







实验环境:postgresql-15.1 CentOS 7.9 x86-64
pg_cron版本:1.5.1
一 概述
该插件源码在github上项目地址:https://github.com/citusdata/pg_cron
pg_cron 是一个简单的基于cron的 PostgreSQL(10 或更高版本)作业调度程序,它作为扩展在数据库内部运行。它使用与常规cron相同的语法,但它允许您直接从数据库调度PostgreSQL命令。您还可以使用"[1-59] seconds"来根据时间间隔安排作业。(来自官方README)
使用和OS一样的cron语法来定义执行计划:
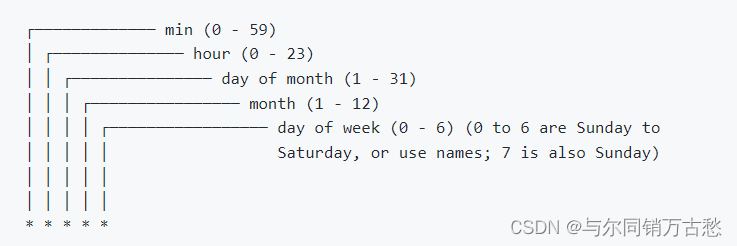
缺点(已发现的):
- 只能指定到PG中的一个数据库中使用
- 对不同的job,同一时间点是可以并发执行的,但是对于同一个job,假如该job第一次还未执行完,第二次执行就到时间了,那么第二次执行就会等待第一次执行完成后才能执行(后续有实验)
二 安装
https://github.com/citusdata/pg_cron
2.1 编译安装二进制文件
下载软件包并解压
su - postgres
确认pg_config包含在$PATH中
[postgres@centos7 pkg_pg]$ which pg_config
/pg/pghome/bin/pg_config解压并make安装
tar -xvf pg_cron-1.5.1.tar.gz
cd pg_cron-1.5.1/
make
make install 安装完成,需要配置参数后才可以安装扩展.
2.2 配置pg_cron参数
为了在PG启动时同步启动pg_cron后台进程,你需要将pg_cron添加到shared_preload_libraries参数中.
请注意:pg_cron不会在备库中运行任何job,但是当备库提升为主库时,将会自动运行job
alter system set shared_preload_libraries='pg_cron';该参数需要重启数据库生效,生效后,数据库才能识别其余cron.*参数的状态
pg_ctl restart
查看与pg_cron有关的参数:
postgres=# select * from pg_settings where name like 'cron%';
name |setting |unit|category |short_desc |extra_desc |context |vartype|source |min_val|max_val|enumvals |boot_val |reset_val|sourcefile|sourceline|pending_restart|
---------------------------+---------+----+------------------+--------------------------------------------------+------------------------------------------------------------+----------+-------+-------+-------+-------+------------------------------------------------------------------------------+---------+---------+----------+----------+---------------+
cron.database_name |postgres | |Customized Options|Database in which pg_cron metadata is kept. | |postmaster|string |default| | |NULL |postgres |postgres | | |false |
cron.enable_superuser_jobs |on | |Customized Options|Allow jobs to be scheduled as superuser | |postmaster|bool |default| | |NULL |on |on | | |false |
cron.host |localhost| |Customized Options|Hostname to connect to postgres. |This setting has no effect when background workers are used.|postmaster|string |default| | |NULL |localhost|localhost| | |false |
cron.log_min_messages |warning | |Customized Options|log_min_messages for the launcher bgworker. | |sighup |enum |default| | |{debug5,debug4,debug3,debug2,debug1,info,notice,warning,error,log,fatal,panic}|warning |warning | | |false |
cron.log_run |on | |Customized Options|Log all jobs runs into the job_run_details table | |postmaster|bool |default| | |NULL |on |on | | |false |
cron.log_statement |on | |Customized Options|Log all cron statements prior to execution. | |postmaster|bool |default| | |NULL |on |on | | |false |
cron.max_running_jobs |32 | |Customized Options|Maximum number of jobs that can run concurrently. | |postmaster|integer|default|0 |800 |NULL |32 |32 | | |false |
cron.timezone |GMT | |Customized Options|Specify timezone used for cron schedule. | |postmaster|string |default| | |NULL |GMT |GMT | | |false |
cron.use_background_workers|off | |Customized Options|Use background workers instead of client sessions.| |postmaster|bool |default| | |NULL |off |off | | |false |
(9 rows)- cron.database_name: 默认情况下,pg_cron后台进程的系统表创建在"postgres"数据库下,但是可以通过cron.database_name参数来指定系统表的存储位置.
