







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

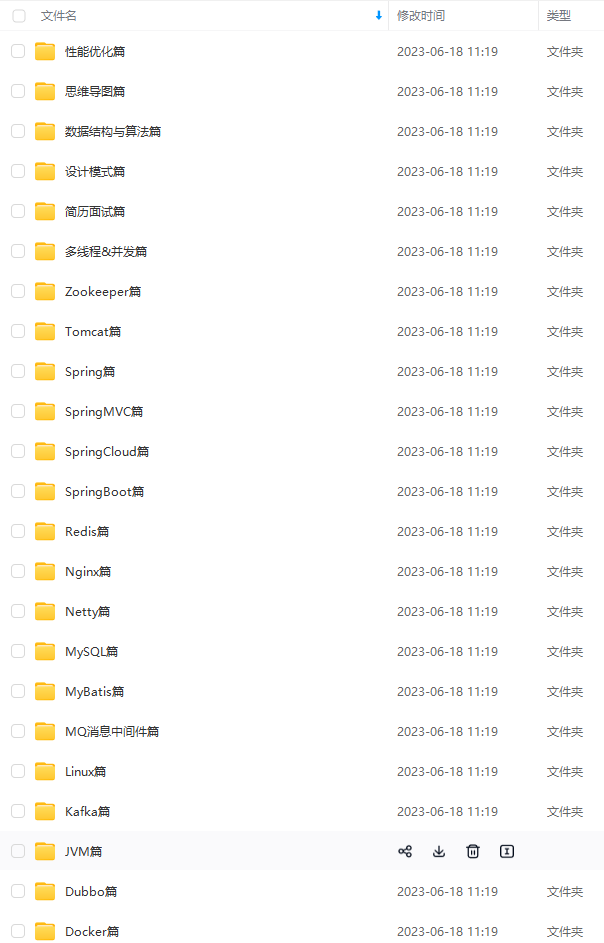
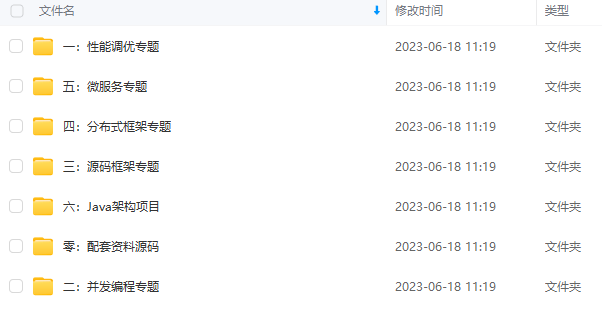
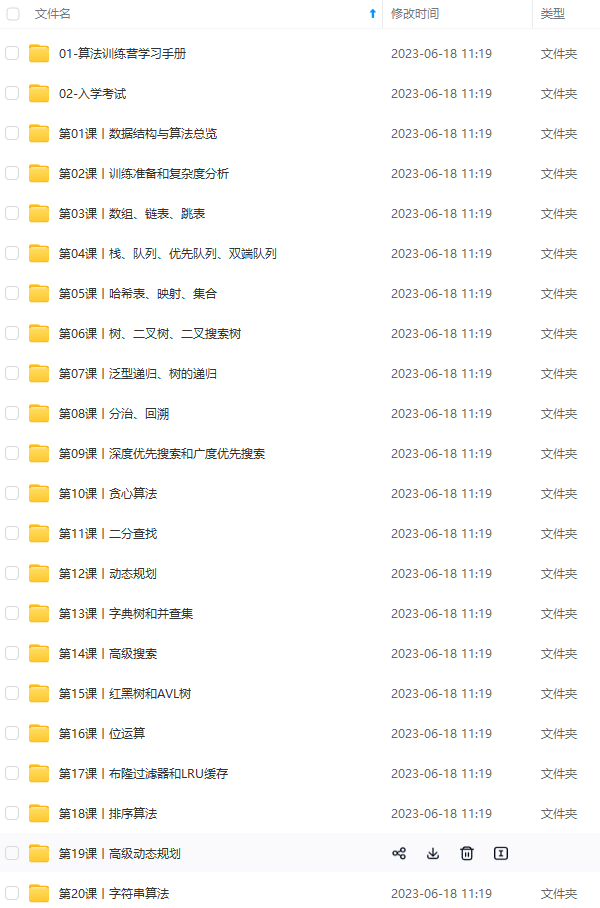
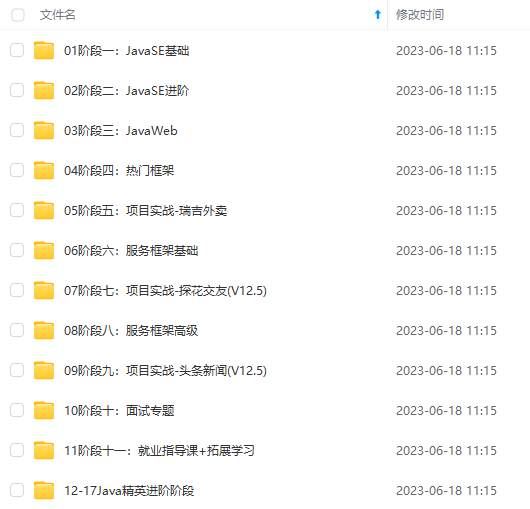
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
① ArrayList 采⽤数组存储,所以插⼊和删除元素的时间复杂度受元素位置的影响。 执⾏ add(E e) ⽅法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1),但是可能会产生扩容。但是如果要在指定位置 i插⼊和删除元素的话时间复杂度就为 O(n-i)。因为在进⾏上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执⾏向后位/向前移⼀位的操作。
②LinkedList 采⽤链表存储,所以对于 add(E e) ⽅法的插⼊,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置 i 插⼊和删除元素的话时间复杂度近似为 O(n) 因为需要先移动到指定位置再插⼊。
-
随机访问效率:ArrayList 比 LinkedList 在随机访问的时候效率要高,因为 LinkedList 是线性的数据存储方式,所以需要移动指针从前往后依次查找。
-
内存空间占⽤:LinkedList 的每一个节点要比 ArrayList 更占内存,因为 LinkedList 的节点除了存储数据,还存储了前后引用。而 ArrayList 的空间浪费主要体现在在 list 列表的结尾会预留⼀定的容量空间。
在需要频繁读取集合中的元素时,更推荐使用 ArrayList,而在插入和删除操作较多时,更推荐使用 LinkedList。
**ArrayList的扩容机制:
以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。 之后在进行扩容时,每次扩容为原来的 1.5 倍。**
ArrayList 不是线程安全的,如果遇到多线程场景,可以通过 Collections 的 synchronizedList 方法将其转换成线程安全的容器后再使用。例如像下面这样:
List synchronizedList = Collections.synchronizedList(list);
synchronizedList.add(“aaa”);
