







LRU缓存是前端面试中常考的手撕题,能较全面的考察面试者的综合素质。
它的整体实现逻辑不复杂,但是要拿满分的话也没那么容易。
说实话,在碰到面试官给我出这道题时,心里还开心了一下,因为之前做过,因此很快就按照记忆里的解题思路实现了一下代码。
结果没想到,我以为的标准答案,只能算是及格…还有很多可优化的空间!
本文会介绍及格&满分两种解法,大家可以看看自己的解法能不能拿满分:
题目描述:
请你设计并实现一个满足 LRU (最近最少使用) 缓存约束的数据结构。 实现 LRUCache方法: LRUCache(capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存。使用get(key)方法来获取对应的value, 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。 使用put(key, value)方法来添加新的记录到缓存中, 如果关键字 key 已经存在,则变更其数据值 value;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该逐出最久未使用的关键字。 函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
代码初始结构:
const LRUCache = function (capacity) {
}
LRUCache.prototype.get = function (key) {
}
LRUCache5.prototype.put = function (key, value) {
}
及格解法:
由题目中的提示信息:
1.key & value
2.函数 get 和 put 必须以O(1)的平均时间复杂度运行。
很容易想到的是利用哈希Map来解这道题,哈希Map的存取时间都是O(1)。
解题思路如下:
1.对于get方法:
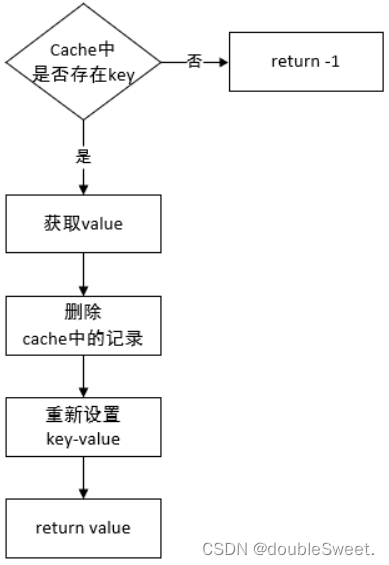
为了保证最新读取的元素的优先级最高&最近最久未使用的元素优先级最低。如果缓存cache中存在要读取的key,我们需要先将cache中的记录删除,然后重新添加key-value,从而保证读取到的值在cache中的优先级最高。
对应的代码为:
LRUCache.prototype.get = function (key) {
if (!this.cache.has(key)) {
return -1;
}
let value = this.cache.get(key);
this.cache.delete(key);
this.cache.set(key, value);
return value;
}
2.对于put方法:
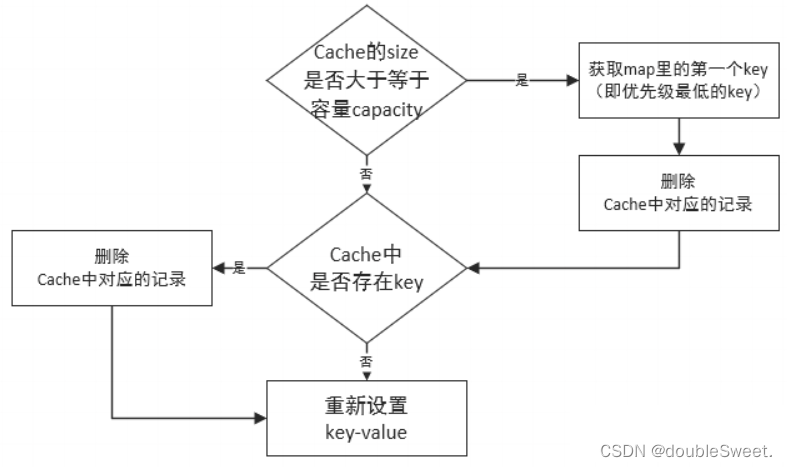
在向cache中添加key-value之前,我们需要判断缓存的size是否大于等于容量。如果是,需要先把优先级最低的元素移出缓存;然后判断要添加的key-value是否在cache中存在,如果存在,为了保证当前添加的元素的优先级最高,需要先把cache中的这条记录删除,然后再把要put的key-value添加进去。
对应的代码为:
LRUCache.prototype.put = function (key, value) {
if (this.cache.size >= this.capacity) {
let key = this.cache.keys().next().value;//获取cache中的第一个key
this.cache.delete(key);
}
if (this.cache.has(key)) {
this.cache.delete(key);
}
this.cache.set(key, value);
}
完整代码如下所示:
// ES5写法
const LRUCache5 = function (capacity) {
this.capacity = capacity;
this.cache = new Map();
}