- cron.timezone: 默认情况下pg_cron使用GMT时区的时间,但是新版本可以通过设置该参数来指定时区,中国东八区使用PRC
- cron.enable_superuser_jobs: 默认on,superuser可以修改/调度所有的job
- cron.log_min_messages: 记录log的最小粒度,默认记录等级warning
- cron.log_run:记录所有的job执行情况,记录到job_run_details,默认打开
- cron.log_statement:在执行之前记录所有cron语句,默认打开
- cron.max_running_jobs:可以同时运行的最大作业数,默认32
- cron.use_background_workers:使用后台进程执行,而不是client会话
- cron.host: 当使用client会话模式时,指定显示的主机名,但是当cron.use_background_workers为on时(使用后台进程模式时),该参数无效
alter system set cron.timezone='PRC';
alter system set cron.database_name='db_test'; --注意:只能一个库用,所以这里改成将要使用的库名其他参数我们默认无需修改,根据需要自己定制参数
需要重启数据库让参数生效
pg_ctl restart
2.3 PG中创建扩展
使用superuser用户增加扩展
CREATE EXTENSION pg_cron;假如想让普通用户也能创建cron,那么授权usage给普通用户
GRANT USAGE ON SCHEMA cron TO scott;2.4 让pg_cron能够运行job
pg_cron有两种方式:client模式和后台进程模式
2.4.1 client模式运行pg_cron
重要:默认情况下,pg_cron使用libpq去创建新的会话连接到local database,所以需要:
1. 在pg_hba.conf中允许本地用户登录
2. 在pg_hba.conf中设置本地登录trust,或者设置.pgpass文件,实现免密登录
(有些环境禁用本地免密登录,我在此处配置.pgpass,有条件可以直接配置pg_hba.conf中trust,减少出错点)
还有特殊方案:使用本地unix domain socket 作为主机名,并在pg_hba.conf中配置相关的trust条目,这通常也比较安全(配置cron.host='/tmp')
2.4.2 后台进程模式运行pg_cron(需要调整max_worker_processes)
不太建议使用该方式,因为牵扯到max_worker_processes参数调整,和服务器资源等相关
# 使用后台进程模式,而不是使用客户端模式
cron.use_background_workers = on
# 提高max_worker_processes参数=20,该参数默认为8
max_worker_processes = 20三 定时任务的创建和管理
环境:创建数据库db_test和用户scott
postgres=# create database db_test;
CREATE DATABASE
postgres=# create user scott password 'tiger';
CREATE ROLE
postgres=# \c db_test
You are now connected to database "db_test" as user "postgres".
db_test=# grant all ON schema public TO scott ;
GRANT普通用户scott创建测试表
db_test=> create table t1 (id serial,curr_time varchar,curr_user varchar);
CREATE TABLE添加~/.pgpass
localhost:5432:db_test:scott:tiger3.1 创建cron类型的任务

3.1.1 使用cron语法
创建一条执行语句的计划
SELECT cron.schedule('56 15 * * *', $$insert into t1(curr_time,curr_user) values(now()::varchar,user)$$);为了测试,可以定一个马上要到的时间
3.1.2 使用时间间隔
SELECT cron.schedule('10 seconds', $$insert into t1(curr_time,curr_user) values(now()::varchar,user)$$);3.1.3 指定任务名
SELECT cron.schedule('Ever 10s insert data','10 seconds', $$insert into t1(curr_time,curr_user) values(now()::varchar,user)$$);3.1.4 每晚上3点执行VACUUM
SELECT cron.schedule('nightly-vacuum', '0 3 * * *', 'VACUUM');3.2 查询job清单
select * from cron.job;
db_test=> select * from cron.job;
jobid | schedule | command | nodename | nodeport | database | username | active | jobname
-------+-------------+-----------------------------------------------------------------+-----------+----------+----------+----------+--------+----------------------
1 | 41 15 * * * | insert into t1(curr_time) values(now()::varchar); | localhost | 5432 | db_test | scott | t |
2 | 52 15 * * * | insert into t1(curr_time) values(now()::varchar); | localhost | 5432 | db_test | scott | t |
3 | 56 15 * * * | insert into t1(curr_time,curr_user) values(now()::varchar,user) | localhost | 5432 | db_test | scott | t |
4 | 59 15 * * * | insert into t1(curr_time,curr_user) values(now()::varchar,user) | localhost | 5432 | db_test | scott | t |
6 | 10 seconds | insert into t1(curr_time,curr_user) values(now()::varchar,user) | localhost | 5432 | db_test | scott | t | Ever 10s insert data
(5 rows)3.3 查询job执行日志
select * from cron.job_run_details order by start_time desc ;
db_test=> select * from cron.job_run_details order by start_time desc ;
jobid|runid|job_pid|database|username|command |status |return_message |start_time |end_time |
-----+-----+-------+--------+--------+---------------------------------------------------------------+---------+-----------------+-----------------------------+-----------------------------+
3| 1| |db_test |scott |insert into t1(curr_time,curr_user) values(now()::varchar,user)|failed |connection failed| | |
4| 2| 3880|db_test |scott |insert into t1(curr_time,curr_user) values(now()::varchar,user)|succeeded|INSERT 0 1 |2023-03-21 15:59:00.017 +0800|2023-03-21 15:59:00.018 +0800|
(2 rows)return_message:返回的结果,发现第一个是因为连接失败了,之后可以结合pg日志检查免密认证的情况
3.4 修改job
语法:
SELECT cron.alter_job('<定时任务ID>, '<定时计划>', '<定时任务>', '<执行数据库>', '<执行用户>', '<任务是否启用>');遇到问题:发现普通用户即使能够创建和删除,但是也不能修改job,应该是个BUG?
