






我是dream,我在新课程培训学习网安知识,今天学习Web安全和基础的相关知识。
目录
Web发展史
01 简介
Web(World Wide Web)即全球广域网,也称万维网,它是一种基于超文本和HTTP的、全球性的、动态交互的、跨平台的分布式图形信息系统。是建立在Internet上的一种网络服务,为浏览者在Internet上查找和浏览信息提供了图形化的、易于访问的直观界面,其中的文档及超级链接将Internet上的信息节点组织成一个互为关联的网状结构。
万维网常被当成因特网的同义词,但万维网与因特网有着本质的差别、因特网(Internet)指的是一个硬件的网络,全球的所有电脑通过网络连接后便形成了因特网。而万维网更倾向于一种浏览网页的功能。
互联网包含因特网,因特网包含万维网,即互联网>因特网>万维网。
02 万维网www构想的诞生
1989.3.12,欧洲粒子物理研究所的计算机科学家蒂姆·博纳斯·李在其中一份提案《Information Management:A Proposal》中提出了一个构想:创建一个以超文本系统为基础的项目,允许在不同的计算机之间分享信息,其目的是方便研究人员分享及更新信息。这个构想最终成了WWW(World Wide Web)万维网的基础,彻底改变了人类社会的沟通交流方式。
博纳斯·李的提案包含了网络的基本概念并逐步建立了所有必要的工具:
1. 提出HTTP(Hypertext Transfer Protocol)超文本传输协议,允许用户通过单机超链接访问资源;
2. 提出了使用HTML超文本标记语言(Hypertext Markup Language)作为创建网页的标准;
3. 创建了统一资源定位器URL(Uniform Resource Locator)作为网站地址系统,就是沿用至今的http://www RUL格式;
4. 创建第一个Web浏览器,成为万维网浏览器,这也是一个Web编辑器;
5. 创建第一个HTTP服务器软件,后来称为CERN httpd;
6.创建第一个Web服务器(http://info.cern.ch)以及描述项目本身的第一个web页面。
03 Web发展史 Web History
| Web 1.0 | 个人网站,门户网站 www.163.com www.souhu.com 等。 Web 1.0时代开始于1994年,其主要特征是大量使用静态的HTML网页来发布信息,并开始使用浏览器来获取信息,这个时候主要是单向的信息传递。 |
| Web 2.0 | 微博,Blog等 www.weibo.com www.lofter.com Web 2.0始于2004年3月,Web 2.0 中,软件被当成一种服务,为用户提供网络应用的服务平台,强调用户的参与、在线的网络协作、数据储存的网络化、社会关系网络、应用以及文件的共享等成为了Web 2.0发展的主要支撑和表现。 |
Web 3.0 是Internet发展的必然趋势,是Web 2.0的进一步发展和延伸。
静态页面与动态页面
静态页面
在静态HTML页面中,用户通过Web浏览器HTTP协议向Web服务器发送一个响应请求,告诉Web服务器要浏览这个网站的哪个页面,接着根据用户的响应请求返回一个HTML页面给用户,经过浏览器渲染解析呈现在用户眼前。
静态Web页面是没有数据库文件的,所以不能连接网络数据库;
静态Web页面主要是通过HTML代码开发设计的;
部分静态Web页面为了页面好看,使用了大量的JS代码,导致静态Web页面打开速度慢。
可能会有伪静态页面(动态页面伪装成静态页面)
动态页面
在动态Web页面中,依然要通过Web服务器的http协议或https协议响应才能返回结果给用户,用户所有请求都必须要通过Web服务器处理才能实现。
用户的响应请求是一个静态的HTML页面,只需要响应请求Web服务器从系统中调出用户响应的内容,将内容返回给客户端浏览器进行处理,再返回给用户。
如果用户响应请求的是动态页面资源,例如.jsp/.asp/.aspx/.php等,相应步骤是先将用户请求发送给Web服务器,Web服务器再从数据库调出有用户请求的数据,调出数据后将所需要展示给用户的内容发送给服务器,最后通过Web服务器将需要展示给用户的内容返回给用户浏览器解析执行,展示给用户。
有交互才有漏洞可挖,所以漏洞大多出现在动态页面。
Web 1.0和Web 2.0的本质区别
Web1.0 的主要是在于用户通过浏览器获取信息。Web2.0则更注重用户的交互作用。
| Web 1.0 | Web 2.0 |
| 网站生成固定内容 | 用户自己生成内容 |
| 静态页面 | Mashup和Web服务 |
| 桌面浏览器 | 复杂的客户端软件 |
| 简单&同步 | 复制&异步 |
Web 1.0 和Web 2.0 可能存在的漏洞
| Web 1.0 | Web 2.0 |
| SQL注入、文件包含、命令执行、上传漏洞、WebShell | 钓鱼攻击、URL跳转、框架漏洞、逻辑漏洞、XSS、CSRF |
URL
定义
URL Uniform Resource Locator 统一资源定位符,俗称网址,网上标准的资源的地址(Address),如同在网上的门牌。它最初是由蒂姆·博纳斯·李发明用来作为万维网的地址,现在它已经被万维网联盟编制为因特网标准RFC 1738
格式
protocol://hostname[:port]/path/[;parameters][?query]
protocol 协议,常用的协议是http、https、ftp等
hostname 主机地址,可以使域名,也可以是IP地址
port 端口, http协议默认端口是:80端口
path路径, 网络资源在服务器中的指定路径
parameter 参数, 如果要向服务器传入参数,在这部分输入
query 查询字符串, 如果需要从服务器那里查询内容,在这里编辑,可有多个参数,用“&”符隔开,每个参数的名和值用“=”符号隔开。
e.g
http://163.com/content/test/test/php?name=serach&user=admin&id=1
http://湖南省·长沙市·湖南XXX院id?货物=零食大礼包&收件人=李华&手机号=123456789
这个就没有设置路径,直接输入传递的实际参数。
https://www.163.com/dy/article/I5VNGQKR05563UDV.html/?spss=index_sroties&clickform=w_ttgsh

