






数据介绍
标签体系
产业治理方面的标签体系共计200+个,每个标签共有4个层级,且第3、4层级有标签含义的概括信息。
原始数据
-
企业官网介绍数据,包括基本介绍、主要产品等
-
企业专利数据,包括专利名称和专利摘要信息,且专利的数据量大。
LLM选型
经调研,采用Qwen2-72B-Instruct-GPTQ-Int4量化版本,占用显存更少,且效果与非量化相当,具体可见Qwen2官网说明。
技术难点
-
团队无标注人员,因此无法使用Bert类小模型完成多标签分类任务
-
涉及垂直领域,即使有标注人员,也需要很强的背景知识,方能开展标注
-
标签数量多,层次深,且项目对准确率有要求
方案设计
由于缺少标注人员,且对标注员的背景要求高,因此只能选择LLM进行任务开展。
标签体系中每个标签的含义不够具象,属于总结性的,针对特定场景,LLM可能无法准确分类。因此,可以考虑抽取特定领域的关键词,作为基础知识,以实现RAG。
企业官网及专利数据量巨大,调用LLM存在耗时超长的问题,好在有2台8卡的机器,可以做分布式推理,提高响应性能。
总体的方案设计如下:
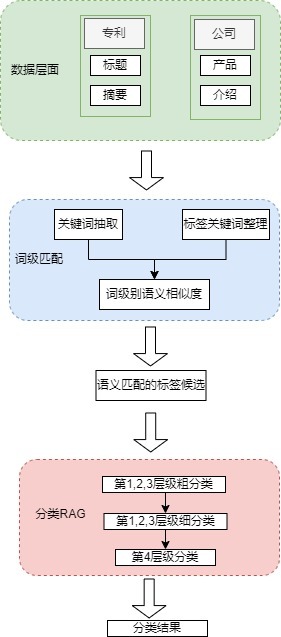
图虽然简单明了,但其中的细节还是值得玩味的。
词级匹配模块
(1) 针对垂直领域,基于标签的含义及经验知识,人工整理标签可能涉及的关键词,如智能汽车,可能存在智能驾驶、自动泊车、变道辅助等,但人工整理的关键词有限;
(2) 针对企业及专利数据,采用LAC+Jieba分词(注意,人工整理的词表不进行拆分),然后使用KeyBert+编辑距离进行关键词匹配(keybert底层模型采用目前效果最优的xiaobu-embedding-v2),筛选出关键词可能匹配的映射标签
分类RAG模块
(1) 每类标签的第3层级下的第4级标签的个数有限,因此首先针对标签的前3层级进行分类。取巧的地方在于先粗后精,即前3层级对应的标签个数较多,因此拆分为N组,每组通过prompt调用LLM输出一个结果,然后再针对输出的结果进行聚合,再调用一次LLM生成细粒度的标签
(2) 前3层级标签确定之后,再基于第4层级标签进行末级标签确定
功能特点
1、为什么使用关键词进行RAG?
答:关键词虽然无法直接映射对应的标签(客官可以想想为什么?),但关键词有较强的背景提示,因此prompt中关键词有值的标签筛选出来的概率更大一些
2、关键词语义匹配为什么还需要增加编辑距离?
答:因为语义相似度模型一般针对较短文本的比较,针对词的比较效果较差,因此引入编辑距离,提高词级匹配度
3、同一个关键词对应多个标签的场景如何解决?
答:通过底层的LLM进行分辨具体应该属于哪一个
4、分类RAG是如何考虑的
答:由于标签数量较多,层级较深,而且LLM的输入长度有限,因此采用化繁为简(或先分后合)的方式,将整个标签体系先进行分组,然后调用LLM输出每个分组输出结果,再对结果进行整合,再次调用LLM进行细粒度分类确认
5、分类RAG先粗后细有什么好处?
答:粗粒度分类,LLM只能观察到给定的一组标签,而看不到整体标签,粗粒度划分好之后,细粒度再次确认,有助于提高分类的准确性。实验结果表明,准确率可以从70%-80%,上升到85%-90%,当然该实验只是针对该特定场景,但缺点是增加了LLM的响应时间。
6、标签划分N组后调用LLM,如何提高响应性能?
答:由于部署的是Qwen2量化版,且有2台8张卡可以使用,因此起了8个vllm进程,用haproxy做请求转发,从而提高LLM的响应性能。实验表明,7W+数据,只需要耗时1天左右即可跑完结果,单节点非量化版本,可能需要几个礼拜才能跑完。
7、具体效果层面如何?
答:基于这一套方案,针对每个标签进行随机采样抽检,准确率能保持在85%-95%之间
8、为什么不增加fewshot呢?
答:此处的关键词就类似于fewshot示例,若直接以公司或专利作为fewshot,首先所属标签示例范围较广,不好整理,其次严重影响LLM的响应时间,因为输入长度变长。
9、人工未整理的关键词场景,如何确保分类准确?
答:依赖于底层LLM能力,这就是为什么选择Qwen2-72B的原因,当前Qwen2-72B的效果属于业界翘首。
未来优化点
如果想要进一步提升准确率,当前方案已经预留口子,即标签的详细说明及垂直领域关键词的人工整理。标签说明越详细,关键词整理的越完备,分类的准确性就会越高。
但引出的问题是,关键词的人工整理耗时耗力,如何进一步减少人工整理,成为下一步的优化方向。
总结
一句话足矣~
本文主要是采用LLM实现产业治理领域的多标签分类任务,包括具体的方案,LLM工程层面优化,实现效果以及未来的优化方向。
文章转载自:mengrennwpu















 5341
5341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