synchronizedList.add(“bbb”);
for (int i = 0; i < synchronizedList.size(); i++) {
System.out.println(synchronizedList.get(i));
}
也可以使用线程安全的CopyOnWriteArrayList,其底层也是对增删改方法进行加锁:final ReentrantLock lock = this.lock;
-
线程是否安全:HashMap是线程不安全的,HashTable是线程安全的(内部的⽅法基本都经过 synchronized 修饰);
-
效率: 因为线程安全的问题, HashMap 要⽐ HashTable 效率⾼⼀点
-
是否支持键值为null:HashMap中允许键和值为null,但是null作为键只能有一个,HashTable不支持;
-
扩容机制:HashMap的默认容器是16,为2倍扩容,HashTable默认是11,为2倍+1扩容;
-
底层数据结构: JDK1.8 以后的 HashMap 当链表⻓度⼤于阈值(默认为 8)(将链表转换成红⿊树前会判断,如果当前数组的⻓度⼩于 64,那么会选择先进⾏数组扩容,⽽不是转换为红⿊树)时,将链表转化为红⿊树,以减少搜索时间。Hashtable 没有这样的机制。
| HashMap | HashSet |
| — | — |
| 实现了 Map 接⼝ | 实现 Set 接⼝ |
| 存储键值对 | 仅存储对象 |
| 调⽤ put() 向 map 中添加元素 | 调⽤ add() ⽅法向 Set 中添加元素 |
| HashMap 使⽤键(Key)计算hashcode | HashSet 使⽤成员对象来计算 hashcode 值 |
| HashMap使用唯一的键获取对象,速度较快 | HashSet 速度较慢 |
当你把对象加⼊HashSet 时, HashSet 会先计算对象的 hashcode 值来判断对象加⼊的位置,同时也会与其他加⼊的对象的 hashcode 值作比较,如果没有相符的 hashcode , HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调⽤ equals() ⽅法来检查hashcode 相等的对象是否真的相同。如果两者相同, HashSet 就不会让加⼊操作成功。
**Hash算法:哈希算法是指把任意长度的二进制映射为固定长度的较小的二进制值,这个较小的二进制值叫做哈
希值**
扰动函数:是 HashMap 的 hash 方法。使⽤ hash 方法也就是扰动函数是为了防⽌⼀些实现⽐较差的hashCode() 方法换句话说使⽤扰动函数之后可以减少碰撞。 多次扰动可以加大哈希值低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性&均匀性,最终减少Hash冲突(jdk1.8扰动了两次,1次位运算 + 1次异或运算,已经达到了高位低位同时参与运算的目的;)
