







文章目录
补充知识
机器学习
-
神经元:在神经网络中,神经元是基本的计算单元。它接收来自其他神经元的一组输入,每个输入都有一个与之关联的权重。这些加权输入被汇总,然后传递给一个激活函数。激活函数的输出是这个神经元的输出。
-
网络层:一层由多个神经元组成,它们共同执行某种计算。例如,在全连接层中,每个神经元都与上一层的所有神经元相连。在卷积层中,每个“神经元”实际上是一个卷积滤波器,它在输入数据上滑动以生成输出特征图。
在某些复杂的网络结构中,如长短时记忆网络 (LSTM) 或门控循环单元 (GRU),计算单元更为复杂。例如,一个 LSTM 单元不仅有三个门(输入门、遗忘门和输出门),还有一个单元状态,使其能够在时间上存储和调用信息。
总的来说,在神经网络中,“计算单元”可以是一个单独的神经元、一个完整的网络层,或更复杂的结构,如 LSTM 或 GRU 单元。这些计算单元共同工作,使神经网络能够学习和表示数据中的复杂模式。
对于神经元和网络层的实现可以直接调用TensorFlow、PyTorch、Keras 等框架不需要自己具体实现
3. GLU网络 (Gated Linear Units)
GLU是一种特定的神经网络激活函数,它在某些深度学习任务中已被证明是有效的,特别是在自然语言处理领域。GLU网络的关键思想是为每个神经元引入一个门控机制,以决定该神经元的输出应该是多少。这种门控机制允许网络有选择地调整其响应。

-
Attention 机制
Attention是一种用于增强神经网络模型性能的技术,尤其是在序列到序列(seq2seq)模型中,如机器翻译。其基本思想是:在解码每个输出时,模型可以“关注”输入序列的不同部分,从而为当前的输出选择更相关的信息。
Attention机制的核心是计算一个权重分布,这些权重决定了模型在生成输出时应该“关注”输入的哪些部分。这些权重通常是通过一个简单的神经网络计算得到的,它考虑了当前的解码器状态和所有的编码器输出。
从直观上讲,当我们阅读或翻译句子时,我们不会一直关注整个句子,而是会集中注意力在某个具体的词或短语上。Attention机制就是模拟这种行为的。
总之,GLU和Attention是深度学习中两种不同的技术,但它们都在不同的场景下被证明是有效的。
5. TensorFlow
TensorFlow 是一个开源的机器学习框架,由 Google Brain 团队开发。它为研究人员和开发者提供了一个全面、灵活的工具集,用于开发各种机器学习模型,从简单的线性回归到复杂的深度学习模型。
以下是 TensorFlow 的一些特点:
- 灵活性:TensorFlow 不仅支持深度学习,还支持其他类型的机器学习算法。
- 可扩展性:可以在各种设备上运行 TensorFlow,从手机、单个CPU/GPU 到大规模的分布式系统。
- 高效性:TensorFlow 使用高效的数学库(如 cuDNN 和 Eigen)进行计算,这使得其在多种硬件上都能高效运行。
- 生态系统:TensorFlow 社区活跃,有大量的教程、工具和预训练模型可供使用。
- 可视化:TensorFlow 与 TensorBoard 配合使用,为用户提供了直观的模型可视化工具。
除此之外,TensorFlow 2.x 版本还引入了 tf.keras,这是一个简化版的接口,使得深度学习模型的开发变得更加简单和直观。
- Hugging Face
Hugging Face 是一家专注于自然语言处理 (NLP) 领域的公司,它提供了许多与深度学习和NLP相关的开源工具和资源。Hugging Face 最为人所知的产品是 Transformers 库,这是一个提供了大量预训练模型和相关工具的 Python 库,包括 BERT、GPT-2、GPT-3、T5 和其他许多流行的 NLP 模型。
以下是关于 Hugging Face 和 Transformers 的一些亮点:
-
开源和多样化:Transformers 库支持多种深度学习框架,如 PyTorch 和 TensorFlow,使得研究者和开发者能够轻松地使用和扩展。
-
大量预训练模型:Transformers 库提供了大量的预训练模型,这些模型覆盖了多种语言和多种任务,从而为用户提供了一个强大的工具集。
-
简易使用:Transformers 库的设计目标之一是易于使用,这使得无论是新手还是专家都可以轻松地利用库中的资源。
-
