







我们在“hadoop学习1--hadoop2.7.3集群环境搭建” “spark学习1--centOS7.2下基于hadoop2.7.3的spark2.0集群环境搭建” 中已经将hadoop、spark的集群环境都搭建起来了,jdk用的是1.7版本的。
1.启动hadoop集群
centOS7服务器3台
master 192.168.174.132
node1 192.168.174.133
node2 192.168.174.134
启动这3台虚拟机,在这3台虚拟机上执行jps,发现都还没启动hadoop

在master上启动hadoop

看启动日志,发现node1,node2也跟着启动了,在master,node1,node2虚拟机上执行jps会发现相关的进程启动了
[root@master sbin]# jps
2354 NameNode
2539 SecondaryNameNode
2947 Jps
2690 ResourceManager
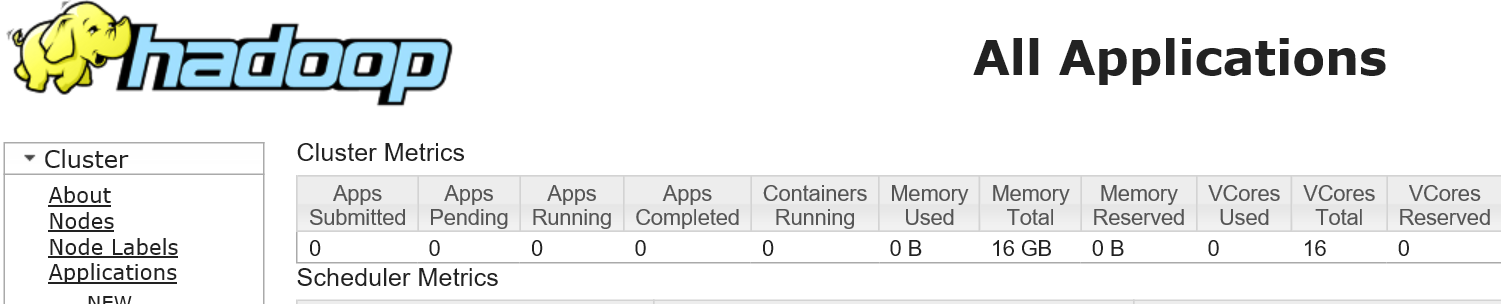
2.上传单词文件到hadoop
master上执行
[root@master /]# hadoop fs -ls /
[root@master /]#
[root@master /]# hadoop fs -mkdir /wc_input
[root@master /]# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2017-11-13 15:17 /wc_input
[root@master /]#
[root@master /]# hadoop fs -put /words.txt /wc_input
[root@master /]# hadoop fs -ls /wc_input
Found 1 items
-rw-r--r-- 2 root supergroup 2190 2017-11-13 15:20 /wc_input/words.txt
[root@master /]#
3.启动spark集群
在master上执行
[root@master /]# $SPARK_HOME/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /soft/spark/spark-2.0.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
