







假设给你一个敏感词汇表, 然后让你把一篇文章里的敏感词汇都找出来,以便于验证当前文章是否都满足没有敏感词汇要求,你会怎么办? 最容易想到的便是将文章里的每一个单词都拿去在敏感词汇表中查找是否存在,这样当文章词汇很大的时候,查找算法便成为了一个瓶颈。你可以使用最简单的做个单词匹配,也可以先将词汇表按字典排个序来加速查找匹配的过程,当然你也会想到利用红黑树,hash表,splay树来做优化。我们这里介绍一种查找效率比hash,红黑还要高的算法,字典树 trie-tree。
字典树(trie-tree)又被称作是前缀树或者单词查找树,是一种树形结构。是通过对字符串构造一棵字典状树,这样就将不同字符串的公共前缀保存在了一起,从而在查找的时候降低了查找复杂度。如何构造一个字典树,如下所示:
假如我们处理的部分全部是小写字母组成的单词,我们以此来构建一棵字典树:包括敏感词汇有 add, hou, abc ,hack。字典树结构如下所示:

字典树都有一个root节点, 除了root节点其余节点都保存一个字符信息, 从root节点到某一个节点,所经过的节点字符连起来就是这个节点对应的字符串单词。比如我们查找hack,root->h->a->c->k 对于每个节点来说都要标记是不是单词字符串标记和前缀标记,目的是用以可以区分是不是前缀还是词汇。比如hack到k节点flag为true表示为一个字符串而不是前缀,而hack里面h, a , c的flag为false都表示为前缀。
由上可以看出字典树的精髓在于最大限度的压缩了公共前缀字符,从而最大限度的降低了查找过程的重复比较的数量。减少无谓字符串的比较从而使得字符串匹配的速率大大提高,但是字典树是巧妙的用了空间换取了时间,所以你会看到字典树的内存消耗比较大,因为要存储同类型的所有数据单元去建树。当然也可以用左儿子右兄弟的形式优化。
字典树的常用数据结构如下所示:
#define MAXVAL 26
typedef struct node
{
int isStr; // 判断是否为前缀或者字符串
node* next[MAXVAL]; // 对应单词表 next表示当前字符后一个字符的存储数组 这里是26
}trie;字典树常用的操作有如下三种:
1》 插入操作 (插入过程即为建树过程)
2》 查找操作
3》释放字典树
插入操作:从root节点开始依次比较需要插入单词str的每个字符是否在字典树的子节点中,如果存在就移动到子节点进行下一个字符比较,如果不存在就新建一个节点来存储当前的字符,然后进行下一个字符的判断,直到所有的str字符都判断完,全部字符都存在于str中插入操作即完成。
查找操作:对给定的root为根节点的字典树,查找str字符串是否存在,依次取出str的每个字符,依次从root节点开始查找是否有对应的子节点拥有当前字符,如果有就进入对应的子节点进行下一个字符的查找,直到找到最后一个字符,而且最后一个节点的isStr状态为true表明当前字符串存在于字典树,否则如果判断比较过程中有对应的子节点为NULL或者最后的isStr为false就表明对应的字符串不属于当前字典树,返回false。
释放字典树:字典树是一个多叉树结构,从根节点开始一次递归释放每一个多叉树即可。
code:
#define MAXVAL 26
typedef struct node
{
int isStr; // 判断是否为前缀或者字符串
node* next[MAXVAL]; // 对应单词表 next表示当前字符后一个字符的存储数组 这里是26
}trie;
trie* new_and_init() // 创建一个新节点并且初始化多叉子树为NULL
{
trie* tmp = (trie*) malloc(sizeof(trie));
if (tmp == NULL) return NULL;
tmp->isStr = 0;
for (int i = 0; i < MAXVAL; i++)
tmp->next[i] = NULL;
return tmp;
}
// 释放字典树
void free_trie(trie* root)
{
if (root == NULL) return;
for (int i = 0; i < MAXVAL; i++)
{
free_trie(root->next[i]);
}
free (root);
}
// 插入新节点 即构造字典树
int insert_node(trie* root, string str)
{
if (root == NULL || str.length() == 0)
return 0;
trie* ptr = root;
for (int i = 0; i < str.length(); i++)
{
if (ptr->next[str[i] - 'a'] == NULL) // 如果对应的字符不在 新建
{
trie* tmp = new_and_init();
ptr->next[str[i] - 'a'] = tmp;
}
ptr = ptr->next[str[i] - 'a'];
}
return ptr->isStr = 1; // 当前str插入成功,标记为字符串
}
int find_node(trie* root, string str)
{
if (root == NULL || str.length() == 0)
return 0;
trie* ptr = root;
for (int i = 0; i < str.length(); i++)
{
if (ptr->next[str[i] - 'a'] == NULL)
return 0;
ptr = ptr->next[str[i] - 'a'];
}
return ptr != NULL && ptr->isStr; // 判断是否为前缀或者字符串
}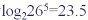 次比较。所以你会发现不计较空间的时候, Trie-tree查询效率比红黑树和哈希表都要快
次比较。所以你会发现不计较空间的时候, Trie-tree查询效率比红黑树和哈希表都要快















 241
241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