社区驱动:Hugging Face 社区非常活跃,用户经常分享他们的模型、研究成果和经验,这为整个NLP社区带来了巨大的价值。
-
在线平台:Hugging Face 还提供了一个在线平台,用户可以在该平台上分享、搜索和下载各种预训练模型。
-
继续教育和研究:Hugging Face 不仅提供了工具,还积极参与前沿的NLP研究,经常发布有关其最新研究成果和进展的博客文章和论文。
总的来说,Hugging Face 是 NLP 和深度学习领域的重要玩家,其 Transformers 库已经成为该领域的一个核心资源,被广大研究者和开发者所使用。
大数据有的概念
| 主 | 从 | |
|---|---|---|
| hadoop | master | slaver |
| hdfs | namenode | datanode |
| mapreduce | jobtracker | tasktracker |
| yarn | ResourceManager | nodeManager |
| spark | driver | executor |
进程和线程
进程相当于火车,线程可以理解为车厢可以共享一些资源
进程(Process)和线程(Thread)是计算机科学中关于程序执行和并发执行的两个基本概念。它们在操作系统中有着非常重要的地位。以下是它们之间的主要区别:
-
定义:
- 进程:进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位。
- 线程:线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的独立运行单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。
-
资源开销:
- 进程:进程有自己独立的地址空间,每启动一个进程,系统就会分配其独立的地址空间、数据栈以及系统资源等。进程的开销通常比线程大。
- 线程:线程之间共享同一进程的资源,所以开销小。但如果线程过多,也会影响性能。
-
通信方式:
- 进程:进程间通信(IPC)比较复杂,常见的有管道、消息队列、信号、信号量、共享内存等。
- 线程:线程间的通信更为简单,因为它们共享同一个地址空间,可以直接访问同一进程内的各种资源。
-
隔离性:
- 进程:进程间是独立的,一个进程崩溃不会影响其他进程。
- 线程:同一进程内的线程是相互依赖的,一个线程崩溃可能影响同一进程内的其他线程。
-
创建和终止:
- 进程:创建和终止进程的开销要比线程大。
- 线程:因为线程是进程的一部分,所以创建和终止线程的开销相对较小。
-
灵活性:
- 进程:相对来说,进程的切换和管理不如线程灵活。
- 线程:线程的切换和调度比进程更为迅速和高效。
-
并发性:
- 进程:在多进程操作系统中,多个进程可以并发执行。
- 线程:在多线程操作系统中,多个线程也可以并发执行,且通常线程的并发度高于进程。
线程池
线程池(Thread Pool)是一种在计算中用于执行并发任务的通用方法。它的核心思想是预先创建一定数量的线程并将它们保持在存活状态,等待分配任务执行。这样,当有新任务到来时,无需重新创建线程,而是直接从线程池中取出一个空闲线程执行该任务。
线程池的主要优势和特点如下:
-
资源重用:线程池中的线程一旦被创建,就可以被多次重用来执行多个任务,减少了线程创建和销毁的开销。
-
提高响应速度:当任务到来时,不再需要花费时间去创建线程,而是可以立即执行,因此可以提高系统的响应速度。
-
提高线程管理性:线程池可以限制系统中线程的最大数量,避免资源过度消耗。同时,管理和调度线程更为集中和方便。
-
有效控制资源:线程池可以根据系统的实际需求动态地调整线程的数量,这有助于合理地利用系统资源并防止资源浪费。
-
提供稳定性:过多的线程可能会导致系统过载,降低性能甚至导致崩溃。线程池可以设定上限,防止因为过多的线程而使系统不稳定。
线程池的常见操作包括:
-
初始化:根据指定的参数创建一个线程池,如初始线程数量、最大线程数量、等待队列大小等。
-
提交任务:将一个任务提交给线程池执行。如果线程池中有空闲线程,该任务将立即执行;否则,任务可能会被放在一个队列中等待执行。
-
关闭线程池:通常有两种关闭方式,一种是温和地关闭,等待所有任务都执行完毕后关闭;另一种是强制关闭,即立即尝试结束所有正在执行的任务并关闭线程池。
-
