







0、引言
在数据库的设计与优化过程中,除了最长使用的B+树外,还有一些其他的索引结构,适用于一些特殊的场景。本文将介绍另外两种稍微常见的索引结构,即位图索引和倒排索引。
1、回看B+树
如同之前的文章中已经提到过的,B+树在数据库中最常用的索引结构。主流的数据库,如MySQL的InnoDB存储引擎、Oracle等,都是使用B+树,用以实现聚簇索引和辅助索引。
但是,B+树索引,也有一些使用的局限。
一方面,B+树索引在提高检索速度的同时,增加了数据增删改的操作成本,可以说是在数据的读与写之间做了一个相对平衡的选择。
另一反面,数据库的优化器在多个备选的B+树索引之间,只能选择其一(当然,回表的操作不算),涉及到多个索引条件同时在查询中出现的复合查询场景中,仍有一定的提升空间。
2、位图索引
针对B+树使用的两个局限,第一个局限可以说是索引设计上的通病,没法很好地规避。但是,在复合查询场景中,被迫做选择的无奈,位图索引可以很好地满足成年人的人性,“成年人不做选择,我全都要”。
构建流程
位图索引是M*N的位图(矩阵)的数据结构。以一个简单的位图索引示例来解释下位图索引的结构:
假如有一张人学生信息表t_student,表中存储了学生的身高、体重,分别用字段height、weight存储,假设均为整型字段。
现在我们为字段height构建一个位图索引,假设身高取值为81-200cm之间,则height字段共用120个不同的取值,则M为120,我们接下来需要构建120个位向量,每个向量的位数为N,N为表中记录的行数,也就是有多少学生,就有多少位。我们假设总共有1000名学生,则N为1000。
现在,我们有了120*1000的矩阵,也就是120个长度为1000的位向量。其中,位向量的每一位都可以是0或者1,现在我们为表中的每一行学生信息进行编号,从0-999,则对应的每一个位向量中的第i位是否为1,取决于对应编号的学生的身高是否等于当前位向量所代表的取值。
问题简化一下,现在只有5名学生,数据如下:
(0,90)、(1,90)、(2,110)、(3,100)、(4,100)。
其中元组的第一个元素为学生编号,第二个元素为学生身高。
身高的取值只有90、100、110三种取值,则我们需要构建3个长度为5的位向量。

使用场景
位图索引是构建出来了,它有什么用呢
针对单个位图索引,所能想到的一个是between .. and ..形式的范围查找,另外一种是in (xxx)形式的列表包含查找。这两种查找,通过位图索引,可以很自然地转为为多个位向量的按位或操作,从而得到的结果向量中位取值为1的对应编号的学生均为复合条件的记录。如:
select * from t_student
where
height between 90 and 100
;则转换为90到100间的所有位向量的并集操作,得到结果向量为:
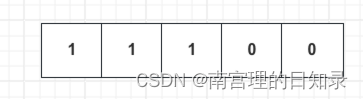
则表示编号0、1、2的学生均是复合条件的记录。
只是单一的条件检索,还不能提现位图索引的使用优势,假如我们有这样一个检索场景:
select * from t_student
where
(weight between 30 and 40)
and (height between 90 and 110)
;此时,如果是使用B+树索引,查询优化器只能根据统计信息,在weight和height两个索引之间取舍。
但是,如果是位图索引,则情况会变得不一样了:
我们可以同时给weight和height分别创建位图索引,然后将上述查询条件转换为如下的两步位运算:
1)每个位图索引内部,将条件范围内的多个位向量进行按位或运算,得到两个结果向量;
2)将两个结果向量进行按位与运算,得到最终的结果向量,其中为1的位对应的编号即为复合检索条件的数据记录。
需要说明的是,位图索引也存在着很多局限性,尤其在数据增删改方面,需要进行矩阵行和列的扩充操作,数据写的成本同样带来巨大的开销。
基于上面的位图索引的构建及维护过程,可以很轻易地发现,位图索引更适合字段取值有限,且相对固定的使用场景中
3、倒排索引
另外一种就是倒排索引(Inverted Index),倒排索引主要适用于全文检索的场景。MySQL的InnoDB存储引擎从5.6开始支持全文索引。
倒排索引之所以叫做“倒排”,是因为它与传统的索引形式刚好是相反的。通常意义下的索引,是通过文档(一般是文档的检索键)检索到对应的文档的内容,包含的一些关键词等。而倒排索引是在另一种刚好反过来的应用场景下应运而生的。
直观的最容易想到的就是搜索引擎的基于关键词的检索场景,我们需要基于关键词定位到出现过这些关键词的文档。而基于传统意义的正向(顺序)索引策略,则很难实现这种需求。
构建流程
倒排索引的构建一般需要经历如下步骤:

1)文档预处理操作,主要进行文档分词、词干提取、停用词过滤等操作,将文档转换为词项列表;
2)构建包含所有词项的列表;
3)对列表中的每一个词项,记录它出现过的文档及对应的位置,也可以同时记录词频,构建倒排记录;
4)将倒排记录进行持久化存储在一中便于检索的结构中。
如同位图索引,当基于倒排索引,进行多个关键词的检索操作时,则将检索操作转换成了多个关键词对应出现的文档集合的并集或者交集操作。
4、布隆过滤
提到位图索引,自然而然就会想到布隆过滤器(Bloom Filter)。这是一种空间效率使用极高的概率型数据结构,它用于判断一个元素是否属于一个集合。需要注意的是,虽然布隆过滤器与位图索引在结构上都是位向量的形式,但是,两者的使用场景还是有很大不同的。位图索引更多的用于持久化存储在磁盘上,用于提高定位检索到相关数据;而布隆过滤器,更多的在内存方面,快速排除不在集合内部的记录,从而减少磁盘的IO操作次数。
基本原理
布隆过滤器通常由一个位向量和一组哈希函数组成。位向量初始化为0,在添加元素的过程中,对位向量进行如下的更新操作:
1)对要添加的元素,通过每个哈希函数计算出哈希值,一组哈希函数则会得到多个哈希值;
2)每个哈希值对应位向量中的一个位置,将这些位置置为1即可。
如果需要进行查询某个元素的操作:
1)对要查询的元素,通过同样的一组哈希函数计算出多个哈希值;
2)检查这些哈希值对应的位向量的位置是否均为1;
3)如果均为1,则表示该元素可能在集合中,再去真正存放数据元素的集合进行查找;否则,该元素一定不在该集合中。
需要注意的是:
由于哈希冲突的存在可能,布隆过滤存在假阳性的存在,即可能存在元素在集合中,但是从布隆过滤器判断,可能存在的情况。
5、总结
介绍了几种索引的结构及使用,我们需要始终回归到数据库设计与优化的基本原则:尽量减少磁盘的IO操作,不管是聚簇索引、辅助索引,还是位图索引、倒排索引,或者是布隆过滤器的使用,其实都在是落实这项基本原则。
















 631
631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











