






01 查询数据
1. 基本查询语句
查询数据是数据库操作中最常用的操作。通过对数据库的查询,用户可以从数据库中获取需要的数据。数据库中可能包含着无数的表,表中可能包含着无数的记录。因此,要获得所需的数据并非易事。MySQL中可以使用SELECT语句来查询数据。根据查询的条件的不同,数据库系统会找到不同的数据。通过SELECT语句可以很方便地获取所需的信息。
MySQL中select的基本语法形式
Select 属性列表
from 表名和视图列表
[where条件表达式1]
[group by 属性名1 [having 条件表达式2]
[order by 属性名2 [asc | desc]]
2. 表单查询
(1)查询stu中的所有信息;
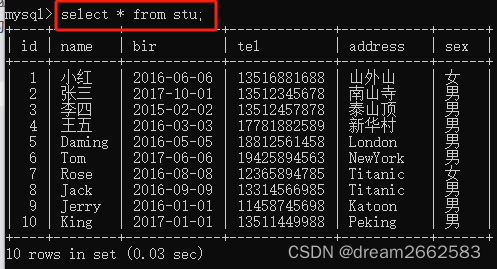
*代表查询stu这个表中的所有信息;
(2)查询stu中的部分信息;
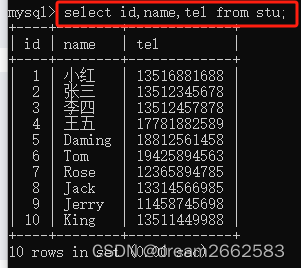
想查什么就输入对应的field就行了。
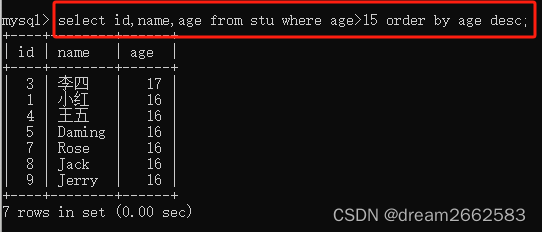
(3)有条件地查询部分信息;
select id,name,age from stu where age>15 order by age desc
从stu表中查询age大于15的记录,按照age字段降序进行排序(desc=descending)
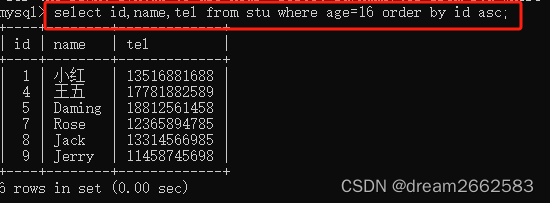
从stu表中查询年龄为16岁的id,name,tel,用id的升序排列
(4)查看数据库中的表结构;
desc表名;
describe
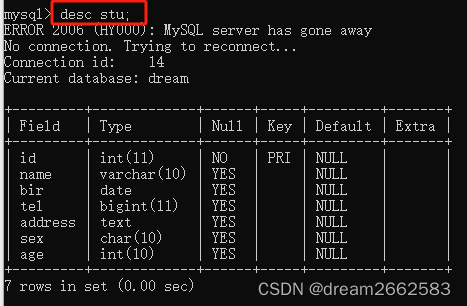
(5)查询指定句段
select 字段1,字段2 from 表;
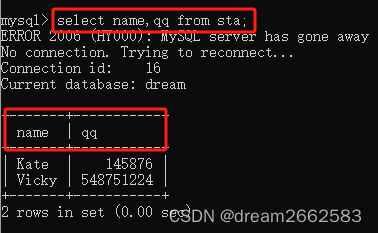
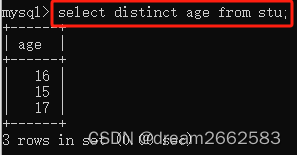
(6)去除重复值
select distinct 字段名 from 表名;
字段名(要去除数值重复的列)
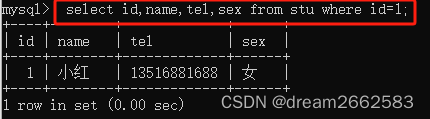
(7)查询指定记录;
where 条件表达式
select id,name,tel,sex from stu where id=1;
3. Where 子句
where 子句常用的查询条件
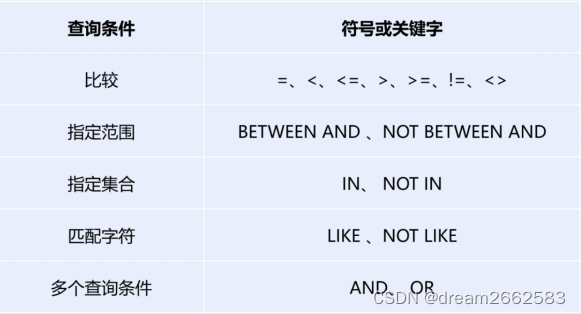
(1)比较
"=" 等于
"<" 小于
"<=" 小于等于
