







一、方法概述
1、摘要
从脑电图中自动检测和分类癫痫可以极大地改善癫痫的诊断和治疗。然而,在先前的自动癫痫检测和分类研究中,有几个建模挑战仍未得到解决:(1)表示脑电图中的非欧几里得数据结构,(2)准确分类罕见的癫痫类型,以及(3)缺乏定量可解释性方法来衡量模型定位癫痫的能力。
在这项研究中,我们通过以下方式来应对这些挑战:(1)使用图神经网络(GNN)表示脑电图中的时空依赖性,并提出两种捕捉电极几何形状或动态大脑连接的脑电图图结构;(2)提出一种自监督预训练方法,预测下一时间段的预处理信号,以进一步提高模型性能,特别是在罕见的癫痫发作类型上,以及(3)提出一种定量模型可解释性方法来评估模型在脑电图中定位癫痫发作的能力。
当在大型公共数据集(5499个脑电图)上评估我们的癫痫检测和分类方法时,我们发现我们的自我监督预训练GNN在癫痫检测上达到了0.875的受试者操作特征曲线下面积,在癫痫分类上达到了0.749的加权F1分,在癫痫检测和归类方面都优于以前的方法。此外,我们的自我监督预训练策略显著改善了罕见癫痫发作类型的分类(例如,与基线相比,联合强直性癫痫发作的准确性提高了47分)。此外,定量可解释性分析表明,我们的自我监督预训练的GNN精确定位了25.4%的局灶性癫痫发作,比现有的CNN提高了21.9个百分点。最后,通过将识别的癫痫发作位置叠加在原始脑电图信号和脑电图图上,我们的方法可以为临床医生提供局部癫痫发作区域的直观可视化。
2、方法
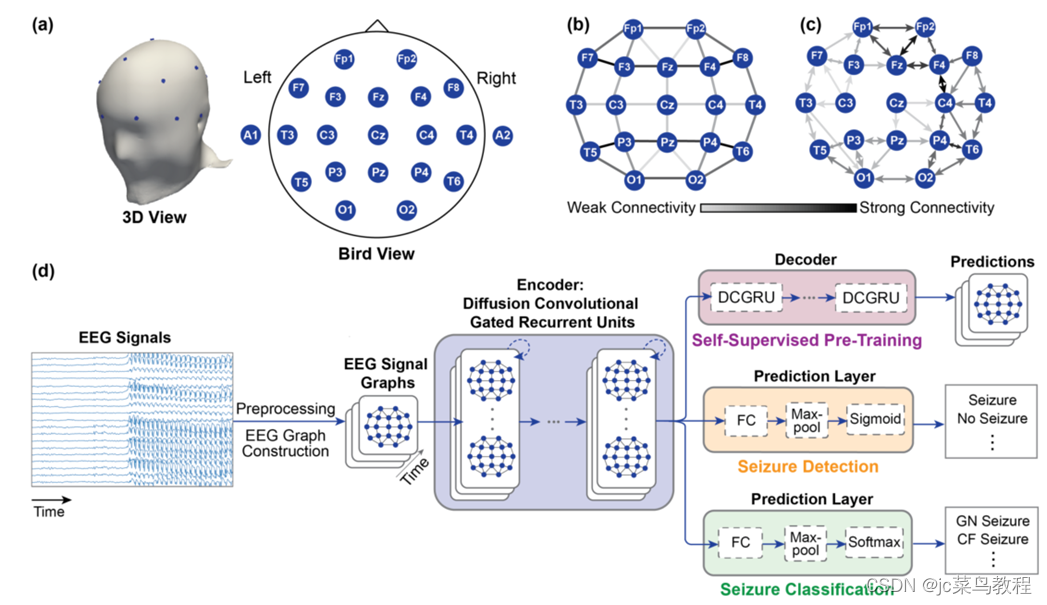
二、原始数据
Temple University Seizure Corpus (TUSZ) v1.5.2
Temple University Hospital 公开的癫痫发作EEG库,作为基础数据,是目前最大的公共EEG数据库。
其中包含5612条癫痫EEG信号,3050条注解的癫痫诊断记录,8种癫痫种类。采用的标准10-20系统,每个EEG包含19个通道(电极)。

