










TIM阅读笔记
Boudiaf M, Masud Z I, Rony J, et al. Transductive information maximization for few-shot learning[J]. arXiv preprint arXiv:2008.11297, 2020.
昨天下午出去蹦跶去了,今天来赶工。今天这篇论文是 NeurIPS 2020 的一个工作,乍一看还是一个Tim?腾讯的那个?不是哈哈哈,Transductive Information Maximization For Few-Shot Learning,这篇文章上周看的时候脑子基本上就是蒙的,很多东西都忘了,下来补了一下信息论基础和前天那篇先验工作才能勉强看懂,可能有很多不足的地方,欢迎大佬指正啊。
一些pre-knowledge
Transductive Learning
这个其实我都不知道怎么翻译,这方面的工作近两年在FSL领域比较火,明天会出一篇这个相关的paper,这里简单的介绍一下,注意不要把这个和半监督学习搞混了。
监督学习中的train和test集是不交叉的,这种叫做inductive learning。
半监督学习中我们添加了额外的未标记数据辅助训练,它的train和test集依然是不交叉的,叫做inductive semi-supervise learning。
假设我们添加的这部分未标注的数据部分或者全部来自test set,那么这时候很明显train和test就相交了,这种叫做transductive learning。
文章主要思想
这篇文章其实就是上一篇文章在FSL领域的一次应用,这篇文章也是希望通过最大化输入和输出之间的互信息,这里的输入指的是embed后的query feature,输出指的是label,这个前天那篇文章提到的思想很相似。作者采用了交替方向乘子法solver( alternating-direction solver ,不知道怎么翻译)来加速推理,也能够提升精度。
Details
这里author还是采用了两阶段metrics learning的方式来做,首先是一个feature extractor: f ϕ : X ⟶ Z ⊂ R d f_{\phi}: \mathcal{X} \longrightarrow \mathcal{Z} \subset \mathbb{R}^{d} fϕ:X⟶Z⊂Rd,作者对这个特征向量 Z \mathcal{Z} Z也做了normalization: z i = f ϕ ( x i ) ∥ f ϕ ( x i ) ∥ 2 \boldsymbol{z}_{i}=\frac{f_{\boldsymbol{\phi}}\left(\boldsymbol{x}_{i}\right)}{\left\|f_{\boldsymbol{\phi}}\left(\boldsymbol{x}_{i}\right)\right\|_{2}} zi=∥fϕ(xi)∥2fϕ(xi),对于分类器作者直接选择了一个soft分类器,直接将利用一个权重矩阵对输出特征进行映射,那么对于第i个样本标签为k的概率分布就为: p i k : = P ( Y = k ∣ X = x i ; W , ϕ ) p_{i k}:=\mathbb{P}\left(Y=k \mid X=\boldsymbol{x}_{i} ; \mathbf{W}, \boldsymbol{\phi}\right) pik:=P(Y=k∣X=xi;W,ϕ)。