






Flume安装和配置
- 上传Flume安装包至服务器根目录下的software目录下,并解压到根目录下的opt目录下
[root@hadoop100 software]# tar -zxvf flume-ng-1.6.0-cdh5.14.0.tar.gz -C /opt
- 进入opt目录下,并更改解压后的名字
[root@hadoop100 software]# cd /opt
[root@hadoop100 opt]# mv apache-flume-1.6.0-cdh5.14.0-bin/ flume160
- 修改配置文件名称,并进入
[root@hadoop100 opt]# cd flume160/conf
[root@hadoop100 conf]# cp flume-env.sh.template flume-env.sh
[root@hadoop100 conf]# vi flume-env.sh
- 添加两个配置
export JAVA_HOME=/opt/java8
export JAVA_OPTS="-Xms2048m -Xmx2048m -Dcom.sun.management.jmxremote"
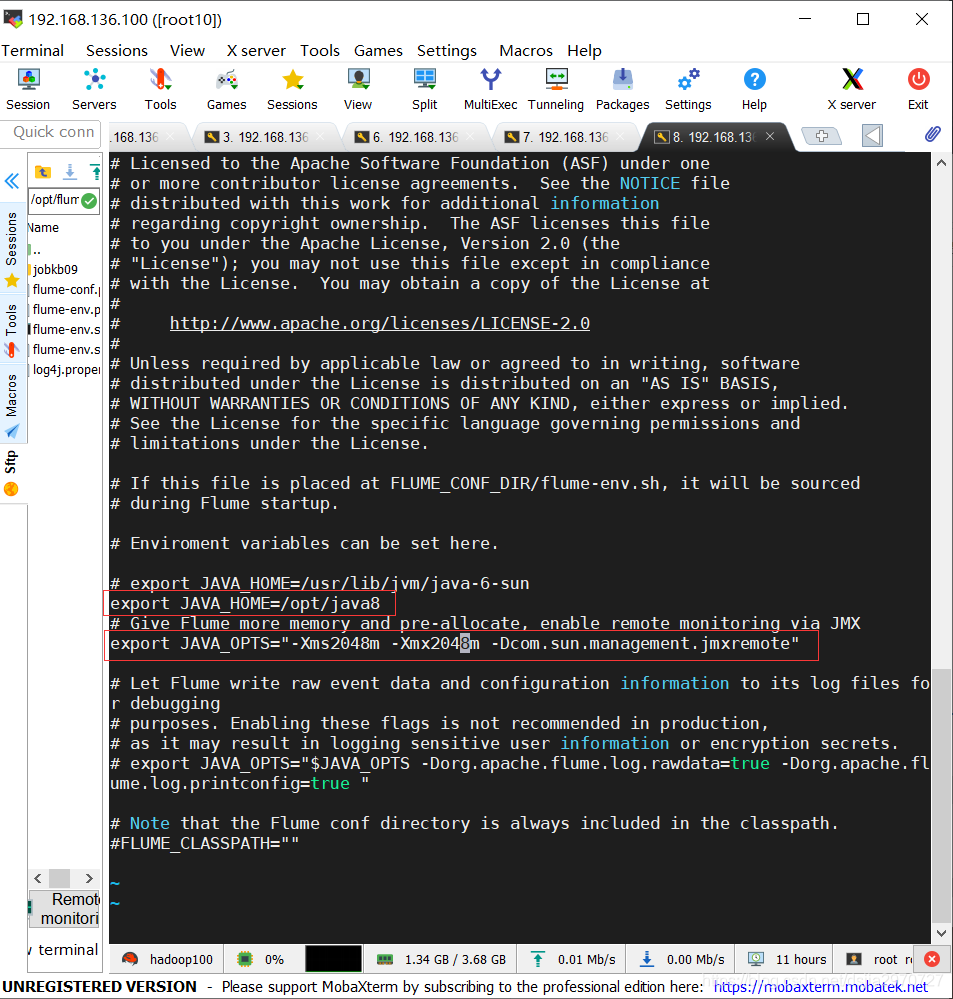
- 保存退出,修改环境变量
[root@hadoop100 conf]# vi /etc/profile
- 添加如下
export FLUME_HOME=/opt/flume160
export PATH=$FLUME_HOME/bin:$PATH
- 保存退出,使其立即生效
[root@hadoop100 conf]# source /etc/profile
- 查看版本号
[root@hadoop100 conf]# flume-ng version

- 到这一步Flume才算安装完成
测试
- 下载安装NetCat(nc)
[root@hadoop100 conf]# yum install -y netcat
或者
[root@hadoop100 conf]# yum install -y nc
- 下载安装telnet
[root@hadoop100 conf]# yum install -y telnet-server.*
[root@hadoop100 conf]# yum install -y telnet.*
- 测试
//server端
[root@hadoop100 conf]# nc -lk 7777
//client端
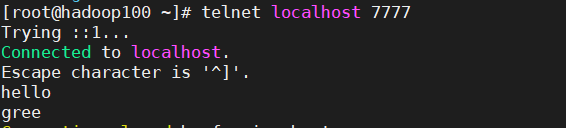
[root@hadoop100 ~]# telnet localhost 7777
- 在client端输入hello、gree。相应的在server端就能出来相同的hello、gree

监控端口数据
编写agent配置文件netcat-flume-logger.conf监控端口数据
- 首先要确保刚才测试情况下开启的netcat和telnet要关掉
- 在flume目录下的conf目录下创建一个文件夹
[root@hadoop100 ~]# mkdir /opt/flume160/conf/jobkb09
- 在jobkb09文件夹下创建配置文件
[root@hadoop100 ~]# vi /opt/flume160/conf/jobkb09/netcat-flume-logger.conf
- 写入如下信息
//agent名为a1
//agent下有很多sources,其中有一个source叫r1
a1.sources=r1
//agent下有很多channels,其中有一个channel叫c1
a1.channels=c1
//agent下有很多sinks,其中有一个sink叫k1
a1.sinks=k1
//设置source类型为netcat,捆绑的主机名名或IP地址为主机,端口号为7777
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=7777
//设置channel类型为memory(内存),容量为1000(通道中能存储的最大事件数),交易能力为1000,(每次交易的最大事件数)
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
//设置sink类型为logger(记录器)
a1.sinks.k1.type=logger
//通过中间的channel把前后的source和sink连接起来
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
- 保存退出,启动flume监控端口数据
[root@hadoop100 flume160]# ./bin/flume-ng agent --name a1 --conf ./conf/ --conf-file ./conf/jobkb09/netcat-flume-logger.conf -Dflume.root.logger=INFO,console
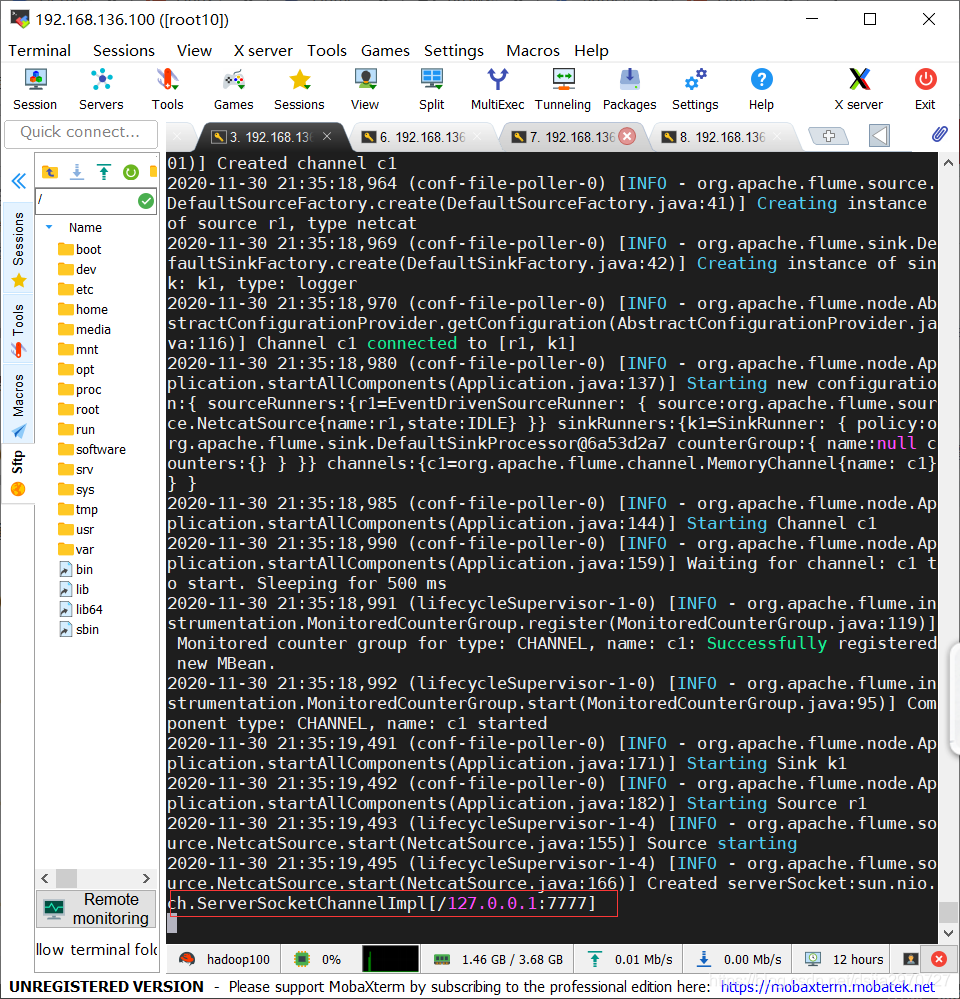
- 通过shell查看端口是否开启成功
[root@hadoop100 ~]# netstat -tnlp

- 通过telnet向该端口发送数据