">" 大于
">=" 大于等于
"=" 不等于
<>" 不等于
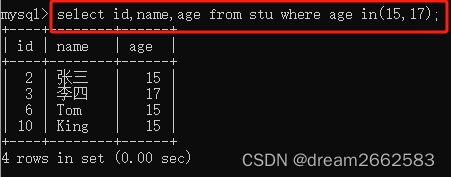
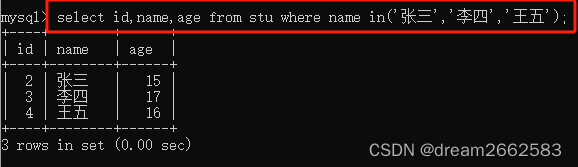
(2)IN关键字查询
IN关键字可以判断某个字段的值是否在指定的集合中。如果字段的值在集合中,则满足查询条件,该记录将被查询出来;如果不在集合中,则不满足查询条件。
[NOT] IN (元素1,元素2……,元素N );
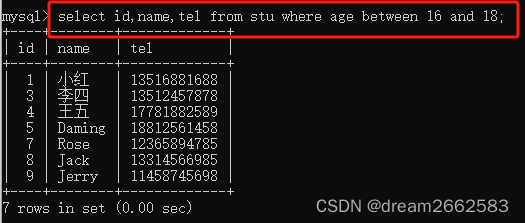
(3)Between查询范围
判读字段的值是否在指定范围,语法规则如下
[NOT] BETWEEN 取值1 AND 取值2
取值1:大于等于这个值
取值2:小于等于这个值
(4)Like匹配查询
匹配字符串是否相等
语法如下:
[NOT] like '字符串'
此处like和等于号“=”是等价的。

使用like匹配带有通配符“%”的字符串“王%”
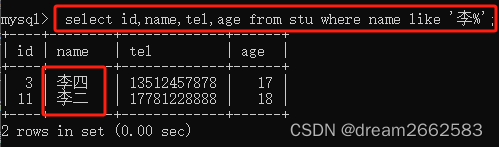
输错了输入 '> ^x^c 退出。
使用like匹配带有通配符“_”的字符串“王_”匹配单个字符;
下划线的用途与“%”一样,但下划线只匹配单个字符而不是多个字符。
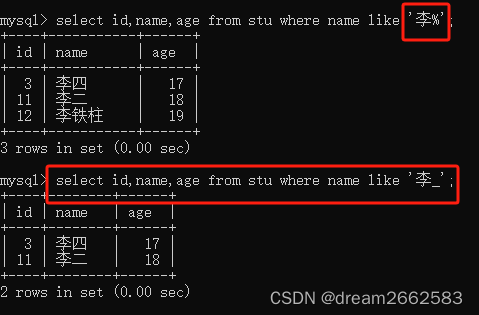
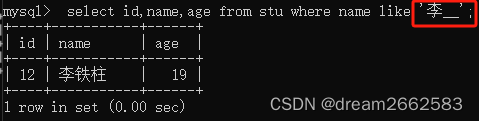
此处用了两个“_”;,所以查出来的人名是李某某。
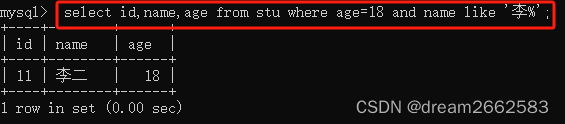
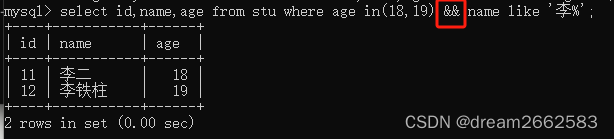
(5)AND多条件查询 等同于&&
联合多个语法规则进行查询 语法规则如下
条件表达式1 and 条件表达式2
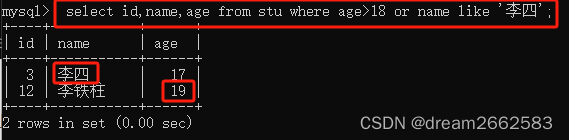
(6)OR多条件查询等同于 ||
只要满足几个查询条件中的其中一个,记录就会被查询出来,语法规则如下:
条件表达式1 OR 条件表达式2
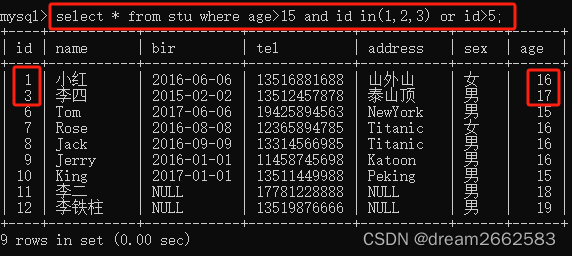
PS: and 与 or
and 与 or 一起的时候,and 要比 or 先运算。

先运算and,则前面那个条件自相矛盾,左边为假,右边为真。所有只筛选了所有年龄为16的学生;
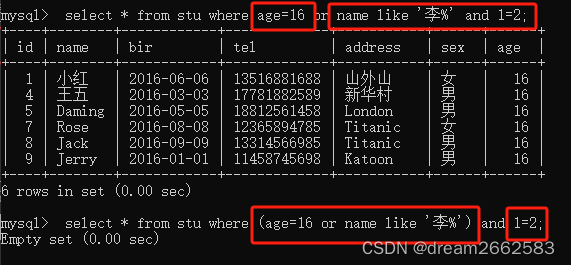
上面一个先算右边的and语句,因为1=2为假,所以整个and语句为假;or前面的为真,所以显示的内容全部符合‘age=16’这个条件。