node2: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/spark-2.0.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node2.out
node1: starting org.apache.spark.deploy.worker.Worker, logging to /soft/spark/spark-2.0.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node1.out
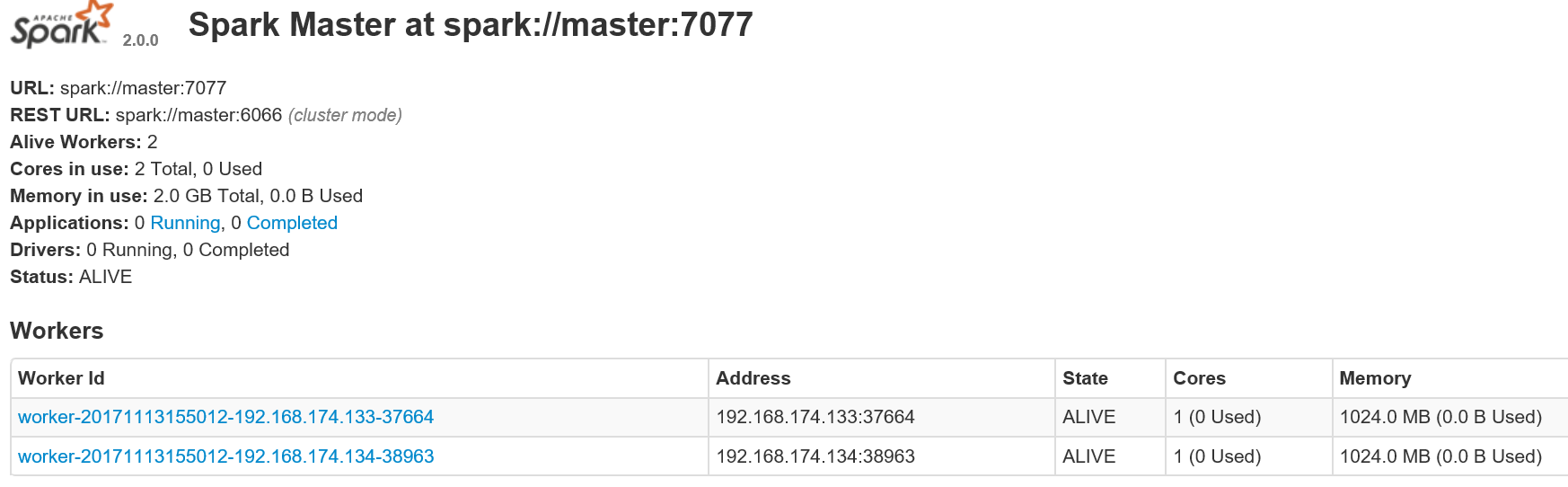
3.代码打包
将代码稍微修改下,能读取外面传进去的参数;由于spark环境搭建的时候,jdk用的是1.7版本,所以不能用lambda表达式。
package com.fei;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
/**
* 单词统计,并按降序排序,输出前10个单词及个数
* @author Jfei
*
*/
public class WordCount {
public static void main(String[] args) {
System.out.println(args[0]);
System.out.println(args[1]);
System.out.println(args[2]);
//1.本地模式,创建spark配置及上下文
// SparkConf conf = new SparkConf().setAppName("wordCount").setMaster("spark://192.168.174.132:7077");
SparkConf conf = new SparkConf().setAppName("wordCount").setMaster(args[0]);
JavaSparkContext sc = new JavaSparkContext(conf);
//2.读取本地文件,并创建RDD
// JavaRDD<String> linesRDD = sc.textFile("e:\\words.txt");
// JavaRDD<String> linesRDD = sc.textFile("hdfs://192.168.174.132:9000/wc_input");
JavaRDD<String> linesRDD = sc.textFile(args[1]);