[root@hadoop100 ~]# telnet localhost 7777
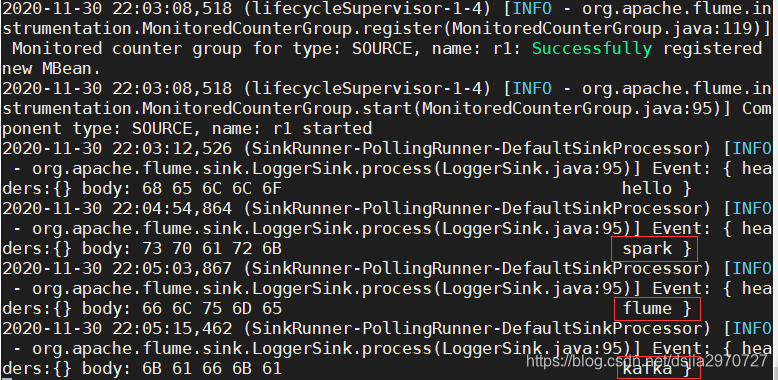
- 输入数据查看Flume是否能接收到数据
spark
flume
kafka
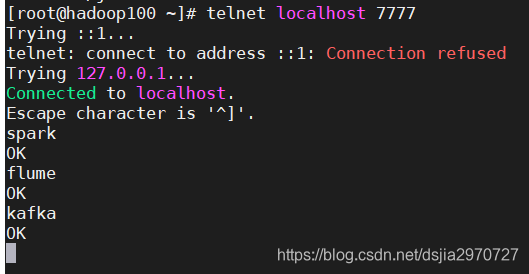

- 这样即代表监控端口数据成功(Flume退出监控端口数据,telnet也会自动退出)
监控文件信息
编写agent配置文件file-flume-logger.conf监控文件信息
- 在jobkb09目录下创建一个文件夹,并在文件夹下创建一个文件
[root@hadoop100 jobkb09]# mkdir tmp
[root@hadoop100 tmp]# vi tmp.txt
- 输入数据
hello
- 保存退出,在jobkb09目录下创建一个配置文件
[root@hadoop100 jobkb09]# vi file-flume-logger.conf
- 输入如下信息
a2.sources=r1
a2.channels=c1
a2.sinks=k1
//设置source的类型为exec
a2.sources.r1.type=exec
//要执行的命令(查看正在改变的日志文件的最尾部内容)
a2.sources.r1.command=tail -F /opt/flume160/conf/jobkb09/tmp/tmp.txt
a2.channels.c1.type=memory
a2.channels.c1.capacity=1000
a2.channels.c1.transactionCapacity=1000
a2.sinks.k1.type=logger
a2.sources.r1.channels=c1
a2.sinks.k1.channel=c1
- 保存退出,运行flume监控文件信息
[root@hadoop100 ~]# flume-ng agent --conf /opt/flume160/conf/ --name a2 --conf-file /opt/flume160/conf/jobkb09/file-flume-logger.conf -Dflume.root.logger=INFO,console

- 往文件中追加内容并查看flume是否能接收到信息
[root@hadoop100 jobkb09]# echo spark>>tmp/tmp.txt
[root@hadoop100 jobkb09]# echo flume>>tmp/tmp.txt
[root@hadoop100 jobkb09]# echo kafka>>tmp/tmp.txt
- 这样即代表监控文件信息成功
监控文件夹中的新文件
编写agent配置文件events-flume-logger.conf监控文件夹中的新文件
- 在jobkb09目录下创建一个配置文件
[root@hadoop100 jobkb09]# vi events-flume-logger.conf
- 输入如下信息
events.sources=eventsSource
events.channels=eventsChannel
events.sinks=eventsSink
events.sources.eventsSource.type=spooldir
events.sources.eventsSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/events
events.sources.eventsSource.deserializer=LINE
events.sources.eventsSource.deserializer.maxLineLength=10000
events.sources.eventsSource.includePattern=events_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
events.channels.eventsChannel.type=file
events.channels.eventsChannel.checkpointDir=/opt/flume160/conf/jobkb09/cheakPointFile/events
events.channels.eventsChannel.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/events
events.sinks.eventsSink.type=logger
events.sources.eventsSource.channels=eventsChannel
events.sinks.eventsSink.channel=eventsChannel
- 保存退出,上传events.csv文件到服务器上的jobkb09目录下的tmp目录下
- 在jobkb09目录下创建所需文件夹
[root@hadoop100 jobkb09]# mkdir /opt/flume160/conf/jobkb09/dataSourceFile/events //source监控的文件夹目录