1. 可不设置路径,只要有协议域名就可以访问网页:htttps//192.168.188.23
2. port,默认端口不显示,比如http和https协议的,都没有显示端口。如果要显示:http://192.168.188.23:80/
3. path,其实相当于用户端想要访问的资源的存放的网络虚拟地址(这个路径会模糊掉具体存放的网盘信息)。比如pikachu靶场:在电脑里面的存放地址是E盘/pikachu/vul/xss/xsspost,映射到网址上,是主机地址后面的pikachu/vul/xss/xsspost,至于具体在哪个盘,并没有显示。要定位到这个资源,需要从这个路径去搜索。
3.参数和查询字符串都是连接数据库的时候用的(即访问动态网页的时候用)。
parameter指的是具体访问哪个数据库,所需要传递给后端的数据,它其实也是路径的一部分。可以定位到更具体的信息。比如post_login.php,如果不要?后面这一大段,就会出现一个登录页面,这个是pikachu这个靶场众多子目录下满的一个页面。
?后面的query是进入数据库具体要查询什么内容所需要传递的实际参数,提交了才能打开想要看的页面。比如账号密码才能登入到具体的页面。这里显示的是username=123&password=123&submit=login,相当于想要访问需要的资源,需要输入用户名,密码,并点击登录。
PS: https 默认443端口; http 默认80端口 (会提示“不安全”)
HTML基础
什么是HTML?
HTML是用来描述网页的一种语言。
HTML指的是超文本标记语言:Hyper Text Markup Language。
HTML不是一种编程语言,而是一种标记语言,标记语言是一套标记标签来描述网页。
HTML使用标记标签来描述网页;
HTML文档包含了HTML标签及文本内容;
HTML文档也叫做Web页面。
HIML标签
HTML标记标签通常被称为HTML标签(HTML tag)
HTML标签是由尖括号包围的关键词,比如<html>
HTML标签通常是成对出现的,比如<b>和</b>
标签对中的第一个标签是开始标签,第二个标签是结束标签
开始和结束标签也被称为开放标签和闭合标签
<标签>内容</标签>
HTML 元素
“HTML 标签”和“HTML 元素”通常都是描述同样的意思。
但是严格来讲,一个HTML元素包含了开始标签与结束标签,如下实例:
HTML元素:<p>这是一个段落。</p>
HTML标签简介
常见的双标签
<html></html> <head></head> <title></title> <body></body> <h1></h1>
<p></p> <div></div> <a></a> <ul></ul>
常见的单标签
<br/> <!--换行--> <hr/> <!--水平分割线--> <meta/> <img/>
嵌套关系
<head>
<title> </title>
</head>
并列关系
<head></head>
<body></body>
01 HTML-标题
通过<h1>-<h6>标签来定义的。
02 HTML-链接
通过标签<a>来定义。标签<href>属性用于指定超链接目标的URL。在href属性中指定链接的地址。(注意标签书写的正确性,字母顺序不能错)
03 HTML-图像
HTML图像是通过标签<img>来定义的。
图片可以是本地图片,或者远程的图片
本地图片:
1. 和生成的HTML文件在同一个目录下,只需要图片名和格式

