







引言
在上一篇文章中,我们通过Python的内置模块random,初步实现了测试数据的批量生成,解决了“巧妇难为无米之炊”的窘境。
但是,直接通过random模块进行测试数据的生成,在字段类型的灵活性、便捷性上,还是不太够用。如果要追求生成更加灵活、丰富的测试数据,更加便捷地生成测试数据。可以尝试本文介绍的已经被广泛使用的三方模块Faker。
准备工作
由于Faker是一个三方模块,所以我们在正式使用之前,需要先通过pip进行安装。关于pip最常用的几个命令,在该系列前面序号为1的文章中已经有所提到,不熟悉的,可以翻看一下。
安装Faker
pip3 install faker
注意:根据环境不同,可能是pip。
文档、源码及基本使用
关于Faker模块的源码及基本使用,可以参考:
https://github.com/joke2k/faker
Faker模块的使用
基本用法
Faker模块的基础使用可以按照这几步进行:
- 模块导入
- 创建并初始化Faker的生成器,可以指定语言环境
- 根据业务需要,调用生成器对应的方法,获取测试数据
示例代码如下:
from faker import Faker
# 指定语言环境为中文环境,创建Faker生成器
fk = Faker('zh_CN')
# 调用生成器的方法获取测试数据
print(fk.name())
print(fk.user_name())
Faker的构造方法__init__定义如下:
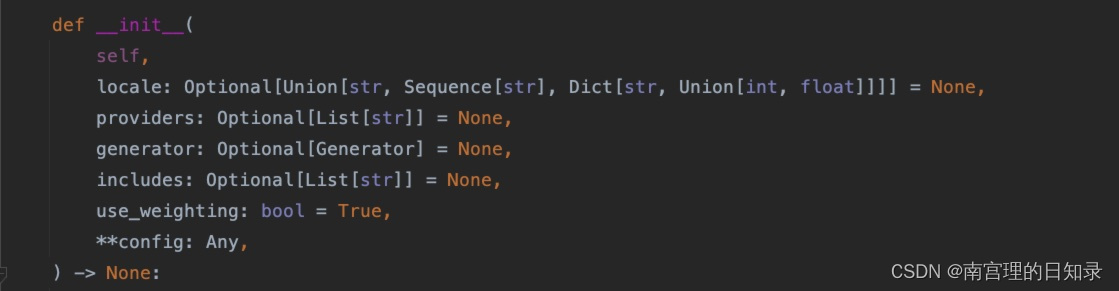
在进行面向对象编程中,自定义类时,都可以参考进行__init__()函数的定义。第一个参数一定是self,如果学习过其他编程语言,可以类比为this指针。没学过,就简单记一下就行,后续逐步加深理解。
除了self之外的形参,都可以理解为对应属性的初始值,这些形参都是带默认值的形参,所以我们构造Faker构造器时,一个参数不传也是可以的。
多语言环境
构造Faker生成器时,可以传入一个语言环境的列表:
from faker import Faker
# 指定语言环境为中文环境,创建Faker生成器
fk = Faker(['zh_CN', 'en_US', 'ja_JP'])
# 调用生成器的方法获取测试数据
for _ in range(10):
print(fk.name())
输出结果:
山下 直子
Donna Odom
Matthew Harris
Denise Smith
李红霞
鈴木 美加子
Angela Young
张玉英
Manuel Silva
藤井 さゆり
代码中出现了 _ 占位符,因为我们在循环内部,没有使用循环变量的场景,可以通过占位符 _来表示。这是Python提供的一种特殊语法,不习惯的,继续用for i in range(10)也是可以的。
生成唯一值
在实际调用Faker生成器的相关方法生成测试数据时,有时,发现生成的数据是重复的。如果需要生成唯一值,Faker提供了unique属性,来尽量保证生成不重复、唯一的测试数据。
from faker import Faker
# 指定语言环境为中文环境,创建Faker生成器
fk = Faker(['zh_CN', 'en_US', 'ja_JP'])
# 通过unique属性,调用生成器的方法获取测试数据,避免数据重复
for _ in range(10):
print(fk.unique.name())
需要注意的是,Faker模块会记录当前已经生成的数据,从而尽量保证生成不重复的数据。如果生成器的方法本身的原因,无法避免保证数据唯一,Faker在重试一定次数后,会抛出UniquenessException异常,从而避免无限重试,以期望获得一个不可能的结果。比如:生成100条人员信息时,生成100个性别数据时,就不可能做到数据的唯一性。
通过unique属性进行测试数据生成时,由于要保存比较当前已经生成过的数据,同时进行多次重试,所以生成大量数据的时候,性能也会受到影响。所以,具体看是业务场景需要吧。
自定义数据Provider
虽然Faker模块提供了很多用于生成测试数据的方法,但是,有时候我们还是有一些自定义的测试数据生成规则的需要。这时候,我们可以用random模块来实现自定义的特定需求。当然,Faker模块也提供了我们进行自定义测试数据Provider类的方法,从而扩展Faker模块的测试数据生成的功能。
如果暂时不熟悉面向对象的相关语法,以下代码实例,可以跳过,通常使用random模块依然能够满足需求。
方法1:通过继承BaseProvider来实现自定义测试数据的生成:
import random
from faker import Faker
from faker.providers import BaseProvider
# 自定义Provider,用于随机生成性别,男、女、未知,三个取值出现的概率比是100:100:1
class GenderProvider(BaseProvider):
def gender(self):
return random.sample(['男', '女', '未知'], counts=[100, 100, 1], k=1)[0]
# 指定语言环境为中文环境,创建Faker生成器
fk = Faker('zh_CN')
fk.add_provider(GenderProvider)
print(fk.name())
print(fk.gender())
代码中,本质上还是通过上一篇文章中提到的random.sample()取样方法来实现我们需要的测试数据生成的逻辑。
方法2:通过定义DynamicProvider对象
import random
from faker import Faker
from faker.providers import BaseProvider, DynamicProvider
# 方法1:自定义Provider,用于随机生成性别,男、女、未知,三个取值出现的概率比是100:100:1
class GenderProvider(BaseProvider):
def gender(self):
return random.sample(['男', '女', '未知'], counts=[100, 100, 1], k=1)[0]
# 方法2:通过DynamicProvider对象,实现自定义生成器扩展功能,但是,没有方法1更加灵活,比如不能控制不同取值的概率
gender_provider = DynamicProvider(provider_name='gender2', elements=['男', '女', '未知'])
