







在Seq2Seq模型生成文本的decoder端,假设处于第t步,则生成的结果依赖于encoder端对输入句子的向量hidden state和先前生成的t-1个字;我们会得到一个第t个字的向量,然后通过softmax的方式得到该步时的整个vocabulary的概率分布。当前字到底生成候选词典(vocab)中的哪一个,需要一定的策略,显然遍历的复杂度较高,如何选取也会影响生成文本的质量,一些常见的优化方法如下。
一、贪心搜索
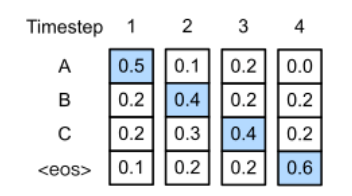
即第t+1时间步取一个词使得第1步到第t+1的概率最大,然后依次进行递进搜索。例如下图,每一个时间步都取出对应使得概率最大的词(可以联系语言模型的定义),生成了序列[A,B,C]
二、Beam Search
又称集束搜索,Beam Search(集束搜索)是一种启发式图搜索算法,通常用在图的解空间比较大的情况下,为了减少搜索所占用的空间和时间,在每一步深度扩展的时候,剪掉一些质量比较差的结点,保留下一些质量较高的结点。这样减少了空间消耗,并提高了时间效率,但缺点就是有可能存在潜在的最佳方案被丢弃,因此Beam Search算法是不完全的,一般用于解空间较大的系统中。
相对贪心策略绝大的搜索空间,我们每次选制定的个数,num_beams个;num_beams=1时集束搜索就退化成了贪心搜索;num_beams=2,即,每个时间步都会保留到当前步为止条件概率最优的2个序列。然后依次往前递推;
如下图所示,假设字典vocab是之含有A,B,C,D,E的大小为5的字典;第一步有两个候选 A,C概率最高先被选出;第二步有AA,AB,AC,AD,AE,CA,CB,…,CD,CE共10种可能,依然只选概率最高的两种,如下图是AB,CE被选出,因为这两个概率最高

三、随机采样
虽然Beam Search优化了空间效率,高效的选取了一些结点,但还是容易生成重复、无意义的文本,这点在做实验中比较容易遇到。目前提出了随机采样(sampling)的做法对Beam Search做出一些改进;候选字有一定的概率分布,通过一些策略提高生成文本的质量。比较常见的做法如下:
1.Temperature Sampling
在softmax计算过程中引入温度参数 t来改变vocabulary probability distribution,使其更偏向high probability words
P
(
x
∣
x
1
:
t
−
1
)
=
e
x
p
(
u
t
/
t
)
∑
t
′
e
x
p
(
u
t
′
/
t
)
)
P(x|x_{1:t-1})=\frac{exp(u_{t}/t)}{\sum _{{t}'}exp(u_{{t}'}/t))}
P(x∣x1:t−1)=∑t′exp(ut′/t))exp(ut/t),其中t的取值在[0,1)之间。
2.Top-k 采样
在解码过程中从
P
(
x
∣
x
1
:
i
−
1
)
P(x|x_{1:i-1})
P(x∣x1:i−1)分布中,取概率最高的k个tokens,将其概率求和记为sum-topk。概率重新分布转化如下:上述这k个tokens分别除以概率和sum-topk得到各自新的概率,其余token概率变为0。Top-k Sampling存在的问题是,常数k是给定的值,k设置过小则会容易生成更平淡或泛的句子。当k很大的时候,候选集合会包含一些不合适的token。下面的核采样方法则会有更动态的选取策略。
3.NUCLEUS SAMPLING 方法,或记为Top-p方法
主要的想法根据概率的分布来决定一个可以用来被采样的token集合。给定所有候选tokenx的分布
P
(
x
∣
x
1
:
i
−
1
)
P(x|x_{1:i-1})
P(x∣x1:i−1),这样的满足top-p条件的集合
V
(
p
)
⊂
V
V^{(p)}\subset V
V(p)⊂V。
s
u
m
x
∈
V
(
p
)
P
(
x
∣
x
1
:
i
−
1
)
≥
p
sum_{x\in V^{(p)}}P(x|x_{1:i-1})\geq p
sumx∈V(p)P(x∣x1:i−1)≥p
让
p
′
=
s
u
m
x
∈
V
(
p
)
P
(
x
∣
x
1
:
i
−
1
)
≥
p
p'=sum_{x\in V^{(p)}}P(x|x_{1:i-1})\geq p
p′=sumx∈V(p)P(x∣x1:i−1)≥p,原始的分布重新计算转化到一个新的分布如下,可以看到不在候选集里的直接概率为0,屏蔽掉了,在候选集里 的要除以这个和p’。
P
′
(
x
∣
x
1
:
i
−
1
)
=
{
P
(
x
∣
x
1
:
i
−
1
)
/
p
′
i
f
x
∈
V
(
p
)
0
o
t
h
e
r
s
i
z
e
P'(x|x_{1:i-1})=\left\{\begin{matrix} P(x|x_{1:i-1})/p'&if x\in V^{(p)}\\ 0 & othersize \end{matrix}\right.
P′(x∣x1:i−1)={P(x∣x1:i−1)/p′0ifx∈V(p)othersize
参考链接
[1]https://blog.csdn.net/hecongqing/article/details/105040105?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
[2]https://zhuanlan.zhihu.com/p/68383015
[3]The Curious Case of Neural Text Degeneration(https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1904.09751)















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