[root@hadoop100 jobkb09]# mkdir /opt/flume160/conf/jobkb09/cheakPointFile/events //记录检查点的文件的存储目录
[root@hadoop100 jobkb09]# mkdir /opt/flume160/conf/jobkb09/dataChannelFile/events //存储日志文件的目录
- 运行flume监控文件夹中的文件
[root@hadoop100 ~]# flume-ng agent --conf /opt/flume160/conf/ --name events --conf-file /opt/flume160/conf/jobkb09/events-flume-logger.conf -Dflume.root.logger=INFO,console
- 拷贝events.csv至dataSourceFile目录下的events目录下
[root@hadoop100 tmp]# cp ./events.csv /opt/flume160/conf/jobkb09/dataSourceFile/events/events_2020-11-30.csv
注意:文件较大,请谨慎运行
- 查看Flume是否监控成功
[root@hadoop100 tmp]# cd /opt/flume160/conf/jobkb09/dataSourceFile/events
[root@hadoop100 events]# ll

- 再次运行Flume监控,会发现成功的文件变了名称
[root@hadoop100 events]# ll

监控文件写入HDFS中
编写agent配置文件userfriend-flume-hdfs.conf监控文件写入HDFS中
- 在jobkb09目录下创建一个配置文件
[root@hadoop100 jobkb09]# vi userfriend-flume-hdfs.conf
- 输入信息如下
userfriend.sources=userfriendSource
userfriend.channels=userfriendChannel
userfriend.sinks=userfriendSink
userfriend.sources.userfriendSource.type=spooldir
userfriend.sources.userfriendSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/userfriend
userfriend.sources.userfriendSource.deserializer=LINE
userfriend.sources.userfriendSource.deserializer.maxLineLength=320000
userfriend.sources.userfriendSource.includePattern=userfriend_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
userfriend.channels.userfriendChannel.type=file
userfriend.channels.userfriendChannel.checkpointDir=/opt/flume160/conf/jobkb09/cheakPointFile/userfriend
userfriend.channels.userfriendChannel.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/userfriend
userfriend.sinks.userfriendSink.type=hdfs
userfriend.sinks.userfriendSink.hdfs.fileType=DataStream
userfriend.sinks.userfriendSink.hdfs.filePrefix=userFriend
userfriend.sinks.userfriendSink.hdfs.fileSufix=.csv
userfriend.sinks.userfriendSink.hdfs.path=hdfs://192.168.136.100:9000/kb09file/user/userfriend/%Y-%m-%d
userfriend.sinks.userfriendSink.hdfs.useLocalTimeStamp=true
userfriend.sinks.userfriendSink.hdfs.batchSize=640
userfriend.sinks.userfriendSink.hdfs.rollInterval=20
userfriend.sinks.userfriendSink.hdfs.rollCount=0
userfriend.sinks.userfriendSink.hdfs.rollSize=120000000
userfriend.sources.userfriendSource.channels=userfriendChannel
userfriend.sinks.userfriendSink.channel=userfriendChannel
- 保存退出