# 指定语言环境为中文环境,创建Faker生成器
fk = Faker('zh_CN')
fk.add_provider(GenderProvider)
fk.add_provider(gender_provider)
print(fk.name())
print(fk.gender())
# 多试几次,很容易出现'未知'的取值
print(fk.gender2())
综合实例:基于业务规则批量生成数据
生成一批有几条简单规则的测试数据:
import random
from datetime import date
from faker import Faker
from faker.providers import BaseProvider
# 测试数据生成需求:
# 生成1000条会员信息,包含id、姓名、性别、生日、注册日期,需要满足如下规则:
# 1、姓名尽量不要重名;
# 2、性别有三种取值:男、女、未知,出现的概率比为:100:100:1;
# 3、生日要在1980-2024之间;
# 4、注册日期必须要在生日之后
class GenderProvider(BaseProvider):
def gender(self):
return random.sample(['男', '女', '未知'], counts=[100, 100, 1], k=1)[0]
fk = Faker('zh_CN')
fk.add_provider(GenderProvider)
for i in range(1000):
user_id = i + 1
name = fk.unique.name()
gender = fk.gender()
birthday = fk.date_between(date(1980, 1, 1), date(2024, 6, 25))
reg_date = fk.date_between(birthday, date(2024, 6, 25))
print(f"{user_id},{name},{gender},{birthday},{reg_date}")
输出结果:
1,陈军,女,2014-06-26,2019-12-08
2,牟志强,女,2011-11-03,2019-08-19
3,许彬,男,2007-03-02,2008-06-15
4,罗金凤,男,2021-01-27,2024-03-04
5,王淑兰,女,2009-11-24,2021-11-09
6,游云,女,2011-02-17,2012-08-29
7,李云,男,1997-11-24,2023-01-31
8,张琳,男,1989-05-06,2015-05-07
9,李涛,女,2020-09-21,2024-03-23
注意,此时我们只是把测试数据打印输出了,通常情况下,我们应该把数据保存到文件中,或者写入到数据库中,以便于后续的使用。由于我们暂时没有介绍到文件IO或者数据库的操作,可以有个偷懒的写法,通过open()打开一个文件,具体的参数,后续会提到,然后对print语句补充传参:
import random
from datetime import date
from faker import Faker
from faker.providers import BaseProvider
# 测试数据生成需求:
# 生成1000条会员信息,包含id、姓名、性别、生日、注册日期,需要满足如下规则:
# 1、姓名尽量不要重名;
# 2、性别有三种取值:男、女、未知,出现的概率比为:100:100:1;
# 3、生日要在1980-2024之间;
# 4、注册日期必须要在生日之后
class GenderProvider(BaseProvider):
def gender(self):
return random.sample(['男', '女', '未知'], counts=[100, 100, 1], k=1)[0]
fk = Faker('zh_CN')
fk.add_provider(GenderProvider)
data_file = open('test_data.csv', 'w')
for i in range(1000):
user_id = i + 1
name = fk.unique.name()
gender = fk.gender()
birthday = fk.date_between(date(1980, 1, 1), date(2024, 6, 25))
reg_date = fk.date_between(birthday, date(2024, 6, 25))
print(f"{user_id},{name},{gender},{birthday},{reg_date}", file=data_file, flush=True)
这里,只需要注意两行代码的变化:
1、以写的方式打开一个名为test_data.csv的文件,如果文件不存在会自动创建,文件打开时有内容会被清空
# 第一个参数为文件名,文件不存在会自动创建
# 第二个参数w,表示打开这个文件,接下来是要进行写入,文件在打开时如果有内容,则会被清空,如果需要追加内容到文件,可以使用'a'
data_file = open('test_data.csv', 'w')
2、print()函数的扩展用法:
print()函数除了把内容输出到屏幕上之外,还可以通过file命名形参指定别的输出目的地输出流,参数说明如下:
- file:表示内容输出的目的地,默认值为sys.out表示标准输出,就是输出到显示器显示出来
- flush:表示是否立即将内容刷出到指定目的地,默认值为False,会缓存,不立即刷出
# file指定内容输出的目的地,flush表示是否写一行就刷新到磁盘上,默认为False,True的话,每一行写入,都能立马在文件中看到
print(f"{user_id},{name},{gender},{birthday},{reg_date}", file=data_file, flush=True)
更多参数,可以查看print()函数的定义:

关于print中的sep参数、end参数的作用,可以阅读print()定义,并自己试着编写代码验证,这里就不展开了。
















 1021
1021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











