







一、引言
上一遍文章中我详细讲解Collection体系结构和每个集合类的实现原理、用法以及区别。整个Java集合框架分为Collection接口和Map接口两个根接口。从接口的定义上看,Collection和Map没有直接联系,但其实内部关系很大,具体怎么联系的这是本文讲解的一个重点。在讲解Map之前先来学习一下一个数据结构——哈希表。
哈希表查找的基本思想:建立关键字和存储位置的函数H,以关键字key为自变量,对应的函数值H(key)作为存储地址把记录存储到相应位置。查找时,根据关键字通过哈希函数计算出带查找记录的存储位置。由此建立一张表叫哈希表(哈希表是Hash的音译,学名叫散列表)。先来看一下,怎么构造哈希表,现有一组数据S={18,75,60,43,54,90,46,67}
若哈希函数H(key)=key%13,哈希表的构造过程就是就哈希值的过程,18%13=5,75%13=10,60%13=8以此类推,建立哈希表H如下:

如果要查找60,就再次计算哈希值H(key)=60%13=8,说明哈希表H[8]存放的60。但是先有个问题就是H[2]中有两个值54和67,因为这两个值计算所得的哈希值都是2,像这种对于不同的key,得到相同的哈希值,即H(key1)=H(key2),这种现象称为冲突,发生冲突的关键字key称作同义词。同一个位置不能存放多个值,这时就需要办法处理冲突,解决冲突的方法有很多,这里只介绍HashMap中用到的方法——链地址法(又称拉链法)。链地址法是指将所有的关键字为同义词的记录链接成一个线性表,而其链表头存储在相应的哈希地址对应的存储单元中。如下图:
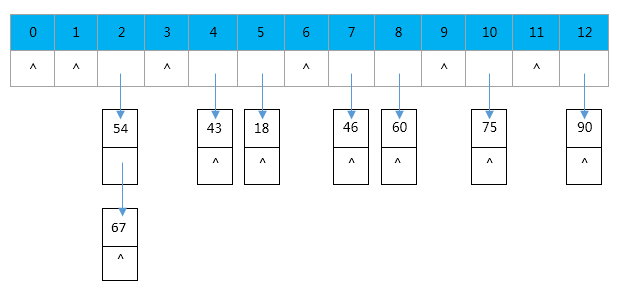
哈希表不是重点,就讲这么多吧,不懂的去看数据结构。为什么要将哈希表呢,因为HashMap内部就是用的这种数据结构,理解了这个你更容易理HashMap的源码。
二、Map集合框架介绍
先来看一下Map集合框架图:
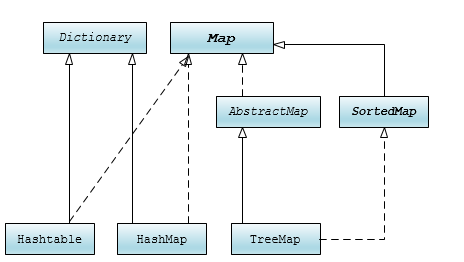
和Collection框架结构有相似之处,顶层Map根接口,中间AbstractMap部分实现和SortedMap子接口,最后是三个具体集合类。最上层还有一个Dictionary,这是个抽象类,和其子类HashTable都是Java 1.0就有了,到Java1.2有了集合框架后就象征性的implements Map。Dictionary类中全是抽象方法,没有任何实现,所以就用Map接口代替了。
三、Map集合类的实现原理
1、HashMap
HashMap底层数据结构是哈希表+单链表,我们通过阅读源码(JDK1.7)详细了解一下具体这个HashMap是怎么实现的。
先来看一下HashMap中都有哪些基本属性(注释做初步解释):
//默认初始容量16,其值一定是2的幂
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 最大容量2的30次方,如果大于这个值,就被这个值替换
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认装载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//空的Entry数组,Entry是内部接口,后面会讲。
static final Entry<?,?>[] EMPTY_TABLE = {};
//这个就是HashMap的哈希表,大小根据需要自动扩充。
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
.
// 键值对的数量
transient int size;
// Entry数组需要调整大小的一个极限值(容量*装载因子),容量达到这个值就需要扩充,这个值也会随之改变。
int threshold;
//哈希表的装载因子,这个值可以自定义。
final float loadFactor;
/**
* 哈希表结构修改的次数,主要在使用fail-fast迭代器(相对于ListIterator)时,
* 不允许对当前迭代元素作出修改(remove OR add)
*/
transient int modCount; /**
* 用初始容量16和默认装载因子0.75创建一个哈希表 ,threshold=16*0.75=12
* 当哈希表容量达到12时就会自动扩充
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
哈希表table是一个Entry<K,V>[]数组,那么Entry又是什么,原来Map在
实际存储中Map把(Key,Value)看成一个整体,所以定义了一个内部类Entry,重点看一下Entry:
//实现了Map接口的子接口Entry<K,V>
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
/**
* 这里就是开头部分讲的Hash表冲突时用链地址法解决冲突
* HashTable中的一个单元存储时每个哈希值得表头,相同的哈希值组成一个单链表
* next指向下一个Entry
*/
Entry<K,V> next;
int hash;
//创建一个新的Entry
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
//key相等且value相等
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
//Entry的哈希值等于key的哈希值异或value的哈希值,为什么这么算,就不懂了
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
//这两个估计是以后扩展用方法,还没内容
void recordAccess(HashMap<K,V> m) {
}
void recordRemoval(HashMap<K,V> m) {
}
} //如果key已经存在,则原来的value会被新的替换,并返原来的value
public V put(K key, V value) {
//如果哈希表为空,则用极限值扩充
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//HashMap只允许一个Null key
if (key == null)
return putForNullKey(value);
//添加不为null的key
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
} final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
} static int indexFor(int h, int length) {
return h & (length-1);
} void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