中间变量 Z \mathcal{Z} Z是一个d维的向量, p i k p_{ik} pik表示第i个样本为标签k的概率,那么在权重分类上就相当于是特征向量 Z \mathcal{Z} Z乘以对应第k个权重向量 w k w_k wk,那么 p i k ∝ exp ( − τ 2 ∥ w k − z i ∥ 2 ) p_{i k} \propto \exp \left(-\frac{\tau}{2}\left\|\boldsymbol{w}_{k}-\boldsymbol{z}_{i}\right\|^{2}\right) pik∝exp(−2τ∥wk−zi∥2),其中这个 τ \tau τ是一个温度参数,那么$p_{i k} 在 q u e r y s e t 上 的 边 缘 分 布 为 在query set上的边缘分布为 在queryset上的边缘分布为\widehat{p}{k}=\frac{1}{|\mathcal{Q}|} \sum\limits{ i \in \mathcal{Q}} p_{i k}$,
按照我们的目标就是最大化这个输入输出之间的互信息,作者将它定义为下面所示的样子:
I
^
α
(
X
Q
;
Y
Q
)
:
=
−
∑
k
=
1
K
p
^
k
log
p
^
k
⏟
H
^
(
Y
Q
)
:
marginal entropy
+
α
1
∣
Q
∣
∑
i
∈
Q
∑
k
=
1
K
p
i
k
log
(
p
i
k
)
⏟
−
H
^
(
Y
Q
∣
X
Q
)
:
conditional entropy
\widehat{\mathcal{I}}_{\alpha}\left(X_{\mathcal{Q}} ; Y_{\mathcal{Q}}\right):=\underbrace{-\sum_{k=1}^{K} \widehat{p}_{k} \log \widehat{p}_{k}}_{\widehat{\mathcal{H}}\left(Y_{\mathcal{Q}}\right): \text { marginal entropy }}+\alpha \underbrace{\frac{1}{|\mathcal{Q}|} \sum_{i \in \mathcal{Q}} \sum_{k=1}^{K} p_{i k} \log \left(p_{i k}\right)}_{-\widehat{\mathcal{H}}\left(Y_{\mathcal{Q}} \mid X_{\mathcal{Q}}\right): \text { conditional entropy }}
I
α(XQ;YQ):=H
(YQ): marginal entropy
−k=1∑Kp
klogp
k+α−H
(YQ∣XQ): conditional entropy
∣Q∣1i∈Q∑k=1∑Kpiklog(pik)
这是不是认不到为什么这样设计???这就是前面我们的互信息啊,前面是 H ^ ( Y Q ) \hat{H}(Y_Q) H^(YQ),后面是 H ^ ( Y Q ∣ X Q ) \hat{H}(Y_Q|X_Q) H^(YQ∣XQ),这一部分是 P ( Y Q ∣ X Q ) P(Y_Q|X_Q) P(YQ∣XQ)条件熵,熵是不确定性的期望。熵越大,变量的不确定性越大,也就是说我们要最小化query set中无标签数据的后验概率,从数学公式上讲,被减数不变,减数减小了,差肯定变大。去年的ICLR上也有一片类似的工作就单独只用了这一部分作为损失函数,这一部分很重要。由互信息的定义可得,这两者的差就是互信息。作者加了一个正则项 α \alpha α,如果 α = 1 \alpha=1 α=1就是原本的互信息。