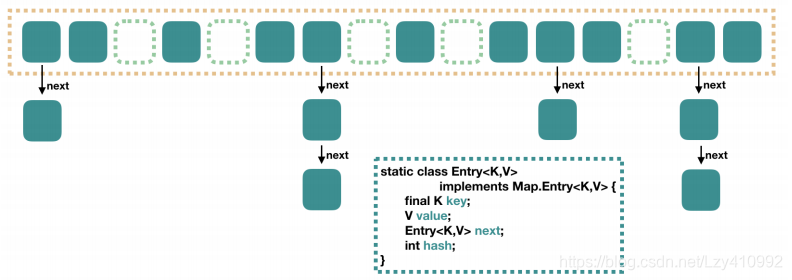
JDK1.8 之前:
JDK1.8 之前 HashMap 底层是数组和链表结合在⼀起使⽤也就是链表散列。
-
当我们要put元素时,HashMap 通过key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置。
-
如果当前位置存在元素的话,就判断该元素与要存⼊的元素的 hash 值以及 key 是否相同。
-
如果相同的话,直接覆盖,不相同就将当前的key-value放如链表中,通过拉链法解决冲突。
-
获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
JDK1.8 之后:
JDK1.8 之后引入了红黑树的概念,当链表⻓度⼤于阈值(默认为 8)(将链表转换成红⿊树前会判断,如果当前数组的⻓度⼩于 64,那么会选择先进⾏数组扩容,而不是转换为红⿊树)时,将链表转化为红⿊树,以减少搜索时间。(长度低于6时恢复为链表)
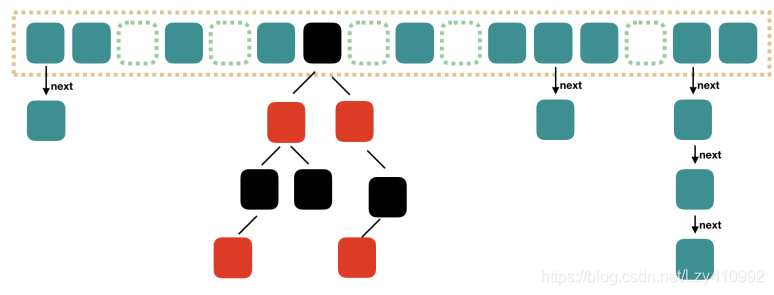
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都⽤到了红⿊树。红⿊树就是为了解决⼆叉查找树的缺陷,因为⼆叉查找树在某些情况下会退化成⼀个线性结构。
| | JDK 1.7 | JDK 1.8 |
| — | — | — |
| 存储结构 | 数组 + 链表 | 数组 + 链表 + 红黑树 |
| 初始化方式 | 单独函数: inflateTable() | 直接集成到了扩容函数 resize() 中 |
| hash值计算方式 | 扰动处理 = 9次扰动 = 4次位运算 + 5次异或运算 | 扰动处理 = 2次扰动 = 1次位运算 + 1次异或运算 |
| 存放数据的规则 | 无冲突时,存放数组;冲突时,存放链表 | 无冲突时,存放数组;冲突时根据链表长度判断存放链表还是红黑树 |
| 插入数据方式 | 头插法(先讲原位置的数据移到后1位,再插入数据到该位置) | 尾插法(直接插入到链表尾部/红黑树 |
| 扩容后存储位置的计算方式 | 全部按照原来方法进行计算(即hashCode ->> 扰动函数 ->> (h&length-1)) | 按照扩容后的规律计算(即扩容后的位置=原位置 or 原位置 + 旧容量) |
-
红黑树是一种特殊的二叉查找树,红黑树的每个结点上都有存储位表示结点的颜色,可以是红(Red)或黑(Black)。
-