下面一个因为加了小括号,所以先算小括号里面的,后算and。因为1=2为假,无论另一个是真是假,整个命令为假。
类似于加减混合运算的运算次序,先算and,后算or,有小括号的先算小括号;
(7)LIMIT限制查询结果的数量
LIMIT不指定初始位置,从第一条记录开始显示。语法规则如下:
LIMIT 记录数
limit n,m
n:开始位置
m:要检索的行数
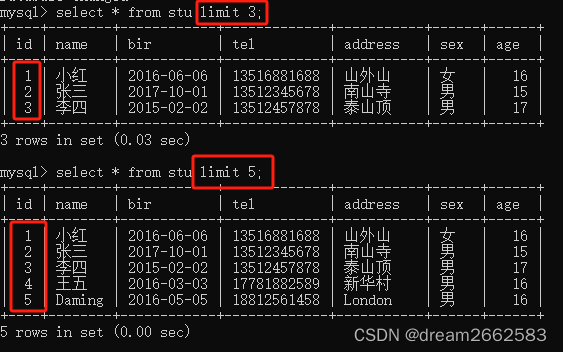
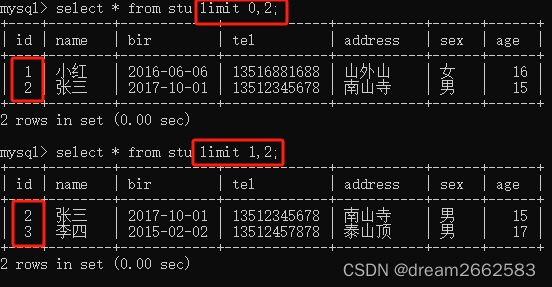
行0:检索出来的第一行为行0,而不是行1
因此,limit1,1将检索出第二行而不是第一行。
(8)对查询结果排序
ORDER BY对记录进行排序。语法规则如下:
ORDER BY 属性名 [ASC DESC]
ASC:升序(默认升序)
DESC:降序
可以给多个列排序,只需要指定列名,列名之间用逗号分开即可。
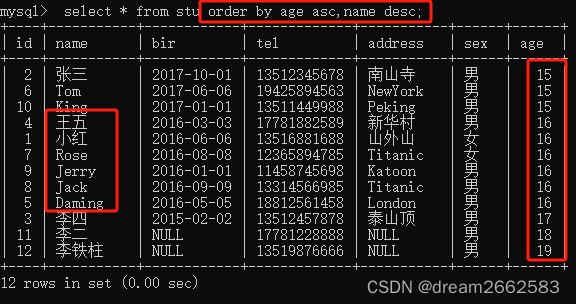
用年龄升序排列(默认升序,可以不写asc),同龄的按名字降序排列。
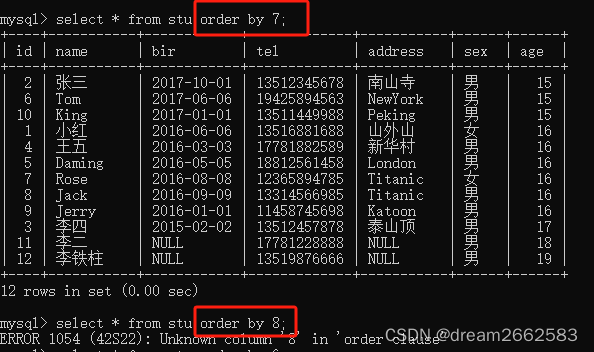
order by 数字,可以查询这个表格最多有多少列。大于列数会报错;
ORDER BY和LIMIT组合
能够找出一个列中最高或最低的值
select 字段名 from 表名
order by 字段名 DESC|ASC
LIMIT 1;
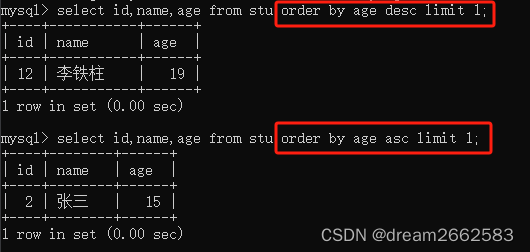
第一个按年龄降序排列,只显示一行,所以是最大值;
第二行按年龄升序排列,只显示一行,所以显示的是最小值。
(9)分组查询
语法规则如下:
GROUP BY 属性名 [having 条件表达式]
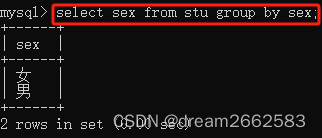
查询的属性,必须跟group by 后的属性一致。否则报错。
如:
使查询结果按照某一列或多列值进行分组,值相等的为一组。
GROUP BY [ALL] GROUP BY EXPRESSION
HAVING
对分组后的结果按条件进行筛选
只能在Group by子句后使用,不能单独使用,只能对分组计算的结果进行筛选,不能使用别名
select 字段名 from 表名 group by 字段名 having 等式;
02 集合函数
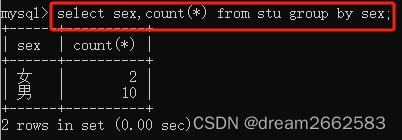
(1)count ()
用来统计记录的条数

第一个函数统计数据有12行;
第二个统计每一个年龄有几人;