- 在jobkb09目录下创建相应文件夹
[root@hadoop100 tmp]# mkdir /opt/flume160/conf/jobkb09/dataSourceFile/userfriend
[root@hadoop100 tmp]# mkdir /opt/flume160/conf/jobkb09/cheakPointFile/userfriend
[root@hadoop100 tmp]# mkdir /opt/flume160/conf/jobkb09/dataChannelFile/userfriend
- 运行flume监控文件写入HDFS中
[root@hadoop100 ~]# flume-ng agent --conf /opt/flume160/conf/ --name userfrient --conf-file /opt/flume160/conf/jobkb09/userfriend-flume-hdfs.conf -Dflume.root.logger=INFO,console
- 上传user_friend.csv文件到服务器上的jobkb09目录下的tmp目录下
- 拷贝user_friend.csv到dataSourceFile目录下的userfriend目录下
[root@hadoop100 tmp]# cp ./user_friends.csv /opt/flume160/conf/jobkb09/dataSourceF ile/userfriend/userfriend_2020-11-30.csv
- 查看flume是否监控成功
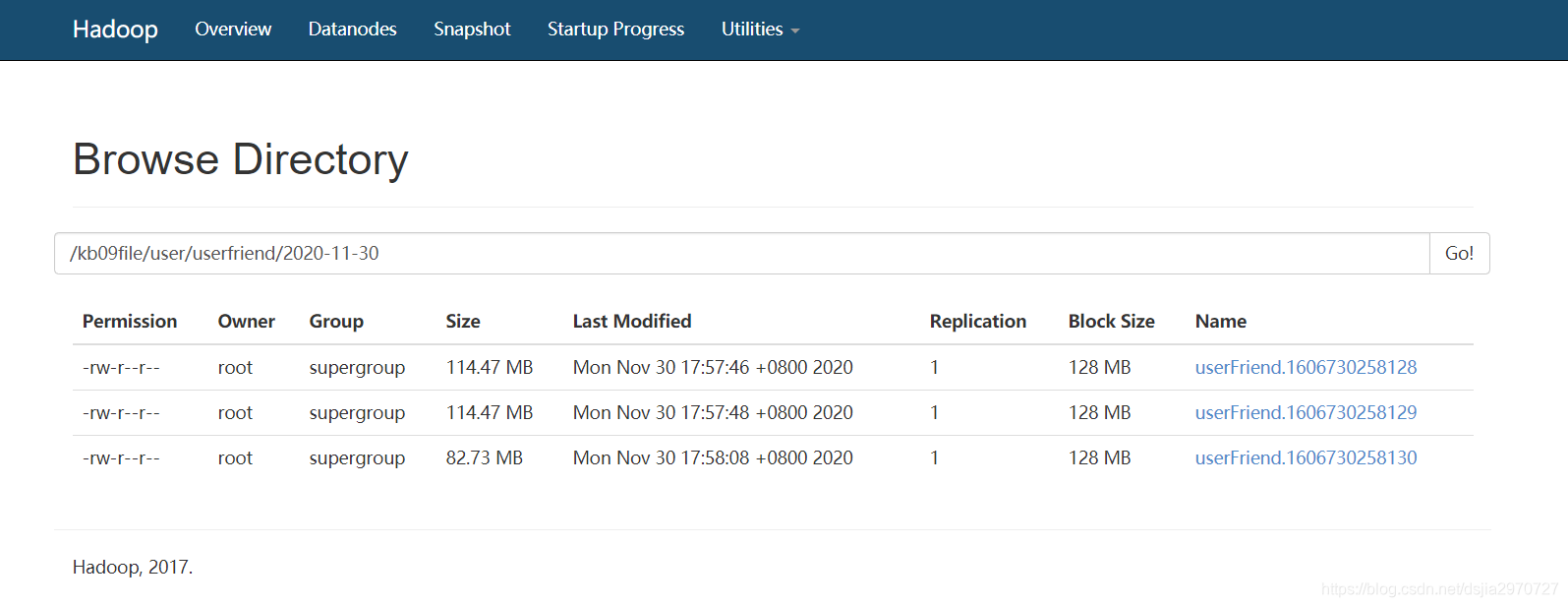
监控文件上传到HDFS并去除首条字段信息(拦截器)
内置拦截器
- 上一个文件在写入HDFS时,发现没有把首条字段信息去除
[root@hadoop100 ~]# hdfs dfs -cat /kb09file/user/userfriend/2020-11-30/userFriend.1606730258128

- 这时我们需要使用内置的拦截器,去除我们所不需要的信息
- 查看我们要上传到HDFS端的文件的首条信息
[root@hadoop100 tmp]# head -n 2 users.csv

- 创建配置文件
[root@hadoop100 jobkb09]# mkdir users-flume-hdfs.conf
- 输入如下信息
//agent的三个组件:sources、channels、sinks
users.sources=usersSource
users.channels=usersChannel
users.sinks=usersSink
//source允许把收集的文件放入磁盘上的某个指定目录。会监视这个目录中产生的新文件
users.sources.usersSource.type=spooldir
//source监控的文件夹目录,该目录下的文件会被flume收集
users.sources.usersSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/users
//指定会被收集的文件名,使用正则表达式匹配文件
users.sources.usersSource.includePattern=users_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
//指定一个把文件中的数据行解析成Event的解析器。默认是把每一行当做一个Event进行解析,Line这个反序列化器会把文本数据的每行解析成一个Event
users.sources.usersSource.deserializer=LINE
//每个Event数据所包含的最大字符数,如果每一行文本字符超过这个配置就会被截断,剩下的字符会出现在后面的Event数据里,默认值为2048
users.sources.usersSource.deserializer.maxLineLength=10000
//定义拦截器的名称
users.sources.usersSource.interceptors=head_filter
//组件类型,这个是:regex_filter 正则过滤拦截器
users.sources.usersSource.interceptors.head_filter.type=regex_filter
//使用正则表达式找到以user_id为开头
users.sources.usersSource.interceptors.head_filter.regex=^user_id*
//为true,被正则匹配到的Event会被丢弃;如果为false,不被正则匹配到的Event会被丢弃
users.sources.usersSource.interceptors.head_filter.excludeEvents=true
//组件类型为file
users.channels.usersChannel.type=file
//记录检查点的文件的存储目录
users.channels.usersChannel.checkpointDir=/opt/flume160/conf/jobkb09/cheakPointFile/users
//逗号分隔的目录列表,用于存储日志文件