三、数据集构建
- step 1 resampling
将Train Set分为训练和验证
首先对所有数据进行重采样,重采样至200Hz。
- 癫痫检测:使用无重叠,长为t(12s/60s)的滑动窗口从EEG信号片段中截取片段,对于癫痫的片段,设值标签y=1,对于正常的脑电片段,设值标签y=0。如果最后一个窗口短于片段长度,则忽略它。
- 癫痫分类:只采用癫痫发作的脑电图,从每个癫痫事件中获取一个12s(60s)的EEG片段,发作结束即截止,每个脑电片段就有一个对应的癫痫类型。从注释的癫痫发作时间前的2秒开始,其中2秒的偏移说明了注释中的容差。重新定义癫痫类型为四类,Label Y={1,2,3,4} 。其对应于局灶性(CF)合并癫痫发作、广义非特异性(GN)癫痫发作、缺席(AB)癫痫发作和强直性(CT)联合癫痫发作。
- 自监督预训练:使用12秒(60s)的滑动窗口获取EEG信号片段(与癫痫检测相同)。学习预测下一个时间段的EEG信号,使用真实预处理的EEG片段和预测片段(T=12s)之间的平均绝对误差作为损失函数。
For each EEG clip in each of seizure detection/seizure classification / self-supervised pretaining tasks,执行以下预处理步骤:
- step 2 滑窗
在脑电片段上滑动 t 秒窗口,不重叠,其中 t 是涉及递归层的网络的时间步长;
- step 3 FFT
使用Scipy python包中的“FFT”函数对每个 t 秒窗口应用快速傅立叶变换(fast Fourier transform,FFT)(Virtanen等人,2020b),并保留非负频率分量的对数振幅,类似于先前的研究(Asif等人,2020;Ahmedt-Aristizabal等人,2020年;Covert等人,2019)
- step 4 归一化
相对于训练数据的平均值和标准偏差对EEG片段进行z归一化(z-normalize)
归一化步骤:
1.求出各变量(指标)的算术平均值(数学期望)xi和标准差si ;
2.进行标准化处理:
zij=(xij-xi)/si
其中:zij为标准化后的变量值;xij为实际变量值。
3.将逆指标前的正负号对调。
标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。
def z_score(x, axis):
x = np.array(x).astype(float)
xr = np.rollaxis(x, axis=axis)
# 减去均值
xr -= np.mean(x, axis=axis)
# 除以标准差
xr /= np.std(x, axis=axis)
# print(x)
# 完成归一化
return x
由于癫痫发作分类的EEG片段可能由于癫痫发作时间短而具有可变的长度,因此我们将片段填充为0,以便于批量进行模型训练(facilitate model training in batches)。我们使用 t=1 秒作为时间步长的自然选择。
预处理后,每个脑电片段可以表示为 X ∈ R T × N × M X∈R^{T×N×M} X∈RT×N×M,其中T=12(或T=60)表示片段clip长度,N=19表示脑电通道/电极的数量,M=100表示上述傅立叶变换后的特征维数。
四、模型训练过程和超参数的详细信息
超参数搜索

在验证集上进行超参数搜索:
(a)initial learning rate初始学习率范围:[5e5,1e3]
(b)correlation graphs中每个节点(node)要保持的邻点数量: τ ∈ 2 , 3 , 4 \tau \in {2,3,4} τ∈2,3,4
(c)DCGRU的层数 :{2,3,4,5},隐藏单元范围:{32,64,128}
(d)最大扩散步长(max diffusion step)K∈{2,3,4}
(e) 最后一个完全连接层中的丢失概率dropout probability。
1、癫痫发作检测模型训练
undersample 使得训练集正负样本比例约为1:1
27,292 training examples for 12-s clips and 7,188 training examples for 60-s clips
损失函数:binary cross-entropy,二元交叉熵
initia learning rate : 1e-4
epoch:100
maxnum number of diffusion step:2
the dropout probability was 0 (i.e. no dropout)
该模型由两个堆叠的DCGRU层组成,具有64个隐藏单元,产生168641个距离图的可训练参数和280769个相关图的可训练参数
用于癫痫检测的模型训练对于12秒的EEG片段约20分钟,对于60秒的EEG片段约30分钟。
在验证集进行决策阈值搜索(平衡precision 和 recall scores)。决策阈值选择:in the highest F1-score on the validation set
相关指标计算:https://blog.csdn.net/q
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









