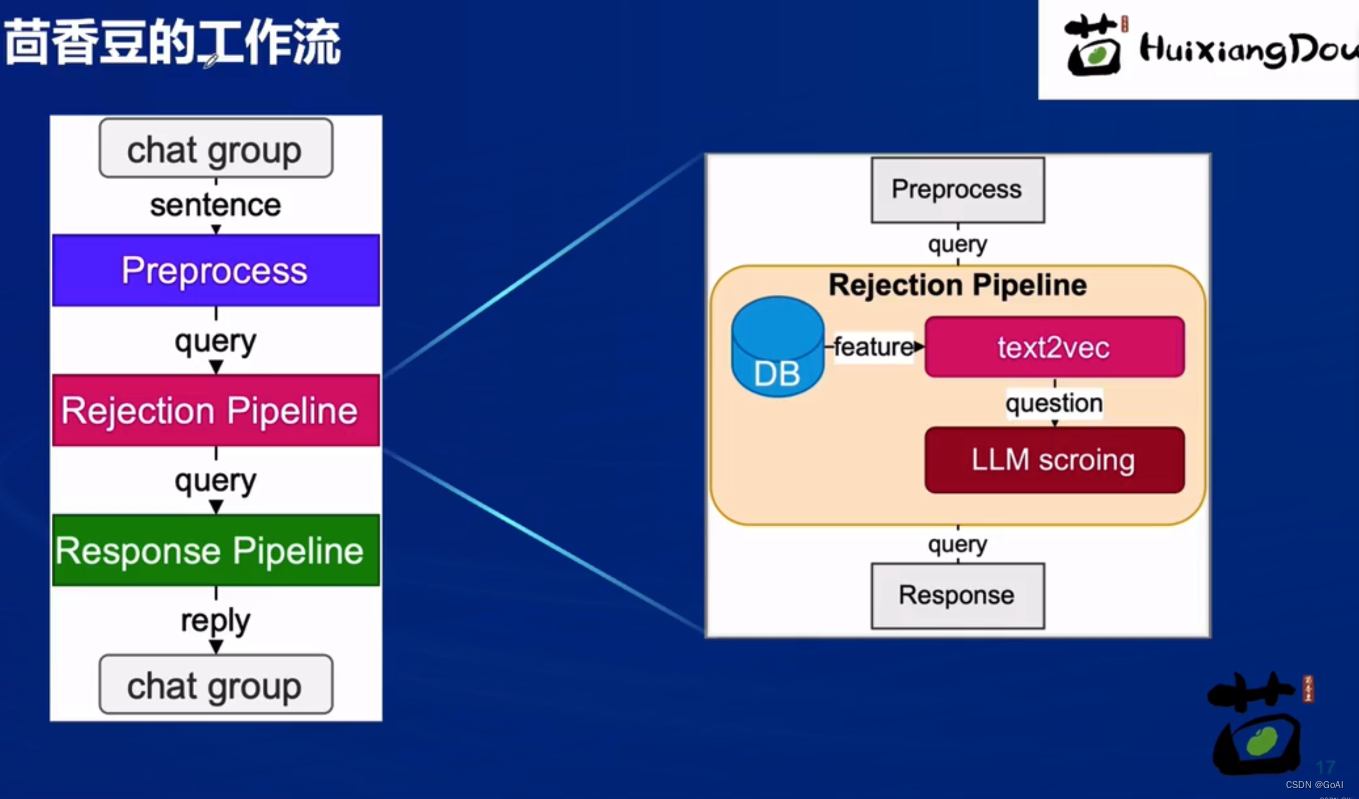
茴香豆是一个基于 LLM 的群聊知识助手,优势:
- 设计拒答、响应两阶段 pipeline 应对群聊场景,解答问题同时不会消息泛滥。精髓见技术报告
- 成本低至 1.5G 显存,无需训练适用各行业
- 提供一整套前后端 web、android、算法源码,工业级开源可商用
“茴香豆”详细介绍文档:https://github.com/InternLM/HuixiangDou/blob/main/README_zh.md
“茴香豆”工作流程:
环境搭建:进入开发机后,从官方环境复制运行 InternLM 的基础环境
studio-conda -o internlm-base -t InternLM2_Huixiangdou
激活环境:
conda activate InternLM2_Huixiangdou