LRUCache5.prototype.get = function (key) {
if (!this.cache.has(key)) {
return -1;
}
let value = this.cache.get(key);
this.cache.delete(key);
this.cache.set(key, value);
return value;
}
LRUCache5.prototype.put = function (key, value) {
if (this.cache.size >= this.capacity) {
let key = this.cache.keys().next().value;
this.cache.delete(key);
}
if (this.cache.has(key)) {
this.cache.delete(key);
}
this.cache.set(key, value);
}
LRUCache5.prototype.toString = function () {
console.log('capacity', this.capacity);
console.table(this.cache);
}
const lruCache = new LRUCache5(2);
lruCache.put(1, 'first');
lruCache.put(2, 'second');
lruCache.get(1);
lruCache.toString()
lruCache.put(3, 'third');
lruCache.toString();
// ES6写法
class LRUCache6 {
constructor(capacity) {
this.capacity = capacity;
this.cache = new Map();
}
get(key) {
if (!this.cache.has(key)) {
return -1;
}
let value = this.cache.get(key);
this.cache.delete(key);
this.cache.set(key, value);
}
put(key, value) {
if (this.cache.has(key)) {
this.cache.delete(key);
}
if (this.cache.size >= this.capacity) {
let key = this.cache.keys().next().value;
this.cache.delete(key);
}
this.cache.set(key, value);
}
toString() {
console.log('capacity', this.capacity);
console.table(this.cache);
}
}
const lruCache6 = new LRUCache6(2);
lruCache6.put(1, 'first');
lruCache6.put(2, 'second');
lruCache6.get(1);
lruCache6.toString()
lruCache6.put(3, 'third');
lruCache6.toString();
有木有同学和我一样,第一反应想到的解决方案是上面这种。使用map来进行set和get操作相比于其他方式来说,在时间复杂度上已经优化了很多,但是对于delete操作,只有通过遍历整个Map,才能获取要删除的元素。因此delete方法的时间复杂度并不是O(1)。这里就是我们可以优化的点。
那有没有一种数据结构,可以使delete操作的时间复杂度也是O(1)呢?
答案就是:链表!
满分解法:
为什么链表删除一个元素只需要O(1)的时间复杂度呢?
假设cache中的元素为1,2,3,4,5。我们想要删除3号元素,使用链表来删除的过程如下图所示:
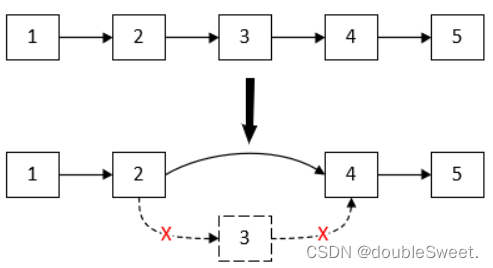
只需要修改2号节点的next指向为4号节点即可删除3号节点。
(不得不说,链表这种数据结构真的太神奇了!!!)