调整线程池大小:根据当前的任务需求,增加或减少线程池中的线程数量。
许多编程语言和框架都为开发者提供了线程池的实现或工具库,如Java的Executor框架、Python的ThreadPoolExecutor等。使用这些现成的工具可以简化并发编程的复杂性,并提高程序的性能和稳定性。
RDD
RDD 是 Resilient Distributed Dataset 弹性数据分布集的缩写,它是 Apache Spark 的核心数据结构。以下是有关 RDD 的几个关键点:
-
分布式的集合:RDD 可以看作是一个不可变的分布式对象集合。每个 RDD 可以分为多个分区,这些分区运行在集群中的不同节点上。
-
容错性:RDD 的 “Resilient” 表示它们具有容错性。即使某些任务或节点失败,Spark 也可以使用 RDD 的 lineage(血统,即它们的转换历史)来重新计算丢失的数据。
-
不可变性:一旦创建了 RDD,就不能修改它。但是,可以通过对 RDD 进行各种转换操作(例如
map、filter和reduceByKey)来产生新的 RDD。 -
转换和动作:RDD 支持两种类型的操作:转换(transformations)和动作(actions)。转换是惰性的,意味着它们不会立即执行,而是在动作被调用时执行。
-
创建:RDD 可以通过两种主要方式创建:从持久存储中的数据(例如 HDFS、本地文件系统)或通过在现有 RDD 上执行转换。
-
优化:虽然 RDD 提供了一个较底层的编程模型,但 Spark 提供了其他高级的数据结构,如
DataFrame和DataSet,它们提供了更高级的优化。尽管如此,RDD 仍然是那些需要更精细控制的应用程序的有力工具。 -
分区:数据在 RDD 中是分区的,这意味着数据被分割成多个部分,并在集群中的多个节点上并行处理。
总的来说,RDD 是 Spark 中的一个基本概念,它提供了一个高度可扩展、容错和并行处理大数据的框架。尽管在许多应用中,更高级的 DataFrame 和 DataSet API 越来越受欢迎,但 RDD 仍然是 Spark 内部和某些特定应用中的核心组件。
不存储数据
hadoop存在的问题
- shuffle过程中有大量本地磁盘io操作十分耗时
- Hadoop如果要进行数据处理只有Map和Reduce原语操作十分耗时比较单调
- Hadoop中Map task 和Reduce task都是进程,进程创造耗时,之间数据独立
MapReduce
map数据本地化,数据在哪里就在哪里执行
reduce有shuffle操作,数据按照相应的key去做聚合,这个时候会在不同机器间传输,所以耗时
spark

spark
spark的节点名称应用程序(application):用户写spark的程序,包含一个driver功能代码和分布在集群上多个executor代码
driver驱动
spark的driver运行在main函数中,并创建sparksession,负责任务的创建分配等
executor执行单元
application运行在worknode上的一个进程,该进程负责task执行,并且将数据存在内存或者磁盘上,每个application都各自独立一批executor资源池
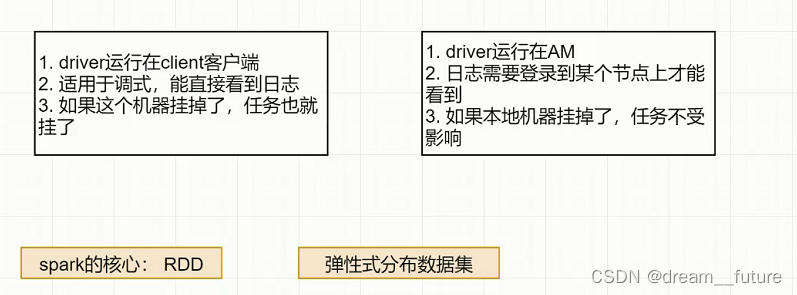
yarn-client和yarn-cluster的区别
yarn-client yarn-cluster
RDD算子
transformer和action
RDD (Resilient Distributed Dataset) 是 Apache Spark 的一个核心概念。它是一个不可变的、分布式的、并行的数据结构,用于在 Spark 集群中存储和处理数据。RDD 提供了一种高级的数据抽象,使开发者可以在大规模数据上执行函数式编程,而无需关心底层的分布式计算细节。
RDD 提供了一系列的算子,使得用户可以对数据进行各种转换和操作。这些算子大致可以分为两类:转换算子和行动算子。
-
转换算子 (Transformation)
- 这些算子返回一个新的 RDD,例如
map,filter,flatMap,groupByKey,reduceByKey等。 - 转换算子是惰性的,意味着当你调用一个转换算子时,它并不会立即执行,仅仅是被spark记录了下来而是在行动算子被调用时才会执行。
- 这些算子返回一个新的 RDD,例如
-