但是你发现没,即使到这个时候我们也只是利用了query set的信息,别忘了FSL本质上还是Supervised learning,support set仍然可以提供监督信息,于是在loss中还添加了一个CE来保证监督信息的编码,我们需要最小化CE,最大化互信息,为了保证训练的一致性,我们把互信息作相反数,与CE相加。
作者选用的特征提取板块是预训练的模型,除了使用梯度下降,作者还提出了一种优化方案ADMM,作者提出这种方案能过够极大程度提高模型的速度。思路是在原始的loss上加了一个正则项,就是p,q的KL散度,即当前的损失函数就变成了:
min
W
,
q
−
λ
∣
S
∣
∑
i
∈
S
∑
k
=
1
K
y
i
k
log
(
p
i
k
)
⏟
C
E
+
∑
k
=
1
K
q
^
k
log
q
^
k
⏟
∼
H
^
(
Y
Q
)
α
∣
Q
∣
∑
i
∈
Q
∑
k
=
1
K
q
i
k
log
(
p
i
k
)
⏟
∼
H
^
(
Y
Q
∣
X
Q
)
+
1
∣
Q
∣
∑
i
∈
Q
∑
k
=
1
K
q
i
k
log
q
i
k
p
i
k
⏟
Penalty
≡
D
K
L
(
q
∥
p
)
\min _{\mathbf{W}, \boldsymbol{q}} \underbrace{-\frac{\lambda}{|\mathcal{S}|} \sum_{i \in \mathcal{S}} \sum_{k=1}^{K} y_{i k} \log \left(p_{i k}\right)}_{\mathrm{CE}}+\underbrace{\sum_{k=1}^{K} \widehat{q}_{k} \log \widehat{q}_{k}}_{\sim \widehat{\mathcal{H}}\left(Y_{\mathcal{Q}}\right)} \underbrace{\frac{\alpha}{|\mathcal{Q}|} \sum_{i \in \mathcal{Q}} \sum_{k=1}^{K} q_{i k} \log \left(p_{i k}\right)}_{\sim \widehat{\mathcal{H}}\left(Y_{\mathcal{Q}} \mid X_{\mathcal{Q}}\right)}+\underbrace{\frac{1}{|\mathcal{Q}|} \sum_{i \in \mathcal{Q}} \sum_{k=1}^{K} q_{i k} \log \frac{q_{i k}}{p_{i k}}}_{\text {Penalty } \equiv \mathcal{D}_{\mathrm{KL}}(\mathbf{q} \| \mathbf{p})}
W,qminCE
−∣S∣λi∈S∑k=1∑Kyiklog(pik)+∼H
(YQ)
k=1∑Kq
klogq
k∼H
(YQ∣XQ)
∣Q∣αi∈Q∑k=1∑Kqiklog(pik)+Penalty ≡DKL(q∥p)
∣Q∣1i∈Q∑k=1∑Kqiklogpikqik
当且仅当,