users.channels.usersChannel.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/users
//将Event写入Hadoop分布式存储系统(HDFS)
users.sinks.usersSink.type=hdfs
//存储的文件格式
users.sinks.usersSink.hdfs.fileType=DataStream
//在HDFS文件夹下创建新文件的固定前缀
users.sinks.usersSink.hdfs.filePrefix=users
//在HDFS文件夹下创建新文件的后缀
users.sinks.usersSink.hdfs.fileSuffix=.csv
//HDFS的目录路径
users.sinks.usersSink.hdfs.path=hdfs://192.168.136.100:9000/kb09file/user/users/%Y-%m-%d
//使用日期时间转义符时是否使用本地时间戳
users.sinks.usersSink.hdfs.useLocalTimeStamp=true
//向HDFS写入内容时每次批量操作的Event数量,默认值是100
users.sinks.usersSink.hdfs.batchSize=640
//当前文件写入Event达到该数量后触发滚动创建新文件(0表示不根据Event数量来分割文件),默认是10
users.sinks.usersSink.hdfs.rollCount=0
//当前文件写入达到该大小后触发滚动创建新文件(0表示不根据文件大小来分隔文件),单位:字节 默认值1024字节=1k
users.sinks.usersSink.hdfs.rollSize=120000000
//表示每个20秒创建一个新文件进行存储,如果设置为0,表示所有Event都会写到一个文件中,默认值是30
users.sinks.usersSink.hdfs.rollInterval=20
//把Event中的组件根据中间的channel进行绑定
users.sources.usersSource.channels=usersChannel
users.sinks.usersSink.channel=usersChannel
- 保存退出,创建相应的文件夹
[root@hadoop100 jobkb09]# mkdir dataSourceFile/users
[root@hadoop100 jobkb09]# mkdir dataChannelFile/users
[root@hadoop100 jobkb09]# mkdir cheakPointFile/users
- 运行flume监控文件上传到HDFS
[root@hadoop100 flume160]# flume-ng agent --name users --conf conf/ --conf-file conf/jobkb09/users-flume-hdfs.conf -Dflume.root.logger=INFO,console
- 拷贝文件users.csv文件到dataSource目录下的users目录下
[root@hadoop100 tmp]# cp users.csv /opt/flume160/conf/jobkb09/dataSourceFile/users/users_2020-12-01.csv
- 查看flume是否监控成功
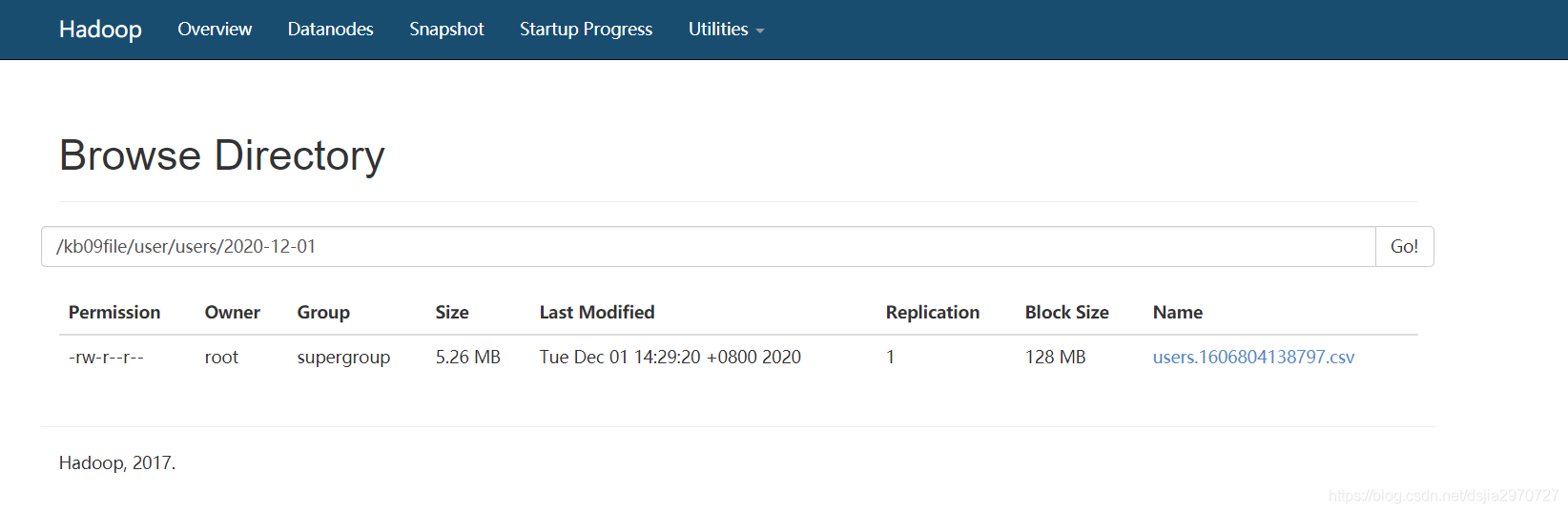
- 查看数据
[root@hadoop100 ~]# hdfs dfs -cat /kb09file/user/users/2020-12-01/users.1606804138797.csv

首行信息已经被我们去掉了
自定义拦截器
编写一个配置文件,让输入我们想要的文件进入一个文件下,其他的输入的进入另一个文件下
- 新建maven工程,添加依赖包
<!-- https://mvnrepository.com/artifact/org.apache.flume/flume-ng-core -->
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.6.0</version>
</dependency>
- 编写Java类
package nj.zb.kb09;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class InterceptorDemo implements Interceptor {
private List<Event> addHeaderEvetns;
@Override
public void initialize() {
addHeaderEvetns =new ArrayList<>();
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
Map<String, String> headers = event.getHeaders();
String bodyStr = new String(body);
if(bodyStr.startsWith("gree")){