//3.每个单词由空格隔开,将每行的linesRDD拆分为每个单词的RDD
// JavaRDD<String> wordsRDD = linesRDD.flatMap(s -> Arrays.asList(s.split("\\s")));
//相当于 ==>
JavaRDD<String> wordsRDD = linesRDD.flatMap(new FlatMapFunction<String, String>(){
private static final long serialVersionUID = 1L;
@SuppressWarnings("unchecked")
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).listIterator();
}
});
//4.将每个单词转为key-value的RDD,并给每个单词计数为1
//JavaPairRDD<String,Integer> wordsPairRDD = wordsRDD.mapToPair(s -> new Tuple2<String,Integer>(s, 1));
//相当于 ==>
JavaPairRDD<String,Integer> wordsPairRDD = wordsRDD.mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String,Integer>(word,1);
}
});
//5.计算每个单词出现的次数
//JavaPairRDD<String,Integer> wordsCountRDD = wordsPairRDD.reduceByKey((a,b) -> a+b);
//相当于 ==>
JavaPairRDD<String,Integer> wordsCountRDD = wordsPairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//6.因为只能对key进行排序,所以需要将wordsCountRDD进行key-value倒置,返回新的RDD
// JavaPairRDD<Integer,String> wordsCountRDD2 = wordsCountRDD.mapToPair(s -> new Tuple2<Integer,String>(s._2, s._1));
//相当于 ==>