因此,LRU缓存算法的满分解法应该是Map+链表。
考虑到在链表中执行 put 操作和delete 操作需要知道待插入节点的前驱节点和后继节点,如果使用单向链表的话,需要进行一次遍历,才能找到前驱和后继,这样就违背了O(1)时间复杂度的初衷,因此,我们应采用双向链表的方式来标记每个节点的信息,这样就可以通过prev指针很方便的找到前驱节点,通过next指针很方便的找到后继节点啦:

整理一下使用Map和链表来实现LRU缓存的思路:
1.使用Map作为Cache缓存区,Map的key为传入的key,value为双向链表中的节点。
2.双向链表中的节点包含四个属性:
key(节点的键)value(节点的值)next(指向下一个节点)prev(指向前一个节点)
3.当执行get操作时,需要先判断Map中是否存在对应的key:
- 如果不存在,直接
return -1; - 如果存在,就要先在
Map和链表里删除当前节点,然后把当前节点添加至头节点后边&Map的尾部(Map里越往后优先级越高),然后返回节点的value值;
4.当执行put操作时,需要先判断Map中是否存在要put的key:
- 如果已存在该
key,为了保证优先级,需要在Map和链表中都先删除当前节点,然后添加当前节点至链表头节点之后&Map的尾部; - 如果不存在该
key,则需要根据Map的size和容量capacity的大小关系分别处理:- 如果
Map的size大于等于capacity,则需要删除链表除尾结点的最后一个节点&Map的第一个元素,然后添加新节点至头节点之后&Map的尾部; - 如果
Map的size小于capacity,直接添加新节点至头节点之后&Map的尾部;
- 如果
整体逻辑和只采用Map的版本差不多。
但是对于value的赋值,引入了双向链表来优化处理速度。
至此,我们可以总结一下,在双向链表上,需要进行哪些操作:
1.首先需要定义一下双向链表中每个节点所拥有的属性:
const linkListNode = function (key = "", val = "") {
this.key = key;
this.val = val;
this.pre = null;
this.next = null;
}
2.设置链表初始状态下的节点及它们之间的指向(生成头节点和尾节点):
初始情况下,头节点head的next直接指向tail;尾结点tail的pre直接指向head。链表中只存在这两个节点。
const linkList = function () {
let head = new linkListNode("head", "head");
let tail = new linkListNode("tail", "tail");
head.next = tail;
tail.pre = head;
this.head = head;
this.tail = tail;
}
3.定义链表的添加操作
当我们需要向链表中添加元素时,会直接添加到头节点的下一个位置处。 步骤为:
- 给
node的pre和next属性赋值; - 修改链表头节点原本下一个节点的
pre为当前node; - 修改链表头节点的
next为当前node;
tips: 为了保证前一步的操作不会影响后一步,操作链表的顺序应该是从后往前。因此先修改pre,再修改next。
// 链表头节点添加,每次有新元素的时候就添加在头节点处,因此链表元素越靠前,说明元素等级越高
linkList.prototype.append = function (node) {
node.next = this.head.next;
node.pre = this.head;
this.head.next.pre = node;
this.head.next = node;
}
4.删除指定链表元素
删除指定链表元素只需要如下两步:
- 修改待删除节点的上一个节点的
next指向 - 修改待删除节点的下一个节点的
pre指向
linkList.prototype.delete = function (node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
5.删除链表中除尾节点之外的最后一个节点:(优先级最低的节点,容量不足时使用)
头节点的作用是便于插入新元素,尾节点的作用是便于删除优先级最低的元素。
具体步骤是:
- 根据尾节点,找到尾节点的前一个节点。该节点就是待删除的优先级最低的元素
- 修改待删除节点的前一个节点的
next指向为尾节点(tail) - 修改尾节点(
tail)的pre指向为待删除节点的前一个节点
删除优先级最低的节点就体现出双向链表的好处啦!
linkList.prototype.pop = function () {
let node = this.tail.pre;
node.pre.next = this.tail;
this.tail.pre = node.pre;
return node;
}
6.重写console方法来打印链表,查看链表的实时状态:
linkList.prototype.linkConsole = function (key = '1') {
let h = this.head;
let res = "";
while (h) {
if (res != "") {
res += "-->";
res += h[key];
h = h.next;
}
}
console.log(res);
}
定义好链表的相关操作方法后,我们就可以使用Map+linkList来完成LRU缓存算法啦:
1.定义LRUCache数据结构
// LRUCache数据结构
// capacity保存最大容量,kvMap保存节点信息,linkList为节点的顺序链表
const LRUCache = function (capacity) {
this.capacity = capacity;
this.kvMap = new Map();
this.linkList = new linkList();
}
2.编写get方法
// 如果关键字key存在于缓存中,则返回关键字的值,并重置节点链表顺序,将该节点移到头结点之后,否则,返回-1
LRUCache.prototype.get = function (key) {
if (!this.kvMap.has(key)) {
return -1;
}
let node = this.kvMap.get(key);
this.linkList.delete(node);
this.linkList.append(node);
return node.val;
}
3.编写put方法
LRUCache.prototype.put = function (key, value) {
if (this.kvMap.has(key)) {
let node = this.kvMap.get(key);
node.val = value;
this.linkList.delete(node);