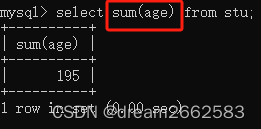
(2)sum()
用来计算字段的值的总和(求和)
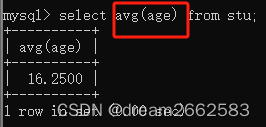
(3)Avg()
求平均数
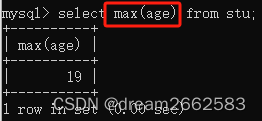
(4)Max()
求最大值
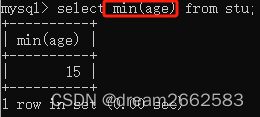
(5)min()
求最小值
03 正则表达式查询
正则表达式
是用某种模式去匹配一类字符串的一一个方式。例如,使用正则表达式可以查询出包含A、B和C其中任一学母的学符串。正则表达式的查询能力比通配学符的查询能力更强大,而且更加的灵活。正则表达式可以应用于非常复杂查询。
使用REG EXP关键字来匹配查询正则表达式。其基本形式如下
属性名 REGEXP匹配方式
“属性名”参数表示需要查询的字段的名称
匹配方式”参数表示以哪种方式来进行匹配查询。

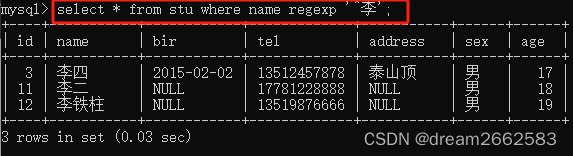
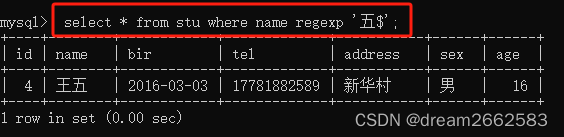
(1)“^”
查询以特定字符或字符串开头的记录
(2)“$”
查询以特定字符或字符串结尾的记录
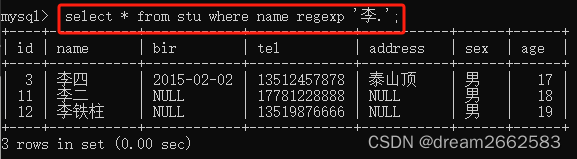
(3)“.”
匹配字符串中的任意一个字符;
用法类似于SQL中的like ‘刘_’
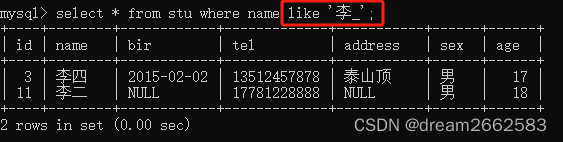
.和_的区别
两个都可以代替任意一个字符进行查询。
“.”只能用于regexp关键字匹配
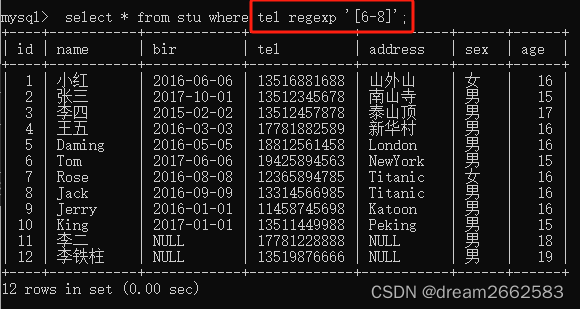
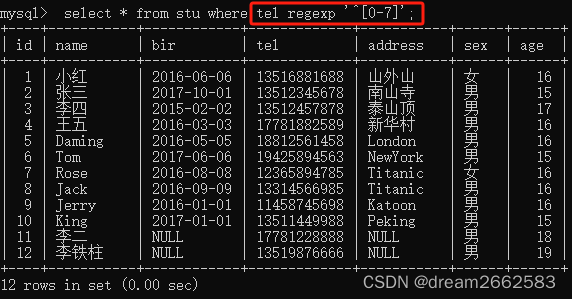
(4)“[]”
字符集合。匹配所包含的任一个字符。
(5)‘^字符集合’
匹配指定字符之外的字符。
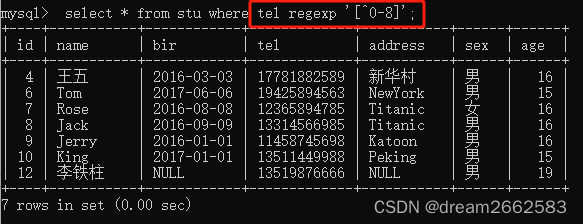
如果把^写到[]外面去了,则表示的意思是匹配不以8/9开头的字符。
 ()
()
(6)匹配指定字符串
正则表达式可以匹配字符串。当表中的记录包含这个字符串时就可以将该记录查询出来。如果指定多个字符串时,需要用符号“|”隔开。只要匹配这些学符串中的任意一个即可。
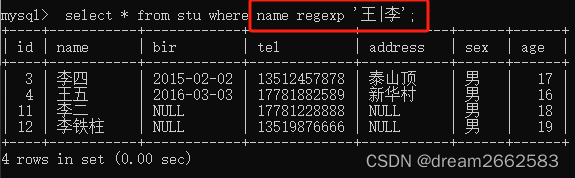
相当于or
(7)“*”和“+”
匹配多个字符,*和+都可以匹配该符号之前的字符
“+”至少表示一个字符;
“*”可以表示0个字符。
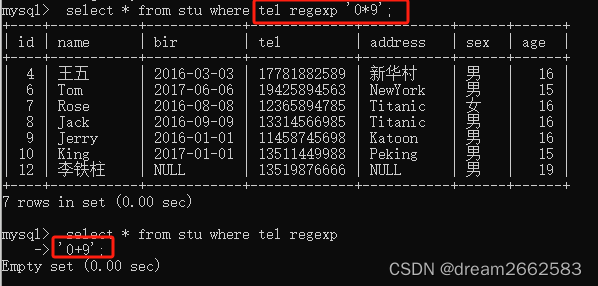
