






背景:elasticsearch聚合之后进行分页是非常常见的操作
实现思路:
基于es聚合函数bucket_sort、terms和指标聚合cardinality实现
实现方式:(以会员编码分组分页展示会员最近一条时间记录排序为例):
1、查询实现
// 桶排序聚合
BucketSortPipelineAggregationBuilder bucketSortAggregation = PipelineAggregatorBuilders.bucketSort(
"sortCustomer", Lists.emptyList()).from((pageNo.intValue() - 1) * pageSize.intValue()).size(pageSize.intValue());
//分页指标--用于统计分页total总数
CardinalityAggregationBuilder cardinalityAggregation = AggregationBuilders.cardinality("custCard").field("customer_no.keyword");
//返回字段取最新一条记录
TopHitsAggregationBuilder topHitsAggregation = AggregationBuilders.topHits("latestCust")
.fetchSource(new String[]{"customer_no", "customer_name", "identify_no", "visit_time", "service_item_names", "organization_name", "id", "type"} , null).size(1) .sort("visit_time_long", SortOrder.DESC);
//以会员编码分组
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("topCustomer").field("customer_no.keyword")
.size(pageNo.intValue() * pageSize.intValue())
.subAggregation(bucketSortAggregation)
.subAggregation(topHitsAggregation);
//es查询 分页指标和分组terms要同级
//hit查询返回0条数据
searchSourceBuilder.size(0);
searchSourceBuilder.from(0);
//排序
searchRequest.source(searchSourceBuilder.sort("visit_time_long", SortOrder.DESC));
//query条件--正常查询条件
searchRequest.source(searchSourceBuilder.query(boolBuilder));
//聚合条件 分组+分页指标 searchRequest.source(searchSourceBuilder.aggregation(termsAggregationBuilder));
searchRequest.source(searchSourceBuilder.aggregation(cardinalityAggregation));2、es语句
GET /xxxxx/_search
{
"from": 0,
"size": 0,
"query": {
"bool": {
"must": [
{
"term": {
"del_flag": {
"value": false,
"boost": 1
}
}
}
],
"adjust_pure_negative": true,
"boost": 1
}
},
"sort": [
{
"visit_time_long": {
"order": "desc"
}
}
],
"aggregations": {
"topCustomer": {
"terms": {
"field": "customer_no.keyword",
"size": 5,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_key": "asc"
}
]
},
"aggregations": {
"latestCust": {
"top_hits": {
"from": 0,
"size": 1,
"version": false,
"seq_no_primary_term": false,
"explain": false,
"_source": {
"includes": [
"customer_no",
"customer_name",
"identify_no",
"visit_time",
"service_item_names",
"id",
"type"
],
"excludes": []
},
"sort": [
{
"visit_time_long": {
"order": "desc"
}
}
]
}
},
"sortCustomer": {
"bucket_sort": {
"sort": [],
"from": 0,
"size": 5,
"gap_policy": "SKIP"
}
}
}
},
"custCard": {
"cardinality": {
"field": "customer_no.keyword"
}
}
}
}es查询结果:

3、java获取结果
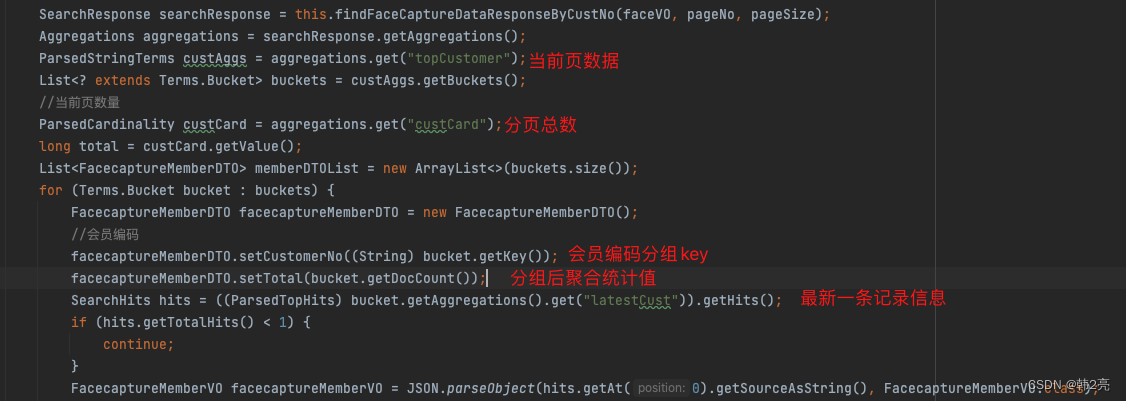
最终实现分组分页排序功能
参考:Bucket aggregations | Elasticsearch Guide [8.4] | Elastic















 7034
7034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









