






在读
A Quantitative Method to Evaluate the Performance of Climate Models in Simulating Global Tropical Cyclones
一文的时候,文中提到的Evaluation Index for Geographical Properties of the TC Track内容没有很详细的说明如何去进行聚类分析,只是提及用k-means聚类分析以经把不同的TC track分成几个clusters之后用silhouette coeffificient(剪影系数?)来筛选所要用的k值为多少最合理,至于针对TC用的k-means聚类分析,文章直接把锅甩给 Classifying North Atlantic Tropical Cyclone Tracks by Mass Moments 一文,才知道先得计算每个TC track的质心经纬度,以及路径的经向纬向和对角线方向的方差(这五个要素便能描述一个椭圆路径的特征)公式如下
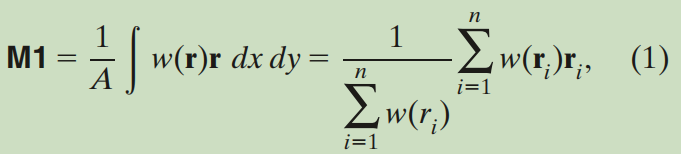
ri是一个TC在第i个时刻的位置(lon,lat)w(ri)为权重系数,得到的M1是TC路径质心的经纬度
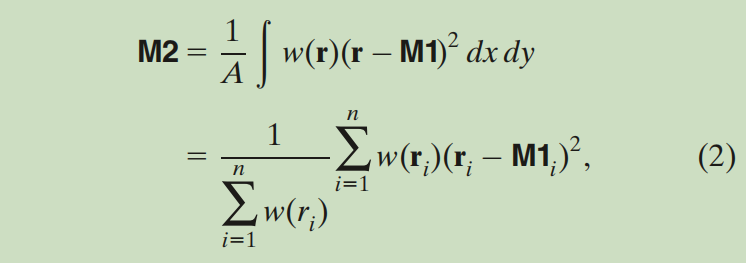
M2得到的是(x方向的方差,y方向的方差,xy的协方差),这个公式一开始我没看懂,看起来就像在算TC各位置到质心的方差,后来在网上看到以下解释才搞清楚

图片来自https://cloud.tencent.com/developer/article/2162877,感谢大佬的文章让我恍然大悟。
在python程序中,直接使用模块
from sklearn.cluster import KMeans把n个TC路径的[经度,纬度,经度方差,纬度方差,经纬度协方差]放进 nX5的矩阵中(假设这个矩阵的变量名叫track_paras)
k=2 #k是代表一共输出几个聚类
kmeans=KMeans(n_clusters=k, random_state=0)
cluster_list=kmeans.fit_predict(tracks_para)
print(kmeans.labels_)#kmeans.labels_输出的是矩阵中每个TC路径数据所在的聚类编号
print(cluster_list)#输出结果其实和kmeans.labels_一样,只是kmeans.fit_predict(tracks_para)把值赋给了cluster_list
print(tracks_para[np.array(kmeans.labels_)==0])#这样可以输出聚类编号为0的路径的[经度,纬度,经度方差,纬度方差,经纬度协方差]信息聚类分析中对聚类数k的选定尤为重要,少了多了都可能反映不了分布特点,所以引入一个剪影系数(
silhouette coefficient)

一个聚类的S平均值越大,且S为负数的点数量越少,代表k值选的越好。
在python中使用一下两个模块
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples silhouette_vals=silhouette_samples(tracks_para,cluster_list,metric='euclidean')silhouette_vals得到的便是每个TC路径的S值,对其进行平均和找出S为负数的TC路径数量,由k=2开始画S平均值和负数数量与k的关系图可找到最适合的k值。
以ibtracs记录的2000-2014年西北太平洋TC为例,处理每个TC路径的[经度,纬度,经度方差,纬度方差,经纬度协方差]数据得到S平均值和负数数量与k的关系图

可以看出k=2得到的结果比较理想,则用k=2对西北太平洋TC进行聚类分析,得到
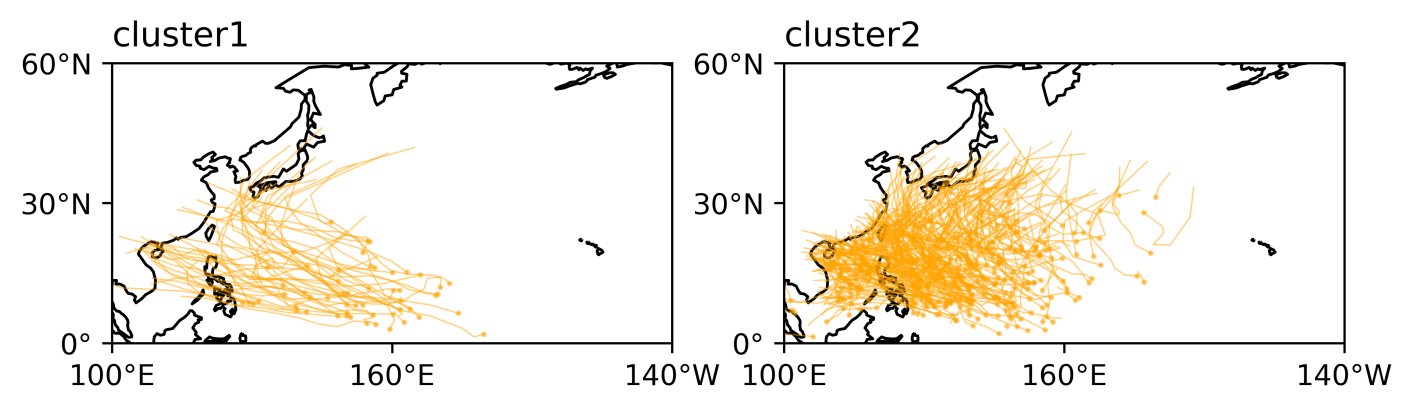















 614
614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