下载基础文件和安装环境:
# 创建模型文件夹
cd /root && mkdir models
# 复制BCE模型
ln -s /root/share/new_models/maidalun1020/bce-embedding-base_v1 /root/models/bce-embedding-base_v1
ln -s /root/share/new_models/maidalun1020/bce-reranker-base_v1 /root/models/bce-reranker-base_v1
# 复制大模型参数(下面的模型,根据作业进度和任务进行**选择一个**就行)
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b /root/models/internlm2-chat-7b
#安装环境
pip install protobuf==4.25.3 accelerate==0.28.0 aiohttp==3.9.3 auto-gptq==0.7.1 bcembedding==0.1.3 beautifulsoup4==4.8.2 einops==0.7.0 faiss-gpu==1.7.2 langchain==0.1.14 loguru==0.7.2 lxml_html_clean==0.1.0 openai==1.16.1 openpyxl==3.1.2 pandas==2.2.1 pydantic==2.6.4 pymupdf==1.24.1 python-docx==1.1.0 pytoml==0.1.21 readability-lxml==0.8.1 redis==5.0.3 requests==2.31.0 scikit-learn==1.4.1.post1 sentence_transformers==2.2.2 textract==1.6.5 tiktoken==0.6.0 transformers==4.39.3 transformers_stream_generator==0.0.5 unstructured==0.11.2
下载茴香豆项目
cd /root
# 下载 repo
git clone https://github.com/internlm/huixiangdou && cd huixiangdou

搭建茴香豆搭建 RAG 助手
1.修改配置文件:
替换 /root/huixiangdou/config.ini 文件中的默认模型,需要修改 3 处模型地址:
#用于向量数据库和词嵌入的模型
sed -i '6s#.*#embedding_model_path = "/root/models/bce-embedding-base_v1"#' /root/huixiangdou/config.ini
#用于检索的重排序模型
sed -i '7s#.*#reranker_model_path = "/root/models/bce-reranker-base_v1"#' /root/huixiangdou/config.ini
#和本次选用的大模型
sed -i '29s#.*#local_llm_path = "/root/models/internlm2-chat-7b"#' /root/huixiangdou/config.ini
2.建知识库
使用 InternLM 的 Huixiangdou 文档作为新增知识数据检索来源。
下载预料:
cd /root/huixiangdou && mkdir repodir
git clone https://github.com/internlm/huixiangdou --depth=1 repodir/huixiangdou
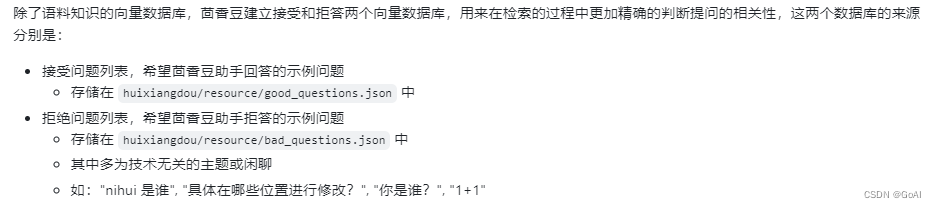
增加茴香豆相关的问题到接受问题示例:
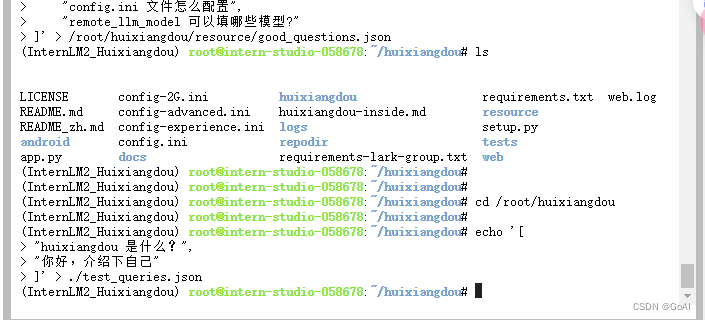
创建 RAG 检索过程的向量数据库:
# 创建向量数据库存储目录
cd /root/huixiangdou && mkdir workdir
# 分别向量化知识语料、接受问题和拒绝问题中后保存到 workdir
python3 -m huixiangdou.service.feature_store --sample ./test_queries.json
检索过程中,茴香豆会将输入问题与两个列表中的问题在向量空间进行相似性比较,判断该问题是否应该回答,避免群聊过程中的问答泛滥。确定的回答的问题会利用基础模型提取关键词,在知识库中检索 top K 相似的 chunk,综合问题和检索到的 chunk 生成答案。
3.正式运行知识助手:
测试效果
# 填入问题
sed -i '74s/.*/ queries = ["huixiangdou 是什么?", "茴香豆怎么部署到微信群", "今天天气怎么样?"]/' /root/huixiangdou/huixiangdou/main.py
# 运行茴香豆
cd /root/huixiangdou/
python3 -m huixiangdou.main --standalone

返回回答:


总结
本篇笔记内容主要分为RAG理论介绍和“茴香豆” RAG 智能助理实战。前半部分对RAG流程、向量数据库、优化等展开介绍,后半部分实战任务分为以web页面及Internlm框架进行茴香豆实战,欢迎大家交流学习!
















 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











