







 本文详细介绍了如何使用Python爬虫抓取豆瓣电影TOP250的电影信息,包括标题、描述、评分、评论数和经典影评。通过分析网页结构,确定XPath路径,结合requests和lxml库实现数据抓取。完整代码和分析可在GitHub查阅。
本文详细介绍了如何使用Python爬虫抓取豆瓣电影TOP250的电影信息,包括标题、描述、评分、评论数和经典影评。通过分析网页结构,确定XPath路径,结合requests和lxml库实现数据抓取。完整代码和分析可在GitHub查阅。
全部代码以及分析见GitHub:https://github.com/dta0502/douban-top250
本文是Python爬取豆瓣的top250电影的分析和实现,具体是将电影的标题、电影描述、电影的评分、电影的评论数以及电影的一句影评抓取下来,然后输出csv文件。
- 第一步:打开豆瓣电影top250这个页面。
- 第二步:分析网页源代码,找到我们需要爬取的信息的标签,例如电影title的标签等等是什么。
- 第三步:写代码了,将整个html请求下来,然后解析网页,获取我们需要的信息,利用lxml进行解析。
网页分析
首先打开豆瓣电影top250,我们可以看到电影是按照一个列表呈现出来的,页面是通过最底部的12345…来进行翻页查看的。
定位页面元素
我通过chrome的开发者工具来分析页面元素。下面是chrome的检查的页面:
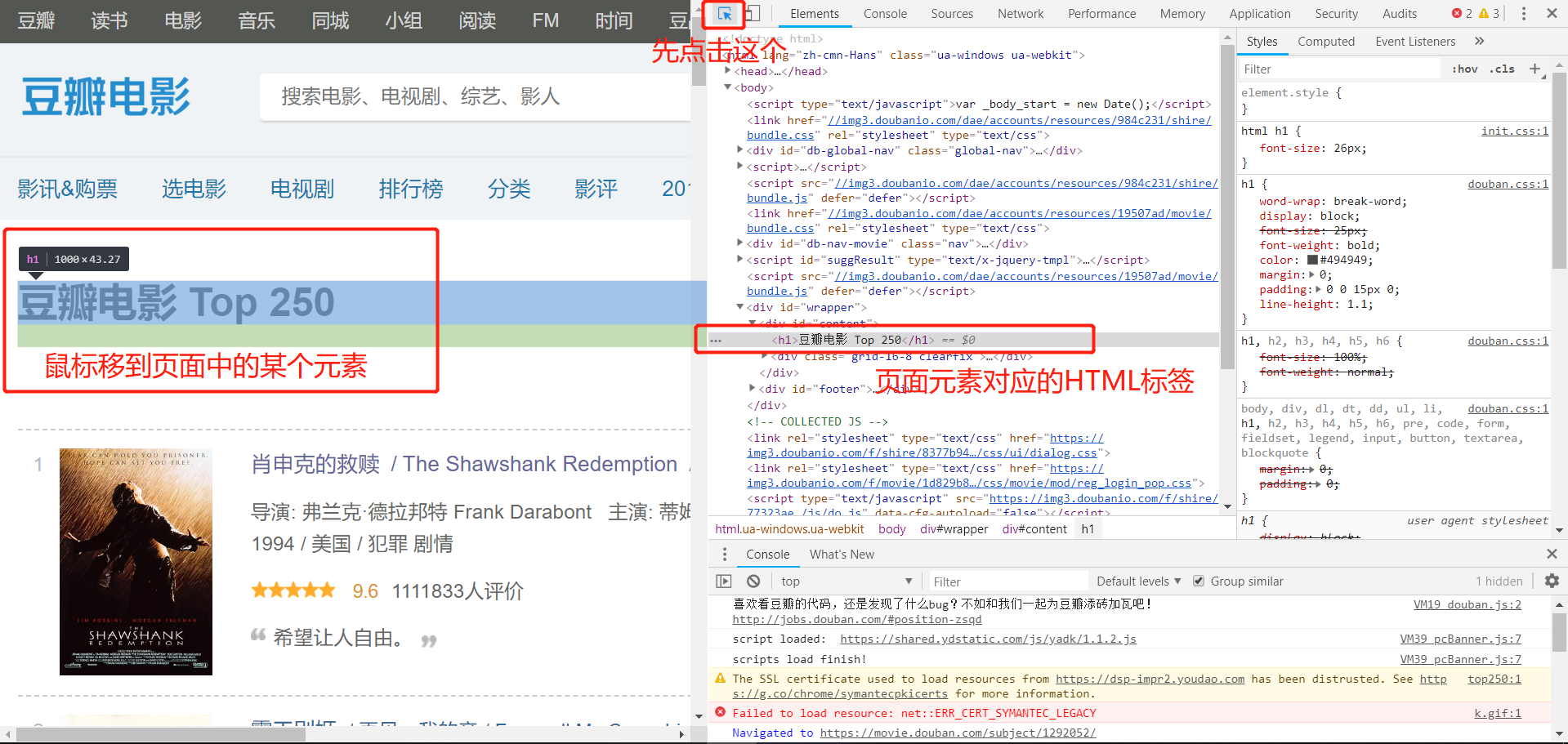
点击上图中画圆圈的图标,然后自己鼠标在页面上选中一部分,就会直接定位到具体的地方了。
电影信息的位置
通过上面所说的方法,我们可以观察得到所有列表是放在一个class = ‘grid_view’的ol标签中的,这个标签下的每一个li标签就是每一部电影信息的Item。
ol标签的XPath路径
//*[@id="content"]/div/div[1]/ol电影标题的XPath路径
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]电影的描述
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/p[1]电影评分的XPath路径
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/div/span[2]电影评论数的XPath路径
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/div/span[4]电影的一句经典影评
//*[@id="content"]/div/div[1]/ol/li[1]/div 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