0+9 表示9的前面一定要紧跟0,如果没有就是empty
0*9 表示9的前面可以是0,没有也行。
(8)“{m}”或者“{m,n}”来指定字符串连续出现的次数
{m}:m是一个非负整数。匹配确定的m次。
{m,n}m和n均为非负整数,其中m<=n
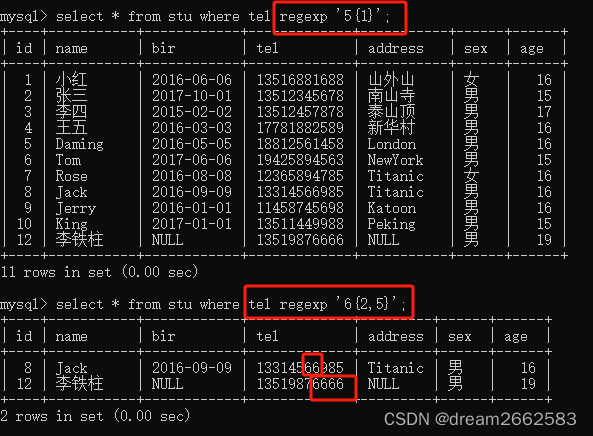
上一个是匹配5出现一次的电话
下一个是,匹配6连续出现2到5次的电话。
04 运算符
MySQL运算符
可以指明对表中数据所进行的运算
MySQL主要有以下几种运算符:
算术运算符:加减乘除求余,主要是用在数值计算上。
比较运算符:大于、小于、等于、不等于,主要用于数值的比较和字符串的匹配上。
逻辑运算符:与、或、非、异或等,结果只返回真值(1或者true)和假值(0或false)。
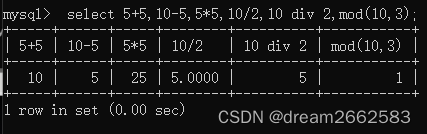
1. 算术运算符:
加减乘除求余,主要用在数值计算上。
| 运算符 | 作用 |
| + | 加 法 |
| - | 减法 |
| * | 乘法 |
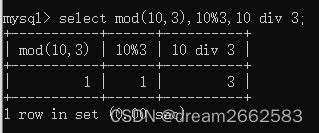
| /或DIV | 除法 |
| %或MOD | 取余 |
| mod(m,n) | 取余的格式 |
| n%m | n除m取余数 |
| n div m | n除m取结果的整数 |
2.比较运算符
大于、小于、等于、不等于,主要用于数值的比较和字符串的匹配上。
| 符号 | 描述 |
| = | 等于 |
| > | 大于 |
| <>, != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| >= | 大于等于 |
| BETWEEN | 在两值之间 |
| NOT BETWEEN | 不在两值之间 |
| IN | 在集合中 |
| NOT IN | 不在集合中 |
| <=> | 严格比较两个NULL值是否相等 |
| LIKE | 模糊匹配 |
| REGEXP或RLIKE | 正则式匹配 |
| IS NULL | 为空 |
| IS NOT NULL | 不为空 |
3. 逻辑运算符:
与、或、非、异或等,结果只返回真值(1或者true)和假值(0或false)。
| 运算符号 | 作用 |
| NOT 或 ! | 逻辑非 |
| AND或&& | 逻辑与 |
| OR或|| | 逻辑或 |
| XOR | 逻辑异或 |
xor 同性相斥,异性相吸
1 xor 1 = 0
1 xor 0 = 1

4. MySQL注释符号
有三种,分别如下所示:
1.#...