q
i
,
k
=
p
i
,
k
q_{i,k}=p_{i,k}
qi,k=pi,k的时候散度为0,然后ADMM的思路是将这个问题尝试分割成基于W,q的两个子问题,如下所示。作者在论文中给出了形式化的证明,网上也有很多关于ADMM在凸优化领域的介绍,这里不再赘述。
q
i
k
(
t
+
1
)
∝
(
p
i
k
(
t
)
)
1
+
α
(
∑
i
∈
Q
(
p
i
k
(
t
)
)
1
+
α
)
1
/
2
w
k
(
t
+
1
)
←
λ
1
+
α
∑
i
∈
S
(
y
i
k
z
i
+
p
i
k
(
t
)
(
w
k
(
t
)
−
z
i
)
)
+
∣
S
∣
∣
Q
∣
∑
i
∈
Q
(
q
i
k
(
t
+
1
)
z
i
+
p
i
k
(
t
)
(
w
k
(
t
)
−
z
i
)
)
λ
1
+
α
∑
i
∈
S
y
i
k
+
∣
S
∣
∣
Q
∣
∑
i
∈
Q
q
i
k
(
t
+
1
)
\begin{array}{l} q_{i k}^{(t+1)} \propto \frac{\left(p_{i k}^{(t)}\right)^{1+\alpha}}{\left(\sum_{i \in \mathcal{Q}}\left(p_{i k}^{(t)}\right)^{1+\alpha}\right)^{1 / 2}} \\ \boldsymbol{w}_{k}^{(t+1)} \leftarrow \frac{\frac{\lambda}{1+\alpha} \sum_{i \in \mathcal{S}}\left(y_{i k} \boldsymbol{z}_{i}+p_{i k}^{(t)}\left(\boldsymbol{w}_{k}^{(t)}-\boldsymbol{z}_{i}\right)\right)+\frac{|\mathcal{S}|}{|\mathcal{Q}|} \sum_{i \in \mathcal{Q}}\left(q_{i k}^{(t+1)} \boldsymbol{z}_{i}+p_{i k}^{(t)}\left(\boldsymbol{w}_{k}^{(t)}-\boldsymbol{z}_{i}\right)\right)}{\frac{\lambda}{1+\alpha} \sum_{i \in \mathcal{S}} y_{i k}+\frac{|\mathcal{S}|}{|\mathcal{Q}|} \sum_{i \in \mathcal{Q}} q_{i k}^{(t+1)}} \end{array}
qik(t+1)∝(∑i∈Q(pik(t))1+α)1/2(pik(t))1+αwk(t+1)←1+αλ∑i∈Syik+∣Q∣∣S∣∑i∈Qqik(t+1)1+αλ∑i∈S(yikzi+pik(t)(wk(t)−zi))+∣Q∣∣S∣∑i∈Q(qik(t+1)zi+pik(t)(wk(t)−zi))
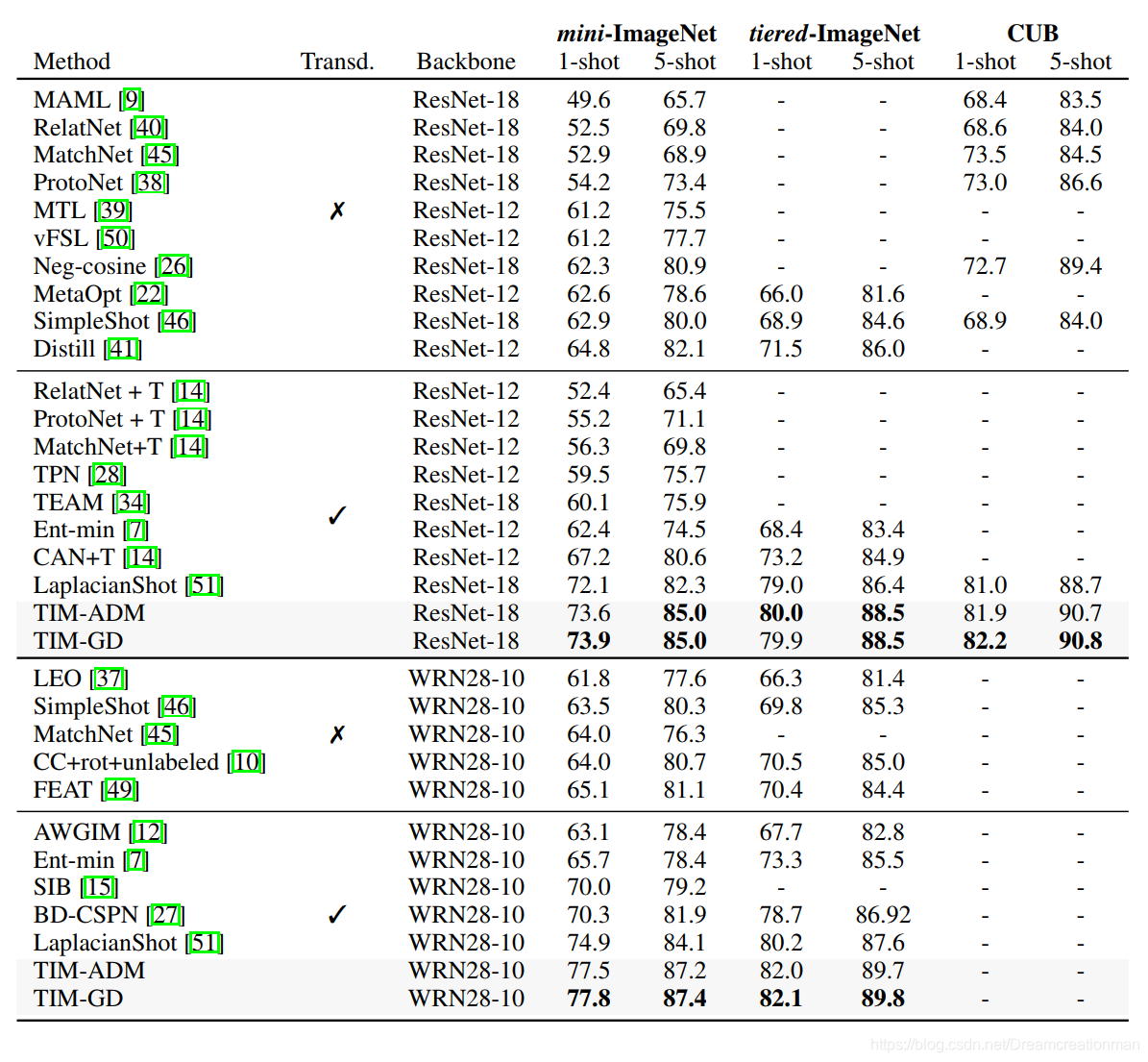
结果
贴一贴实验结果,这是在作者的结果:
后记
如果你觉得我的文章写的不错的话,麻烦帮忙向大家推广关注我的公众号啊(名称:洋可喵)!!!
















 1695
1695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