JavaPairRDD<Integer,String> wordsCountRDD2 = wordsCountRDD.mapToPair(new PairFunction<Tuple2<String,Integer>, Integer, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> t) throws Exception {
return new Tuple2<Integer,String>(t._2,t._1);
}
});
//7.对wordsCountRDD2进行排序,降序desc
JavaPairRDD<Integer,String> wordsCountRDD3 = wordsCountRDD2.sortByKey(false);
//8.只取前10个
List<Tuple2<Integer, String>> result = wordsCountRDD3.take(10);
//9.打印
// result.forEach(t -> System.out.println(t._2 + " " + t._1));
for(Tuple2<Integer, String> t : result){
System.out.println(t._2 + " " + t._1);
}
//10.将结果保存到文件中
wordsCountRDD3.saveAsTextFile(args[2]);
sc.close();
}
}
4.测试
将jar包上传到spark的master服务器192.168.174.132,并创建一个wc.sh文件

编辑wc.sh

执行wc.sh
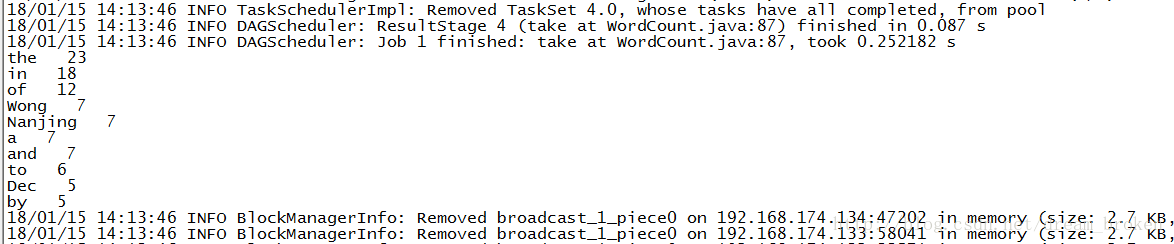
看到日志输出
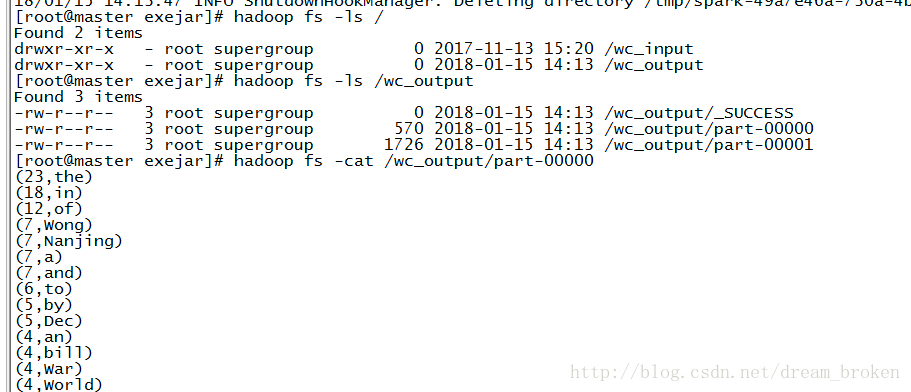
查看hadoop中的文件
看到有/wc_output文件夹,下面有3个文件,查看part-0000文件,看到完整的统计信息
在界面查看hadoop的文件http://192.168.174.132:50070/
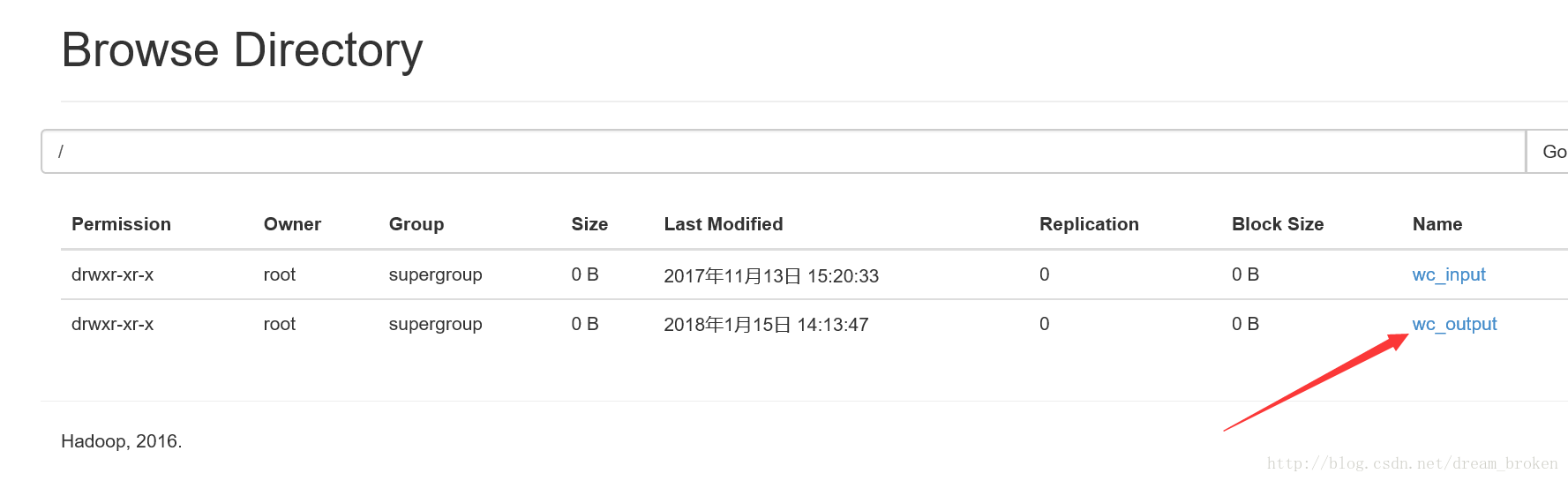
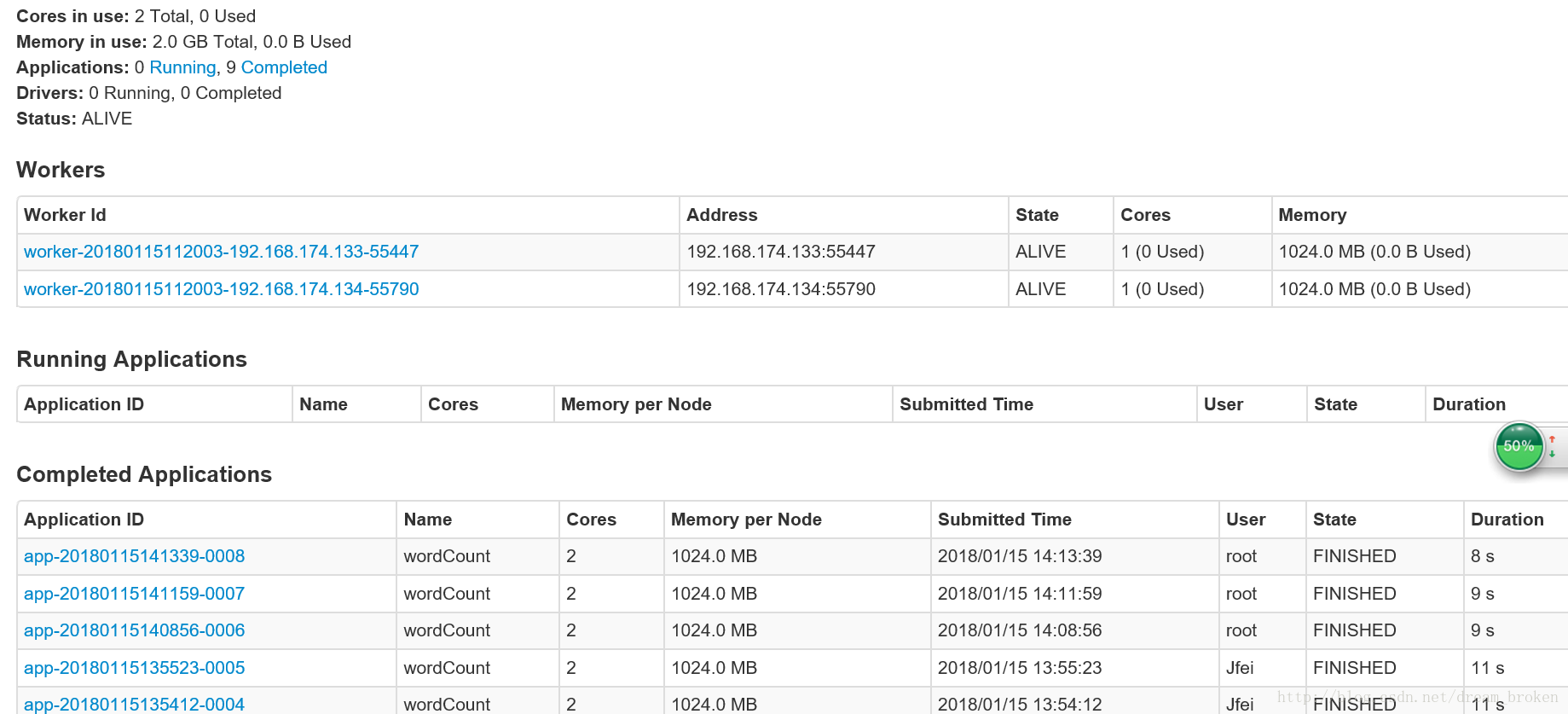
查看sparkhttp://192.168.174.132:8080/#completed-app















 4502
4502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