2. 和生成的HTML文件不在同一个目录下,填写绝对路径。

远程图片
搜索一张图片,右键复制图片链接,粘贴到img标签中即可

04 HTML-水平线
<hr>标签在HTML页面中创建水平线
hr元素可用于分割内容
05 HTML-注释
可以将注释插入HTML代码中,这样可以提高其可读性,注释不会显示在web页面中。
<!--这是一个注释-->
06 HTML-换行
如果我们希望在不产生一个新段落的情况下进行换行(新行),请使用<br>标签:<p>这个<br>段落<br>演示了分行的效果</p>


Web 浏览器
Web浏览器(如谷歌浏览器,Internet Explorer,Firefox,Safari)是用于读取HTML文件,并将其作为网页显示。(如上图)
浏览器并不是直接显示的HTML标签,但可以使用标签来决定如何展现HTML页面的内容给用户。
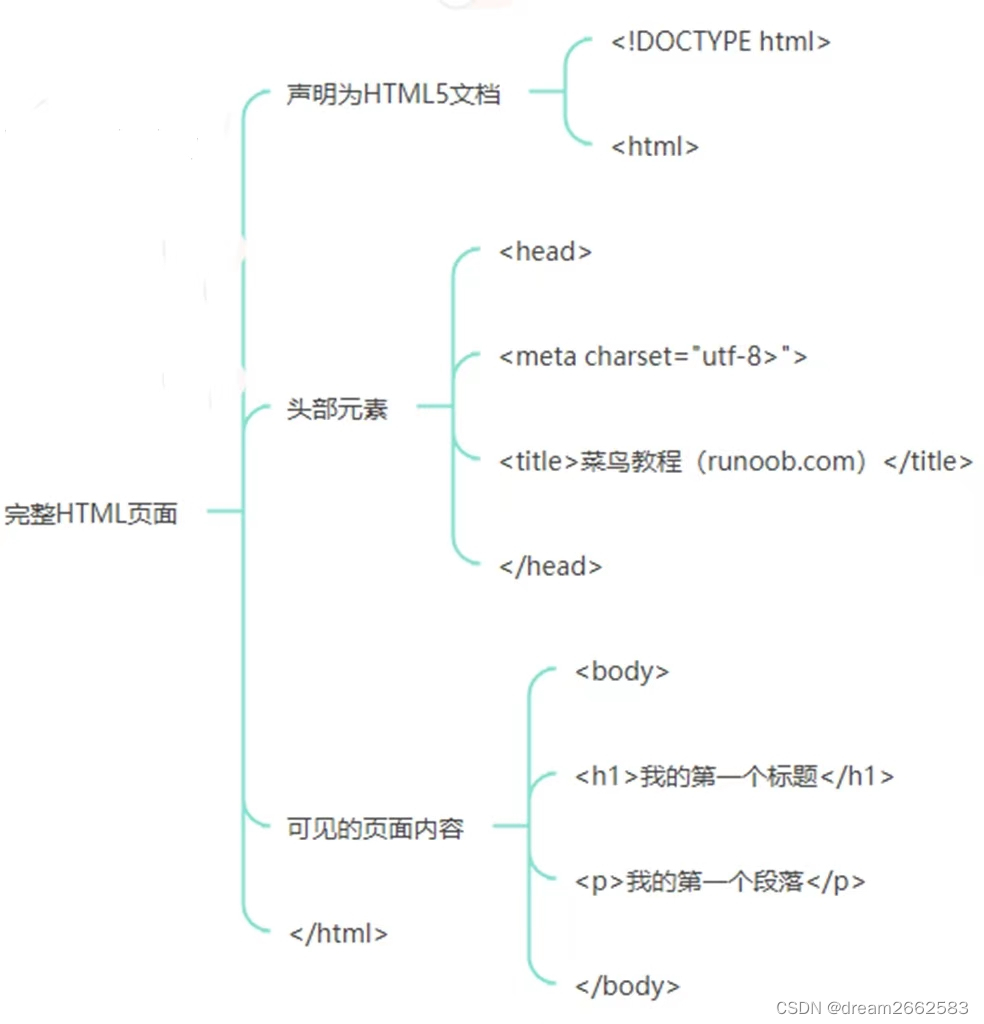
例:
格式:
<!DOCTYPE html>声明为HTML5文档
<html>
<head>元素是HTML页面的根元素
<meta charset="utf-8"> 元素包含了文档的元(meta)数据,这里定义网页编码格式为utf-8
<title>网页学习</title> 元素描述了文档的标题
<head><body>元素包含了可见的页面内容
<h1>我的第一个标题</h1>元素定义一个大标题
<p>我的第一个段落。</p>元素定义一个段落
</body>
</html>