db_test=> select cron.alter_job('6','15 seconds',$$insert into t1(curr_time,curr_user) values(now()::varchar,user)$$);
ERROR: permission denied for function alter_job3.5 删除job
语法:
SELECT cron.unschedule(<定时任务ID>);
SELECT cron.unschedule('<定时任务名称>');此处删除job,普通用户就能执行成功了
db_test=> SELECT cron.unschedule(6);
unschedule
------------
t
(1 row)四 对pg_cron并发执行的探索
思路:
job1和job2,设置相同的任务时间,同时对测试表进行写入,
job3执行pg_sleep(180),目的是测试阻挡job1和job2
1. 创建1张表,
create table t2 (id serial,curr_time varchar,curr_user varchar,job_name varchar);2. 创建3个job
job1和job2增加pg_sleep(3)是为了区分开2个不同的任务设定到同一时间后,是否也会相互等待
job3设置180s,是为了验证同一个job未执行完,后面该job又到执行时间的情况,能否直接执行
SELECT cron.schedule('job1','*/2 * * * *', $$insert into t2(curr_time,curr_user,job_name) values(now()::varchar,user,'job1');select pg_sleep(3)$$);
SELECT cron.schedule('job2','*/2 * * * *', $$insert into t2(curr_time,curr_user,job_name) values(now()::varchar,user,'job2');select pg_sleep(3)$$);
SELECT cron.schedule('job3','*/2 * * * *', $$insert into t2(curr_time,curr_user,job_name) values(now()::varchar,user,'job3');select pg_sleep(180)$$);3.等待多执行几次,验证结论
db_test=> select * from t2;
id | curr_time | curr_user | job_name
----+-------------------------------+-----------+----------
18 | 2023-03-21 16:54:00.018432+08 | scott | job1
19 | 2023-03-21 16:54:00.034451+08 | scott | job2
20 | 2023-03-21 16:54:00.035248+08 | scott | job3
21 | 2023-03-21 16:56:00.007111+08 | scott | job1
22 | 2023-03-21 16:56:00.012271+08 | scott | job2
23 | 2023-03-21 16:57:00.098638+08 | scott | job3 --本来是偶数分钟执行,现在排到16:57了,正好距离第一次执行差180s
24 | 2023-03-21 16:58:00.019738+08 | scott | job1
25 | 2023-03-21 16:58:00.031114+08 | scott | job2
26 | 2023-03-21 17:00:00.016945+08 | scott | job1
27 | 2023-03-21 17:00:00.026808+08 | scott | job2
28 | 2023-03-21 17:00:00.188775+08 | scott | job3
29 | 2023-03-21 17:02:00.014714+08 | scott | job1
30 | 2023-03-21 17:02:00.025062+08 | scott | job2
32 | 2023-03-21 17:04:00.016704+08 | scott | job1
33 | 2023-03-21 17:04:00.027617+08 | scott | job2
(15 rows)验证结论:
对不同的job,同一时间点是可以并发执行的
对于同一个job,假如该job第一次还未执行完,就到第二次执行的时间了,那么第二次执行就会等待第一次执行完成后才能执行.














 1979
1979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