2."__”(注意:.."后面有一个空格)
3. /*…*/
1、“#”,表示单行注释,语法“# 注释内容"
2、"--”,表示单行注释,语法“-- 注释内容"
3、“/**/”,表示多行注释,语法“/*注释内容*"
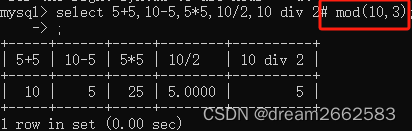
注释最后一个运算,逗号也不要才行,不然会报错。
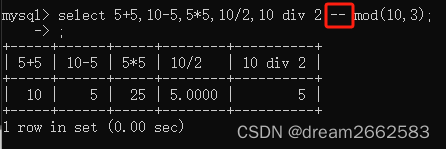
用--也是同样的效果。
05 查询函数
(1)联合查询:UNION
并操作union、交操作intersect、差操作except
UNION用于合并具有相同字段结构的两个表的内容,主要用在一个结果中集中显示不同表的内容
select * from venus1
union
select * from venus2union查询默认不返回重复记录
union查询的表的字段必须一样
union查询的数据类型必须能兼容
#union查询结果只增加了行数而列数不变
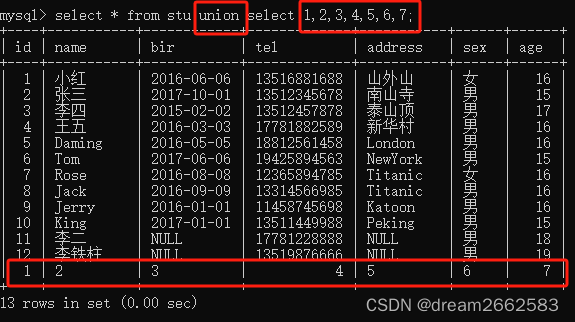
这里没有字段完全一致的表,所以就用数字占位来查。
如果只输到6,则会报错,因为字段必须一样。
union操作符用于合并两个或多个select语句的结果集
union所查询的列数、列的顺序必须相同,数据类型必须兼容
(2)组合查询
id = 1 order by 7 -- + 正常
id = 1 order by 8-- + 异常
结论:当前语句查询了七列
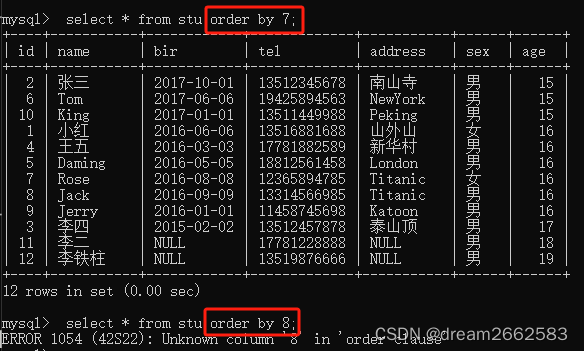
求显示位的原因:
尽管查询出四列,但页面只显示出两列内容,而需要求出到底用了哪两列,再在所用的列中插入paylaod。
(3)嵌套查询:
[NOT]IN、ANY、ALL、[NOT]EXISTS
1.子查询
2.子查询可以继续嵌套
3.子查询中不可以使用order by子句,只对最后结果排序
4.子查询要用括号括起来
子查询结果为集合时可用如下关键字判断
[NOT] IN [不]包含其中
ANY//ALL 任何一个//所有的
[NOT]EXISTS [不]存在
(4)查询函数
系统用户名:system_user()
查询语句:
select system_user();
select user from mysql.user用户名:user()
查询语句:
select user();
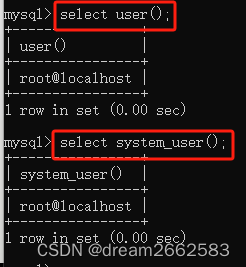
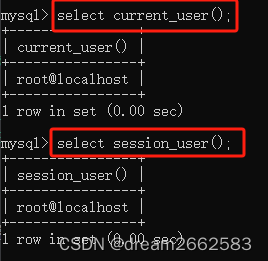
当前用户名:current_user()
查询语句:current_date()当前日期
select current_user();
连接数据库用户名:session_user()
查询语句:
select session_user()
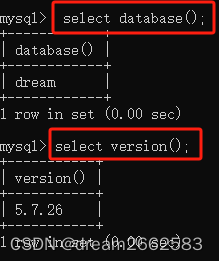
数据库名:database()
查询语句:
select database();数据库版本:version()
查询语句:
select version();
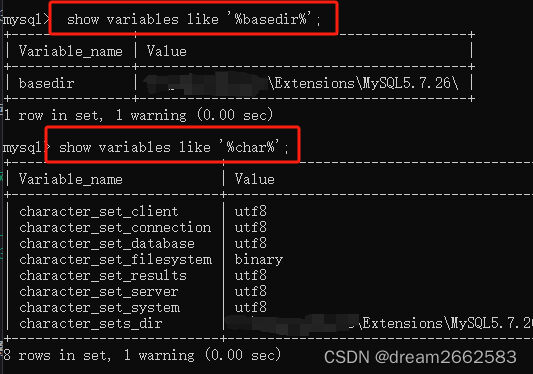
数据库读取路径:@@basedir
查询语句:
show variables like '%basedir%'
MYSQL安装路径:@@char
查询语句:
show variables like '%char%'
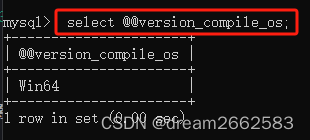
查看当前系统版本:@@version_compile_os
查询语句:
select@@version_compile_os;
(5)其它相关函数:
left(s,n)#返回字符串s最左边的字符 n是个数
right(s,n)#返回字符串s最右边的字符
substr(s,n,len) mid(s,n,len)
#截取学符串s的第n个学符,且截取长度为len
Ipad(string,length; str2' ) rpad(string,length, str')
#string:需要填充的字符串 length:填充之后的总长度 str:填充字符串,默认空格
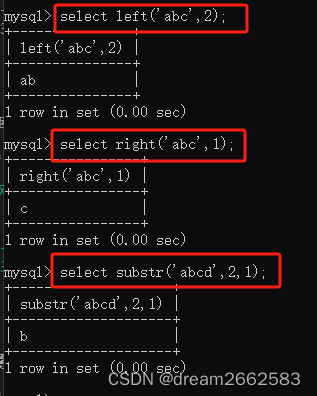
left('abc',2) 从左边开始,截取两个字符;
right('abc',1) 从右边开始,截取一个字符;
substr('abcd',2,1) 从第二个字符开始,截取一个字符。
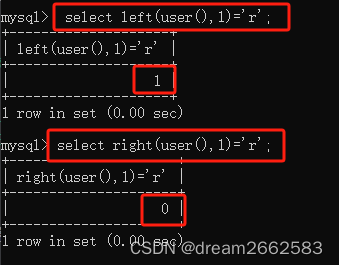
判断当前用户的第一字符
查询语句:
select left(user(),1)=' r';
判断当前用户的最后一个学符:
查询语句:
select right(user(),1)=' r' ;
#正确返回1,错误返回0
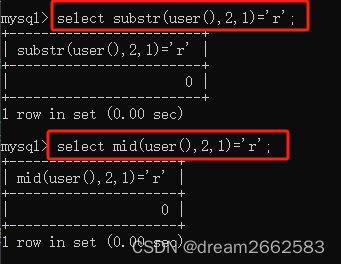
截取函数:
截取当前数据第二个字符是否为r
查询语句:
select substr(database(),2,1)=‘r';
select mid(database(),2,1)='r';
#正确返回1,错误返回0
其它相关函数:
01 concat(str1,str2...)