headers.put("type","gree");
}else{
headers.put("type","lijia");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
addHeaderEvetns.clear();
for (Event event:events){
addHeaderEvetns.add(intercept(event));
}
return addHeaderEvetns;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new InterceptorDemo();
}
@Override
public void configure(Context context) {
}
}
}
- 给jar包打包
- 把jar包放入flume目录下的lib目录下
- 创建配置文件
[root@hadoop100 jobkb09]# netcat-flume-interceptor-hdfs.conf
- 输入如下信息
int.sources=intSource
int.channels=intChannel1 intChannel2
int.sinks=intSink1 intSink2
int.sources.intSource.type=netcat
int.sources.intSource.bind=localhost
int.sources.intSource.port=7777
int.sources.intSource.interceptors=iterceptor1
int.sources.intSource.interceptors.iterceptor1.type=nj.zb.kb09.InterceptorDemo$Builder
int.sources.intSource.selector.type=multiplexing
int.sources.intSource.selector.header=type
int.sources.intSource.selector.mapping.gree=intChannel1
int.sources.intSource.selector.mapping.lijia=intChannel2
int.channels.intChannel1.type=memory
int.channels.intChannel1.capacity=1000
int.channels.intChannel1.transactionCapacity=1000
int.channels.intChannel2.type=memory
int.channels.intChannel2.capacity=1000
int.channels.intChannel2.transactionCapacity=1000
int.sinks.intSink1.type=hdfs
int.sinks.intSink1.hdfs.fileType=DataStream
int.sinks.intSink1.hdfs.filePrefix=gree
int.sinks.intSink1.hdfs.fileSuffix=.csv
int.sinks.intSink1.hdfs.path=hdfs://192.168.136.100:9000/kb09file/user/gree/%Y-%m-%d
int.sinks.intSink1.hdfs.useLocalTimeStamp=true
int.sinks.intSink1.hdfs.batchSize=640
int.sinks.intSink1.hdfs.rollCount=0
int.sinks.intSink1.hdfs.rollSize=1000
int.sinks.intSink1.hdfs.rollInterval=3
int.sinks.intSink2.type=hdfs
int.sinks.intSink2.hdfs.fileType=DataStream
int.sinks.intSink2.hdfs.filePrefix=lijia
int.sinks.intSink2.hdfs.fileSuffix=.csv
int.sinks.intSink2.hdfs.path=hdfs://192.168.136.100:9000/kb09file/user/lijia/%Y-%m-%d
int.sinks.intSink2.hdfs.useLocalTimeStamp=true
int.sinks.intSink2.hdfs.batchSize=640
int.sinks.intSink2.hdfs.rollCount=0
int.sinks.intSink2.hdfs.rollSize=1000
int.sinks.intSink2.hdfs.rollInterval=3
int.sources.intSource.channels=intChannel1 intChannel2
int.sinks.intSink1.channel=intChannel1
int.sinks.intSink2.channel=intChannel2
- 保存退出,运行flume监控端口数据