this.linkList.append(node);
} else {
let node = new linkListNode(key, value);
if (this.capacity === this.kvMap.size) {
let nodeP = this.linkList.pop();
this.kvMap.delete(nodeP.key);
}
this.kvMap.set(key, node);
this.linkList.append(node);
}
}
完整代码如下:
const linkListNode = function (key = "", val = "") {
this.val = val;
this.key = key;
this.pre = null;
this.next = null;
}
// 设置链表初始状态下节点及它们之间的指向,(生成头节点和尾结点)
const linkList = function () {
let head = new linkListNode("head", "head");
let tail = new linkListNode("tail", "tail");
head.next = tail;
tail.pre = head;
this.head = head;
this.tail = tail;
}
// 链表头节点添加,每次有新元素的时候就添加在头节点处,因此链表元素越靠前,说明元素等级越高
linkList.prototype.append = function (node) {
node.next = this.head.next;
node.pre = this.head;
this.head.next.pre = node;
this.head.next = node;
}
// 链表删除指定节点
linkList.prototype.delete = function (node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
// 删除并返回链表的最后一个节点(非tail)
// 取到链表的最后一个节点(非tail节点),删除该节点并返回节点信息
linkList.prototype.pop = function () {
let node = this.tail.pre;
node.pre.next = this.tail;
this.tail.pre = node.pre;
return node;
}
// 打印链表信息
// 将链表的信息按顺序打印出来,入参为需要打印的属性
linkList.prototype.linkConsole = function (key = 'val') {
let h = this.head;
let res = "";
while (h) {
if (res != "") {
res += "-->";
res += h[key];
h = h.next;
}
}
console.log(res);
}
// LRUCache数据结构
// capacity保存最大容量,kvMap保存节点信息,linkList为节点的顺序链表
const LRUCache = function (capacity) {
this.capacity = capacity;
this.kvMap = new Map();
this.linkList = new linkList();
}
// put方法
// 如果关键字key已经存在,则变更其数据值value,并重置节点链表顺序,将该节点移到头节点之后;如果不存在,则向缓存中插入该组key-value。
// 如果插入操作导致关键字数量超过capacity,则应该踢掉最久未使用的关键字。
LRUCache.prototype.put = function (key, value) {
if (this.kvMap.has(key)) {
let node = this.kvMap.get(key);
node.val = value;
this.linkList.delete(node);
this.linkList.append(node);
} else {
let node = new linkListNode(key, value);
if (this.capacity === this.kvMap.size) {
let nodeP = this.linkList.pop();
this.kvMap.delete(nodeP.key);
}
this.kvMap.set(key, node);
this.linkList.append(node);
}
}
// get方法
// 如果关键字key存在于缓存中,则返回关键字的值,并重置节点链表顺序,将该节点移到头结点之后,否则,返回-1
LRUCache.prototype.get = function (key) {
if (!this.kvMap.has(key)) {
return -1;
}
let node = this.kvMap.get(key);
this.linkList.delete(node);
this.linkList.append(node);
return node.val;
}
测试:
const obj = new LRUCache(2);
obj.put(1, 1);// 1
obj.put(2, 2);// 2 -> 1
console.log(obj.get(1)); // 1 -> 2
obj.put(3, 3);// 3 -> 1
console.log(obj.get(2));// 此时缓存里没有2的位置了,因此会返回-1
obj.put(4, 4);// 4 -> 3
console.log(obj.get(1));// 此时缓存里没有1的位置了,因此会返回-1
console.log(obj.get(3));// 3 -> 4
console.log(obj.get(4));// 4 -> 3
LRU缓存应用场景
LRU缓存算法其实是操作系统中很常见的缓存淘汰算法。除了LRU(最近最久未使用)淘汰算法之外,还有FIFO(先进先出)淘汰算法、LSU(最近最少使用)淘汰算法和MRU(最近最常使用)淘汰算法。
就前端领域而言,LRU缓存淘汰算法,常用于浏览器缓存中。
所谓浏览器缓存,指的是当浏览器端向服务器发送资源请求之前,会先看浏览器本地是否存在待访问资源,如果存在的话,就直接使用缓存,否则再去向服务器请求新资源。
因为浏览器的缓存区大小也是有限的,使用缓存淘汰算法可以使得缓存访问和管理更高效。
除了上述应用场景外,缓存淘汰算法的常用应用场景还有:
浏览器的历史浏览记录vue中的keep-aliveredis缓存数据库
…
















 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