select concat("abc",NULL"fg")NULl
#返回结果为连接参数产生的字符串02 concat_ws(separator,str1,str2,...)
select concat_ws("+""123""345")123+345
#用第一个参数作为连接符号将字符串连接
03 group_concat(str1)
#将group by产生的同一个分组中的值连接起来,返回一个字符串
04 if(expr,v1,v2)select if(1<2,1,0);
#expr:条件 满足条件返回V1,不满足条件返回V2
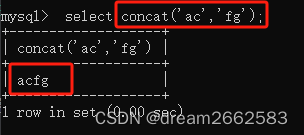
将字符连起来。
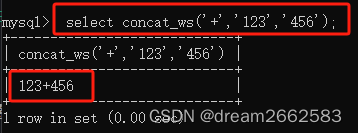
先写符号,再写数字,用第一个参数作为连接符号,将字符串连接。
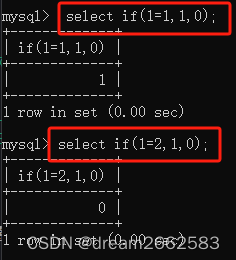
if(1=1,1,0) 1=1,结果为真,所以输出1;
if(1=2,1,0) 1=2,结果为假,所以输出0。
case when expr then v1 else v2 end
#满足expr,则返回V1,不满足则返回V2
sleep(N)
#执行select sleep(N)可以让次语句运行N秒
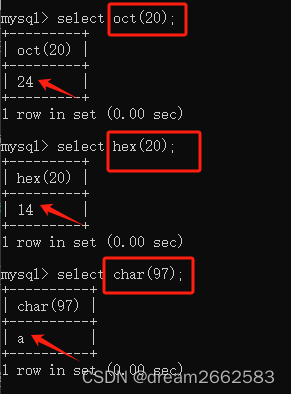
oct() #转换位8进制
ord() #返回第一个字符串的第一个字符的ascii值
hex()#转换为16进制
char()#转换为字符串
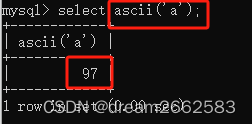
ascii() #ASCll值
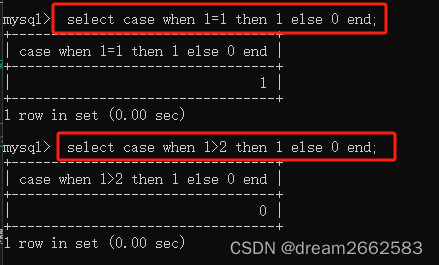
类似于if语句,
when 1-1 then 1 else 0 end
当1=1,为真输出1,否则输出0,完毕
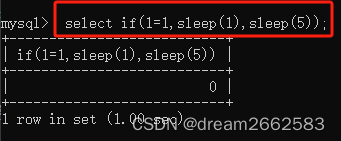
if(1=1,sleep(1),sleep(5))
如果1=1,成立,停1秒,不成立,停5秒。
数据库函数:
infomation_schema
information_schema 用于存储数据库元数据(关于数据的数据),例如数据库名、表名、列的数据类型、访问权限等。
infomation_schema.schemata infomation_schema.tables infomation_schema.cloumns
MySQL5.0版本以后才出现information_schema
其它相关函数
LOCATE('str'’str1')LOCATE(str,str1,pos)locate('a',locala',5)
#返回str在str1中第一次出现的位置 pos--从pos位置开始检索
insert(str1,pos,len,str2)
#str1:指定字符串 pos:开始被替换的位置 len:被替换字符串长度 str2:新字符串
instr(field, str)
#返回field字符串中出现str字符串的位置
position(str1 in str2)
#返回字符串中第一次出现的子字符串的位置,若没有返回0
拓展:
1. 系统函数:
原文链接:
https://blog.csdn.net/liman65727/article/details/122784725
mysql中常用的系统函数不多,主要分为时间系统函数,字符串系统函数以及一些其他的系统函数。
01 常用的时间函数
| 函数名称 | 说明 |
|---|---|
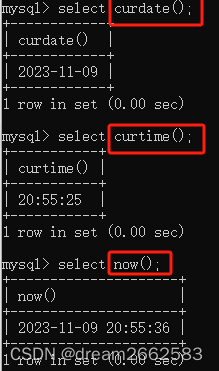
| CURDATE() | 返回当前日期 |
| CURTIME | 返回当前时间 |
| NOW() | 返回当前的日期和时间 |
02 时间计算函数
| 函数名称 | 说明 |
| SEC_TO_TIME(seconds) | 把秒数转换成为(小时:分:秒) |
| TIME_TO_SEC(time) | 把时间(小时:分:秒)转换为秒数 |
| DATEDIFF(date1,date2) | 返回date1和date2两个日期相差的天数 |