行动算子 (Action)
- 这些算子会返回一个非 RDD 的结果或者会有副作用(例如将数据写入外部存储),例如
count,collect,first,take,saveAsTextFile等。 - 调用行动算子会触发实际的spark作业运行真正的算子转化计算。
- 这些算子会返回一个非 RDD 的结果或者会有副作用(例如将数据写入外部存储),例如
以下是一些常见的 RDD 算子的例子:
-
转换算子:
map(func): 对每个元素应用函数并返回一个新的 RDD。filter(func): 返回一个新的 RDD,只包含满足函数条件的元素。flatMap(func): 对每个元素应用函数并返回一个新的 RDD,但是可以返回多个输出元素。union(otherRDD): 返回一个新的 RDD,包含两个 RDD 的元素。
-
行动算子:
count(): 返回 RDD 中的元素数量。collect(): 返回 RDD 中的所有元素。first(): 返回 RDD 的第一个元素。take(n): 返回 RDD 的前 n 个元素。
这只是 RDD 算子的冰山一角,实际上 Spark 提供了非常丰富的 API 来处理和分析数据。
map 和flatmap,map partition
map 应用于每一个元素,flatmap先map再平铺,map partition作用于每一个分区,对大数据处理尽量用map partition
map 实际输入是元素,map partition 输入的是迭代器
val nums = List(1, 2, 3)
val squaredAndOriginal = nums.flatMap(x => List(x, x * x)) // 结果:List(1, 1, 2, 4, 3, 9)
val rdd = sc.parallelize(List("1,2,3", "4,5", "6,7,8,9"))
val numbers = rdd.flatMap(line => line.split(",")) // 结果:每个元素都是一个单独的数字
map partition
优势
处理大数据集的情况下,比如元素个数远大于分区个数
- map partition开销比较小
- 便于进行批处理操作
劣势
如果一个partition有很多数据可能导致OOM(Out Of Memory 内存溢出)而map不会
partitionByKey
这个是Scala对spark操作的一个函数
在 reduceByKey 的上下文中,当使用函数 lambda a, b: a + b 时,a 和 b 都是值(value)。具体来说,它们是具有相同键的两个值。
可以理解为一个是累加,另一个是下一个值的概念也是正确的,尤其是在多次调用合并函数时。当 reduceByKey 开始聚合具有相同键的值时,它会两两取值进行合并。一旦合并了一对值,结果可能会与下一个值再次合并,如此往复,直到该键的所有值都被合并为一个单一的结果。
举个例子,考虑以下的键值对:
(“apple”, 1), (“apple”, 1), (“apple”, 1)
当调用 reduceByKey(lambda a, b: a + b) 时:
- 首先,可能会取前两个值:
a = 1和b = 1。合并结果为2。 - 接下来,这个合并的结果
2(此时作为a)可能会与下一个值1(作为b)合并。最终结果为3。
所以,你可以把 a 看作是到目前为止的累积结果,而 b 是下一个待合并的值。但在函数的每次调用中,a 和 b 都只是两个值,而不涉及它们在整个合并过程中的具体位置或状态。
怎么进入spark的shell
spark-shell
输入这个就可以进入spark的Scala REPL,
当你启动 spark-shell,它会自动为你创建一个名为 sc 的 SparkContext 实例。这是 Spark 的入口点,允许你执行各种操作,如创建 RDDs。
除了 sc,spark-shell 还为你创建了一个名为 spark 的 SparkSession 实例。这是 Spark 2.x 版本引入的,它提供了一个统一的入口点来使用 Spark 的各种功能,如 DataFrame 和 Dataset API。
退出时输入:q退出















 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