我用的是sublime编辑的,写完代码之后,保存好,然后用IE浏览器打开就得到了以下网页。

PS:注意图片地址,是远程还是本地,在同一个目录下还是不在,如果格式错误,图片会不显示。
web访问流程
如何访问web应用的?
1. 在浏览器地址栏输入URL访问;
2. 浏览器向DNS服务器请求解析该URL中的域名所对应的IP地址;
3. 解析出IP地址后,根据该IP地址和默认端口80,和服务器建立TCP连接;
4. 浏览器发出读取文件(URL中域名后面部分对应的文件)的HTTP请求,该请求报文作为TCP三次握手的第三个报文的数据发送给服务器;
5. 服务器对浏览器请求做出响应,并把对应的HTML文本发送给浏览器;
6. 浏览器将该HTML文本进行解析并显示出内容。
HTTP
什么是HTTP?
超文本传输协议(Hyper Text Transfer Protocol, HTTP),是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能要发送给服务器什么样的信息以及得到什么样的响应。
Hyper Text: 超文本
Transfer : 传输,把数据资源从服务器搬运到客户端
Protocol:协议是指通信双方为了交换信息,使用的一种数据格式或者一组规则
HTTP协议的内部操作过程
HTTP定义的事务处理由以下四步组成
客户端与服务器端建立连接
客户端向服务器端发送请求
服务器端向客户端回复响应
断开连接
HTTP协议的发展
HTTP协议是基于TCP/IP协议的应用层协议,在OSI七层模型中在最上层,它并不涉及数据包传输,主要规定了客户端和服务器之间的通信模式,默认使用80端口。
1991年发布HTTP/0.9,只支持GET.只能回应HTML格式的字符串。
1996年5月,HTTP/1.0版本发布,增加了POST和HEAD命令,可以发送任何格式的内容。
1997年1月,HTTP/1.1版本发布。将持久化连接加入了HTTP标准,即TCP连接默认不关闭,可以被多个请求复用。还增加了PUT、CONNECT、HEAD、OPTIONS、DELETE。
HTTP的请求方法
| 方法(操作) | 含义 |
| GET | 请求获取Request-URI(请求地址)所标识的资源。(请求读取由URL所标志的信息) |
| POST | 在Request-URI所标识的资源后附加新的数据。(给服务器添加信息,例如注释) |
| HEAD | 请求获取由Request-URI所标识的资源的响应消息报头。 |
| PUT | 请求服务器存储一个资源,并用Request-URI作为其标识 |
| DELETE | 请求服务器删除Request-URI所标识的资源 |
| TRACE | 请求服务器回收收到的请求信息,主要用于测试或诊断 |
| CONNECT | 用于代理服务器 |
| OPTIONS | 请求查询服务器的性能,或者查询与资源相关(特定)的选项和需求 |
GET和POST的区别
区别原理:
URL全称是资源描述符,一个URL地址用于描述一个网络上的资源,HTTP中的GET 、POST 、PUT 、DELETE就对应着对这个资源的查、改、增、删4个操作。
GET一般用于获取/查询资源信息
POST一般用于更新资源信息
GET用于信息获取时应该是安全的,幂等的。
01 安全:该操作用于获取信息而非修改信息。它仅仅是获取资源信息,就像数据库查询一样,不会修改,增加数据,不会影响资源的状态。
02 幂等:对同一个URL的多个请求应该返回同样的结果。
POST标识可能修改服务器上的资源的请求。
HTTP协议的主要特点
1. 支持客户/服务器模式(C/S模式):一个服务器可以为分布在世界各地的许多客户服务
2. 简单快捷:付互相服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET和POST。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
3. 灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
HTTP 报文格式:请求报文
HTTP请求由四部分组成:请求行(request line)、请求头部(header)、空行和请求数据
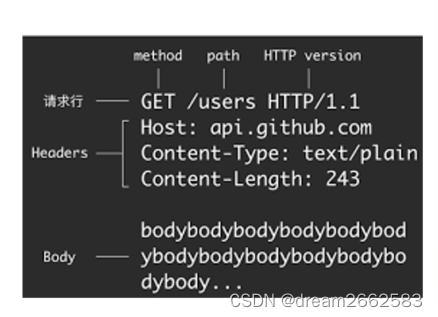
请求行: HTTP请求方法 URL HTTP协议版本
请求头部:头部字段名:值
头部字段名:值
……
空行:
请求数据:

| 请求头部 | 描述 |
| Accept | 指定客户端接受信息的类型(MIME类型) |
| Connection | 允许C/S指定与请求/响应连接的有关选项 |
| Host | 请求服务器的主机名和端口号 |
| Referer | 包含一个URL,用户从该URL代表的页面出发访问当前请求的页面 |
| User-Agent | 发起请求的应用程序名称 |
| Accept-Encoding | 告诉服务器能够接受哪些内容编码方式 |
| Content-Length | 表示请求消息正文的长度 |
| Cookie | 客户端提供给服务器的认证数据 |
Accept: 如果是*/* 表示客户端接受信息的类型是不限类型。
Referer:来源页。
如果从A页面跳转到B页面,那么:GET HTTP/1.1
HOST:B页面
Referer:A页面
Cookie:即登录一个应用时,如果勾选了Cookie,您的账号密码就会存在Cookie里面。
HTTP状态信息
临时响应(1xx):表示临时响应并需要请求者继续执行操作的状态代码
成功(2xx):表示成功处理了请求的状态代码
重定向(3xx):表示要完成请求,需要进一步操作,通常用来重定向。
请求错误(4xx):表示请求可能出错,妨碍了服务器的处理
服务器错误(5xx):表示服务器再尝试处理请求时发生内部错误
HTTP的缺陷
由于HTTP协议的简单特性,且不保存客户端的状态,不进行验证客户端是否是真实存在,传输使用的是明文传输,故也很具有缺点。
即:
01 通信双方使用明文传输(不加密),内容可能会被窃听。
02 不验证通信方的身份,因此可能遭遇伪装。
03 无法证明报文的完整性,所以有可能已遭篡改。
为了解决以上缺点,出现了HTTPS
HTTPS协议基础
什么是HTTPS
HTTPS是在HTTP上建立SSL加密层,并对传输数据进行加密,是HTTP协议的安全版。
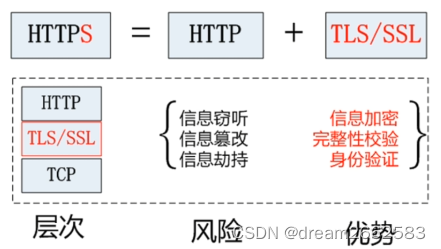
HTTPS主要作用:
01 对数据进行加密,并建立一个信息安全通道,来保证传输过程中的数据安全;
02 对网站服务器进行真实身份认证。
默认HTTP的端口为80,HTTPS的端口号为443。
两者区别
本质:HTTP明文,HTTPS加密
信任主机的问题:采用https的server必须从CA申请一个用于证明服务器用途类型的证书。该证书只有用于对应的server的时候,客户才信任该主机。
为什么要加密?
01 防止中间人攻击
02 防钓鱼
抓包
Burp
代理服务器——中间商
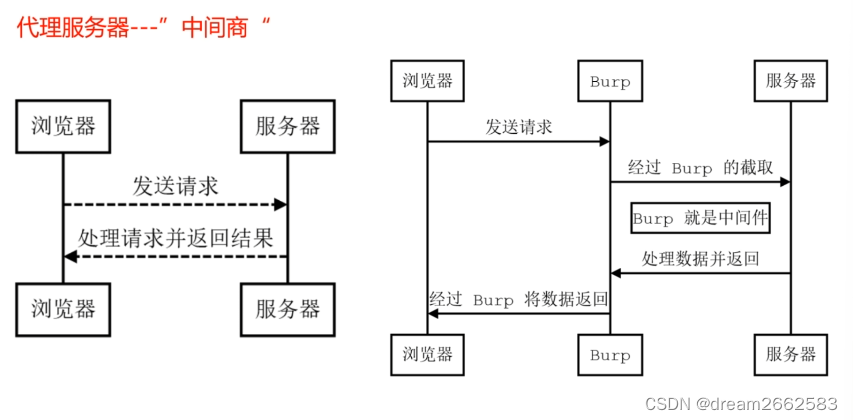
PS:Intercept is on (处于抓包状态,拦截状态,访问不了目标网站,会一直转)
抓了包之后,可以改数据,然后再放回去,这样用户就会发现自己密码错误。(又是一个很刑的操作)
intercept is off (处于放包状态,可以访问目标网站)
Burp Suite是用于攻击Web应用程序的集成平台。它包含了许多工具,并为这些工具设计了许多接口,以促进加快攻击应用程序的过程。
-Proxy:是一个拦截HTTP/S的代理服务器,作为一个在浏览器和目标应用程序之间的中间人,允许你拦截、查看、修改在两个方向上的原始数据流。
感谢KIKI老师,课程同步在享学微信公众号上,关注公众号,自动回复获取代码笔记资料。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