[root@hadoop100 flume160]# flume-ng agent --name int --conf conf/ --conf-file conf/jobkb09/netcat-flume-interceptor-hdfs.conf -Dflume.root.logger=INFO,console
- 通过telnet向该端口发送数据
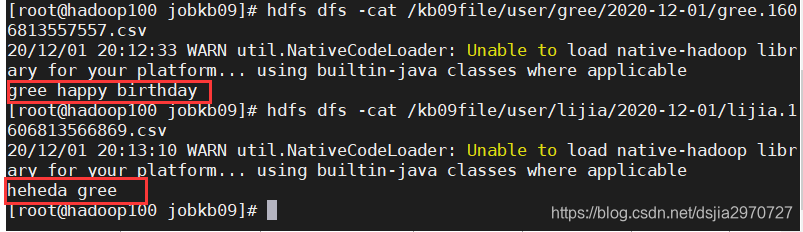
gree happy birthday
heheda gree
- 查看数据是否成功被拦截
[root@hadoop100 jobkb09]# hdfs dfs -cat /kb09file/user/gree/2020-12-01/gree.1606813557557.csv
[root@hadoop100 jobkb09]# hdfs dfs -cat /kb09file/user/lijia/2020-12-01/lijia.1606813566869.csv
配置文件让文件中包含kb07的部分进入kb07文件夹,让文件中包含kb09的部分进入kb09文件夹
- 编写jar包
package nj.zb.kb09;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class InterceptorDemo implements Interceptor {
private List<Event> addHeaderEvetns;
@Override
public void initialize() {
addHeaderEvetns =new ArrayList<>();
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
Map<String, String> headers = event.getHeaders();
String bodyStr = new String(body);
if(bodyStr.contains("kb09")){
headers.put("type","kb09");
}else{
headers.put("type","kb07");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
addHeaderEvetns.clear();
for (Event event:events){
addHeaderEvetns.add(intercept(event));
}
return addHeaderEvetns;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new InterceptorDemo();
}
@Override
public void configure(Context context) {
}
}
}
- 给jar包打包
- 把jar包放入flume目录下的lib目录下
- 创建配置文件
kb.sources=kbSource
kb.channels=kbChannel1 kbChannel2
kb.sinks=kbSink1 kbSink2
kb.sources.kbSource.type=spooldir
kb.sources.kbSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/kb09
kb.sources.kbSource.deserializer=LINE
kb.sources.kbSource.deserializer.maxLineLength=10000
kb.sources.kbSource.includePattern=kb09_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
kb.sources.kbSource.interceptors=iterceptor1
kb.sources.kbSource.interceptors.iterceptor1.type=nj.zb.kb09.InterceptorDemo$Builder
kb.sources.kbSource.selector.type=multiplexing
kb.sources.kbSource.selector.header=type
kb.sources.kbSource.selector.mapping.kb09=kbChannel1
kb.sources.kbSource.selector.mapping.kb07=kbChannel2
kb.channels.kbChannel1.type=file
kb.channels.kbChannel1.checkpointDir=/opt/flume160/conf/jobkb09/cheakPointFile/kb09
kb.channels.kbChannel1.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/kb09
kb.channels.kbChannel2.type=file
kb.channels.kbChannel2.checkpointDir=/opt/flume160/conf/jobkb09/cheakPointFile/kb07
