







我们上一片了解了Criterion是用来增加where的约束的,但是我们都知道sql中还有max,min,avg等这种对结果集字段进行约束的函数。那Criteria中,又该怎样呢?
查看文档或源码,看到Criteria中提供了public Criteria setProjection(Projection projection);用来对结果集字段进行进一步处理。Projection 是接口,我们可以使用Projections中的静态方法。
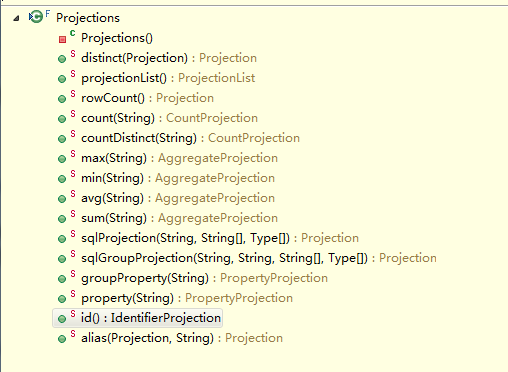
可以看到Projections中都提供了sum,max,min等常用的sql函数。
/**
*select max(s.age)
*from student s
*join grade g on g.id = s.grade_id
*where g.name='高一'
*
*/
@Test
public void testQuery(){
Session session = sf.openSession();
Criteria criteria = session.createCriteria(Student.class);
criteria.createAlias("grade","g");//对Student类中的grade使用别名,这样g.name时就知道是grade中的name,而不是student中的name
criteria.add(Restrictions.eq("g.name", "高一"))
.setProjection(Projections.max("age"));
int maxAge =(Integer) criteria.uniqueResult();
System.out.println("高一最大的年龄是"+maxAge);
session.close();
}对其他的一些用法,就不想一一敲代码验证了。从网上找了下,copy过来。
Hibernate的Projections工厂类包含了以下几个常用的统计函数:
① avg(String propertyName):计算属性字段的平均值。
② count(String propertyName):统计一个属性在结果中出现的次数。
③ countDistinct(String propertyName):统计属性包含的不重复值的数量。
④ max(String propertyName):计算属性值的最大值。
⑤ min(String propertyName):计算属性值的最小值。
⑥ sum(String propertyName):计算属性值的总和。
下面的示例演示了一些统计函数和投影列表的使用方法:
getSession().beginTransaction();
Criteria Crit = getSession().createCriteria(Product.class);
ProjectionList projList = Projections.projectionList();
projList.add(Projections.max("price"));
projList.add(Projections.min("price"));
projList.add(Projections.avg("price"));
projList.add(Projections.countDistinct("description"));
Crit.setProjection(projList);
List result = Crit.list();
getSession().getTransaction().commit();
上述示例执行了多个统计投影。当执行多个统计投影时,会获取一个List,并且是一个Object类型的List,其中依次包含所有的统计投影结果。
使用投影的一个好处就是,获得的结果是单独的属性而不是实体类。例如,一个产品表中包含有很多字段,我们想要获取产品表中的名称和描述,而不需要将完整的实体加载到内存中。
Criteria Crit = getSession().createCriteria(Product.class);
ProjectionList projList = Projections.projectionList();
projList.add(Projections.property("name"));
projList.add(Projections.property("description"));
Crit.setProjection(projList);
List result = Crit.list();
使用这种查询风格可以减少应用服务器和数据库服务器之间的网络通信量。但是,如果客户机的内存容量的确是有限的,那么这种查询方式可以避免处理大型数据集对内存的压力。如果不确定以后是否需要一个完整的结果集,这得要执行另外一次查询,反而降低了查询性能。所以只能在适当的时候才使用Hibernate的投影功能。
那么如何获得结果集中的不重复的结果呢?方法为:
distinct(Projection proj):统计属性的不重复值。
getSession().beginTransaction();
Criteria criteria = getSession().createCriteria(Transaction.class);
ProjectionList proList = Projections.projectionList();
proList.add(Projections.distinct(Projections.property("module")));
criteria.setProjection(proList);
criteria.addOrder(Order.asc("orderSign"));
list = criteria.list();
getSession().getTransaction().commit();
最后,可以使用groupProperty投影对结果集进行分组(使用SQL的GROUP BY子句)。下面的示例安装名称和价格对产品进行分组:
Criteria Crit = getSession().createCriteria(Product.class);
ProjectionList projList = Projections.projectionList();
projList.add(Projections.groupProperty("name"));
projList.add(Projections.groupProperty("price"));
Crit.setProjection(projList);
List result = Crit.list();















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