红黑树的每个结点是红色或者黑色。但是不管怎么样他的根结点是黑色。每个为空的叶子结点也是黑色
-
如果一个结点是红色的,则它的子结点必须是黑色的。
-
每个结点到叶子结点所经过的黑色结点的个数一样的。(确保没有一条路径会比其他路径长出俩倍,所以红黑树是相对接近平衡的二叉树的)
红黑树的基本操作是添加、删除。在对红黑树进行添加或删除之后,都会用到旋转方法。保证这颗树依然是红黑树。
- **在jdk1.8中,resize方法是在hashmap中的键值对大于阀值时或者初始化时,就调用resize方法进
行扩容;**
-
每次扩展的时候,都是扩展2倍;
-
扩展后Node对象的位置要么在原位置,要么移动到原偏移量两倍的位置。
在putVal()中,我们看到在这个函数里面使用到了2次resize()方法,resize()方法表示的在进行第一次初始化时会对其进行扩容,或者当该数组的实际大小大于其临界值值(第一次为12),这个时候在扩容的同时也会伴随的桶上面的元素进行重新分发,这也是JDK1.8版本的一个优化的地方,在1.7中,扩容之后需要重新去计算其Hash值,根据Hash值对其进行分发,但在1.8版本中,则是根据在同一个桶的位置中进行判断(e.hash & oldCap)是否为0,重新进行hash分配后,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀,每个链表/红黑树长度大致相同。这个实现就是把数据存到哪个链表/红黑树中的算法。我们首先可能会想到采用%取余的操作来实现。但是取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。
Ending
Tip:由于文章篇幅有限制,下面还有20个关于MySQL的问题,我都复盘整理成一份pdf文档了,后面的内容我就把剩下的问题的目录展示给大家看一下
如果觉得有帮助不妨【转发+点赞+关注】支持我,后续会为大家带来更多的技术类文章以及学习类文章!(阿里对MySQL底层实现以及索引实现问的很多)


吃透后这份pdf,你同样可以跟面试官侃侃而谈MySQL。其实像阿里p7岗位的需求也没那么难(但也不简单),扎实的Java基础+无短板知识面+对某几个开源技术有深度学习+阅读过源码+算法刷题,这一套下来p7岗差不多没什么问题,还是希望大家都能拿到高薪offer吧。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
来p7岗差不多没什么问题,还是希望大家都能拿到高薪offer吧。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-sCQk9ggu-1713067680246)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