kb.channels.kbChannel2.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/kb07
kb.sinks.kbSink1.type=hdfs
kb.sinks.kbSink1.hdfs.fileType=DataStream
kb.sinks.kbSink1.hdfs.filePrefix=kb09
kb.sinks.kbSink1.hdfs.fileSuffix=.csv
kb.sinks.kbSink1.hdfs.path=hdfs://192.168.136.100:9000/kb09file/user/kb09/%Y-%m-%d
kb.sinks.kbSink1.hdfs.useLocalTimeStamp=true
kb.sinks.kbSink1.hdfs.batchSize=640
kb.sinks.kbSink1.hdfs.rollCount=0
kb.sinks.kbSink1.hdfs.rollSize=1000
kb.sinks.kbSink1.hdfs.rollInterval=3
kb.sinks.kbSink2.type=hdfs
kb.sinks.kbSink2.hdfs.fileType=DataStream
kb.sinks.kbSink2.hdfs.filePrefix=kb07
kb.sinks.kbSink2.hdfs.fileSuffix=.csv
kb.sinks.kbSink2.hdfs.path=hdfs://192.168.136.100:9000/kb09file/user/kb07/%Y-%m-%d
kb.sinks.kbSink2.hdfs.useLocalTimeStamp=true
kb.sinks.kbSink2.hdfs.batchSize=640
kb.sinks.kbSink2.hdfs.rollCount=0
kb.sinks.kbSink2.hdfs.rollSize=1000
kb.sinks.kbSink2.hdfs.rollInterval=3
kb.sources.kbSource.channels=kbChannel1 kbChannel2
kb.sinks.kbSink1.channel=kbChannel1
kb.sinks.kbSink2.channel=kbChannel2
- 保存退出,创建所需文件夹
[root@hadoop100 jobkb09]# mkdir dataSourceFile/kb09
[root@hadoop100 jobkb09]# mkdir cheakPointFile/kb07
[root@hadoop100 jobkb09]# mkdir cheakPointFile/kb09
[root@hadoop100 jobkb09]# mkdir dataChannelFile/kb07
[root@hadoop100 jobkb09]# mkdir dataChannelFile/kb09
- 运行flume监控写入HDFS的文件信息
[root@hadoop100 flume160]# flume-ng agent -n kb -c conf/ -f conf/jobkb09/filekb09-flume-interceptor2-hdfs.conf -Dflume.root.logger=INFO,console
- 拷贝kb09.csv文件至dataSourceFile目录下的kb09目录下
[root@hadoop100 tmp]# cp kb09.csv /opt/flume160/conf/jobkb09/dataSourceFile/kb09/kb09_2020-12-01.csv
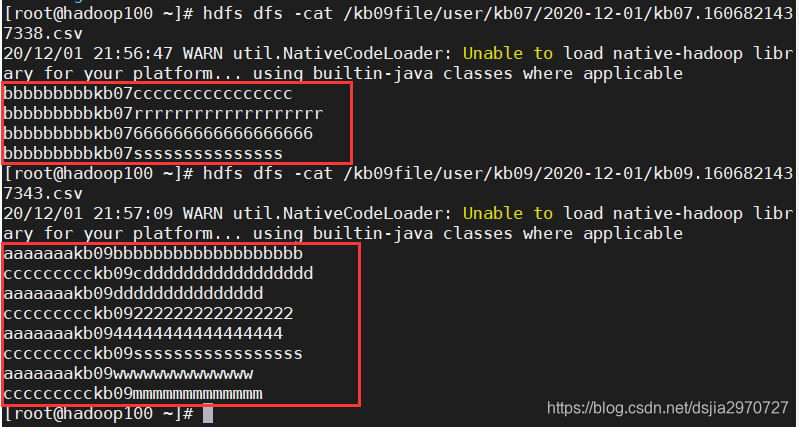
- kb09.csv中的数据
aaaaaaakb09bbbbbbbbbbbbbbbbbbb
bbbbbbbbbkb07cccccccccccccccc
ccccccccckb09cddddddddddddddddd
aaaaaaakb09ddddddddddddddd
bbbbbbbbbkb07rrrrrrrrrrrrrrrrrrr
ccccccccckb092222222222222222
aaaaaaakb0944444444444444444
bbbbbbbbbkb07666666666666666666
ccccccccckb09sssssssssssssssss
aaaaaaakb09wwwwwwwwwwwwww
bbbbbbbbbkb07sssssssssssssss
ccccccccckb09mmmmmmmmmmmmm
- 查看数据是否被拦截成功
[root@hadoop100 ~]# hdfs dfs -cat /kb09file/user/kb07/2020-12-01/kb07.1606821437338.csv
[root@hadoop100 ~]# hdfs dfs -cat /kb09file/user/kb09/2020-12-01/kb09.1606821437343.csv















 1496
1496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