| DATE_ADD(date,INTEGER expr unit) | 对给定的日期增加或减少指定的时间单元(unit:DAY天/HOUR小时/MINUTES分钟/SECOND/秒) |
| EXTRACT(unit FROM date) | 返回日期date的指定部分 |
| UNIX_TIMESTAMP() | 返回unix的时间戳 |
| FROM_UNIXTIME() | 把unix时间戳转换为日期时间 |
把3600秒换算成小时:分:秒
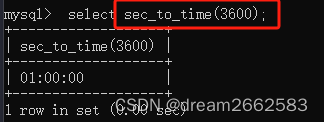
把02:30:30换算成秒数
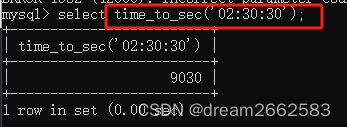
返回2023-11-09到2023-08-24两个日期相差的天数。

在今天的日期的基础上增加1天,1年,减少1天
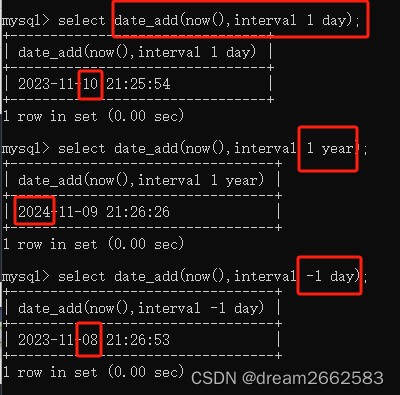
未操作的就是没有成功的,以后在回头来试一试。
03 常用的字符串函数
| 函数名称 | 说明 |
| CONCAT(str1,str2,…) | 将字符串str1,str2,…拼接成一个串 |
| CONCAT_WS(sep,str1,str2,…) | 用指定的分隔符拼接str1,str2… |
| CHAR_LENGTH(str) | 返回字符串str的字符个数 |
| LENGTH(str) | 返回字符串str的字节个数 |
| FORMAT(X,D[,locale]) | 将数字X格式化为指定的格式:"#,###,###.##",并舍入到D位小数 |
| LEFT(str,len) | 从字符串str的左边起,返回len长度的子字符串 |
| RIGHT(str,len) | 从字符串str的右边起,返回len长度的子字符串 |
| SUBSTRING(str,pos,[len]) | 从字符串str的pos位置起,返回长度为len的子串 |
| SUBSTRING_INDEX(str,delim,count) | 返回字符串str按delim分割的前count个字符串 |
| LOCATE(substr,str) | 返回substr第一次在str中出现的位置 |
| TRIM([remstr FROM] str) | 从字符串str两端删除不需要的字符remstr |
紫色部分已经学过。
以下是查abcd的长度,以及将小数1234.245874四舍五入到小数点后第四位
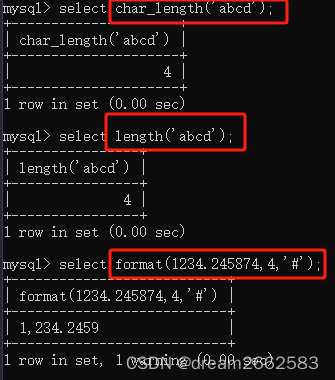
04 其他系统函数
| 函数名称 | 说明 |
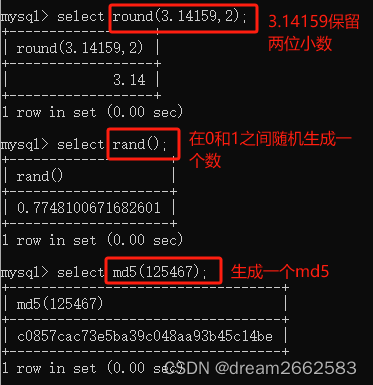
| ROUND(X,D) | 对数值X进行四舍五入保留D位小数 |
| RAND() | 返回一个在0和1之间的随机数 |
| CASE WHEN [condition] THEN result [WHEN [condition] THEN result …] [ELSE result] END | case…when,提供数据流程控制。 |
| MD5(str) | 返回str的MD5值 |
2. 截取函数
原文链接:https://blog.csdn.net/u012190388/article/details/125811876
一、字符串截取
1、函数-substr
substr 是MySQL 自带的字符串截取函数。
基本语法是 substr [str, num, length]
1.1 选项参数
str 目标字符串;
num 截取的起始位置,从 1 开始;
length 待截取的长度,省略则表示字符串的长度。
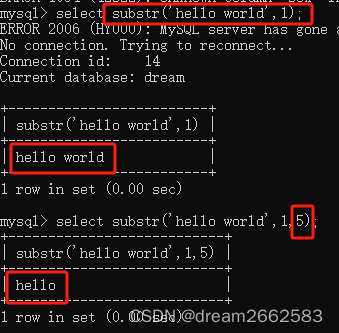
截取‘hello world’ ,截取的起始位置从第一个字母起,第一个省略了待截取长度,则表示截取整个字符串长度;
第二个写了‘5’,则表示截取5个长度的字符。















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