} void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
最后我们有一个遗留问题,就是当key=null时:
private V putForNullKey(V value) {
//table[0] 说明哈希表的第一个单元存的null key
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
到此为止,一个<key,Value>就添加完成了。有点绕!多读几遍,慢慢理解!
HashMap的检索过程就是再把添加过程再来一遍,就不再啰嗦了,其他常用的方法,以后慢慢再说,这里一个HashMap用了太多篇幅。
为了更直观的感受一下,我画了下面一张图,来大体表示一下HashMap的内部结构:
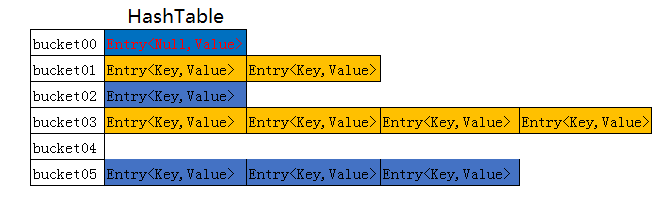
一个Bucket是指后面这一行,也就是一个单向链表,同一个Bucket中的Entry的hashcode是相同的。所有单链表的表头就组成了这张哈希表。现在我们总结一下HashMap的特点:
HashMap结合了数组和链表的有点,兼顾了检索速度和增删速度,但是检索不如数组,增删不如链表。
2、HashTable
HashTable和HashMap的关系就像ArrayList和Vector差不多,HashTable是Map的重量级实现,是线程同步的,还有就是HashTable不允许Null key,除此之外在实现原理和功能上和HashMap大致相同,不再赘述。
3、TreeMap
TreeMap底层红黑树实现的,红黑树的本质就是数组+二叉树,在检索、增删的性能上介于数组和链表之间,和哈希表各有优缺点,红黑树的原理要比哈希表负责一点,涉及到二叉树的遍历等问题,在以后的文章中再单独详解,这里就略过了。除了数据结构不同之外,在功能逻辑上和HashMap是差不多的。首先看一下TreeMap中的基本属性有哪些:
//给节点排序的比较器,如果为Null,就用自然排序
private final Comparator<? super K> comparator;
//树的根节点
private transient Entry<K,V> root = null;
private transient int size = 0;
private transient int modCount = 0;
//不提供比较器构造TreeMap
public TreeMap() {
comparator = null;
}
//给TreeMap提供一个比较器
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}TreeMap属性很简单,主要是一个root根节点和一个比较器。再来看一下TreeMap内部的Entry怎么定义的:
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left = null;
Entry<K,V> right = null;
Entry<K,V> parent;
boolean color = BLACK;
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}典型的节点对象,左子树、右子树和双亲节点,在构造Entry时只需提供<key,Value>和双亲节点就行了。TreeMap的一大特点就是可以排序,建立红黑树的过程就是Entry排序的过程,所以TreeMap提供了很多类似ceilingKey(K key)、floorKey(K key)判断元素大小的方法,使用起来很方便。还有一点 与HashMap不同的是,TreeMap不允许key=null,会抛出空指针异常。
三、Map集合Set集合的关系
Map和Set的关系非常密切,可谓是你中有我,我中有你!先来看看Map中最常用的三个方法:
public Set<K> keySet() {
Set<K> ks = keySet;
return (ks != null ? ks : (keySet = new KeySet()));
}
public Set<Map.Entry<K,V>> entrySet() {
return entrySet0();
}
public Collection<V> values() {
Collection<V> vs = values;
return (vs != null ? vs : (values = new Values()));
} private final class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return newKeyIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
return HashMap.this.removeEntryForKey(o) != null;
}
public void clear() {
HashMap.this.clear();
}
} Iterator<K> newKeyIterator() {
return new KeyIterator();
}
private final class KeyIterator extends HashIterator<K> {
public K next() {
return nextEntry().getKey();
}
}
再来看一下HashSet的实现原理:
//创建一个HashMap集合
private transient HashMap<E,Object> map;
//用一个Object对象虚拟一个value
private static final Object PRESENT = new Object();
//创建一个空的Set,其实就是创建了一个HashMap
public HashSet() {
map = new HashMap<>();
}
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public boolean isEmpty() {
return map.isEmpty();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
//添加时,value值为虚拟值PRESENT
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
学到这里,你再回头看看那张复杂的Java集合框架图,是不是感觉很简单了,其实你只需要学四个集合ArrayList、LinkedList、HashMap和TreeMap,了解了他们内部的实现原理也就理清他们之间的关系和区别,这就是开源的好处,可以让你走进Java工程师的世界。
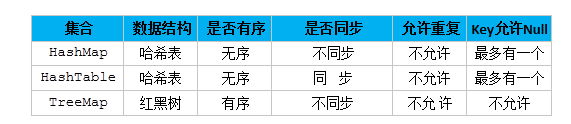
四、Map集合特点比较















 2220
2220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









