







Llama3.1-8B-Instruct 本地部署安装测试指南
在本文中,将一步步指导你如何在本地环境中部署和测试 Llama3.1-8B-Instruct模型。
Llama3.1 模型简介
-
Llama 3.2:Llama 3.2多语言大型语言模型(LLM)集合是1B和3B大小(文本输入/文本输出)的预训练和指令调整生成模型的集合。
-
Llama 3.2视觉:Llama 3.2-Vision集合的多模态大型语言模型(LLM)是一个预先训练和调整的图像推理生成模型的集合,大小为11B和90 B(文本+图像输入/文本输出)
-
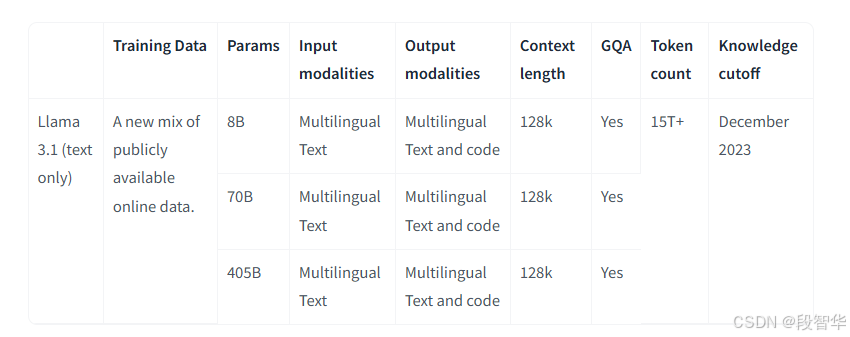
Llama 3.1:一组预训练和微调的文本模型,大小从80亿到4050亿,在大约15万亿个标记上进行预训练。
-
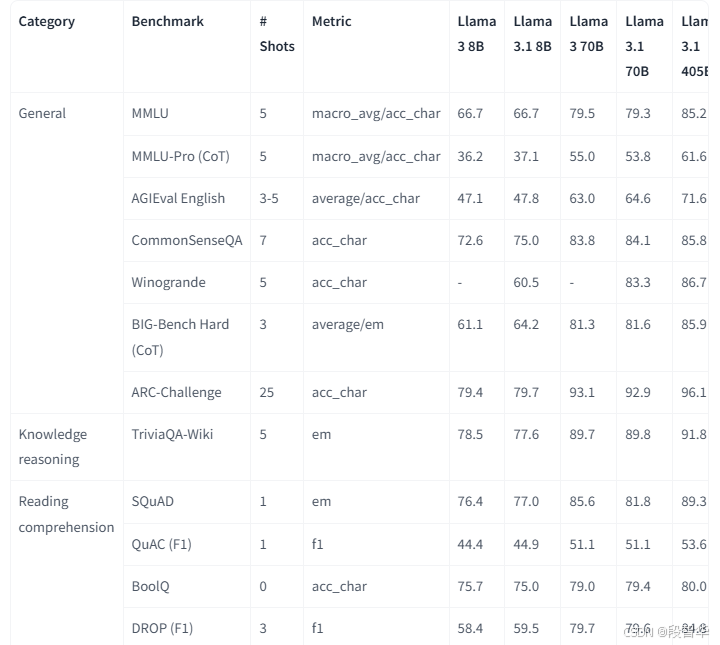
Llama 3.1评估:该集合提供了有关如何为Llama 3.1模型获得报告的基准指标的详细信息,包括用于生成评估结果的配置,提示和模型响应。
下载模型
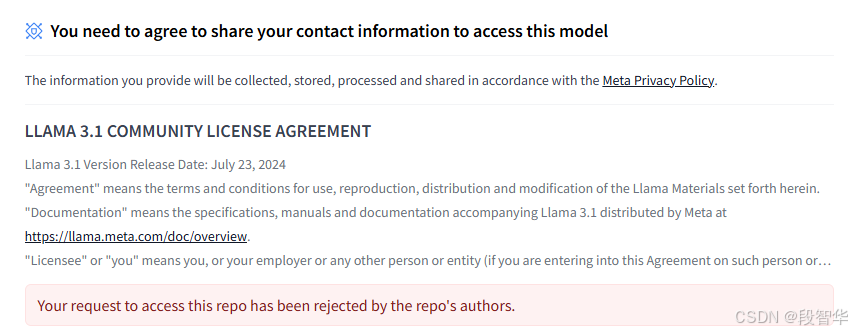
Llama3.1-8B-Instruct 模型可以从 Hugging Face 的模型库中获取。如果Hugging Face申请权限被拒,
可以从Llama官网申请url模型下载。
https://www.llama.com/llama-downloads
在注册邮箱中会收到Meta公司的邮件
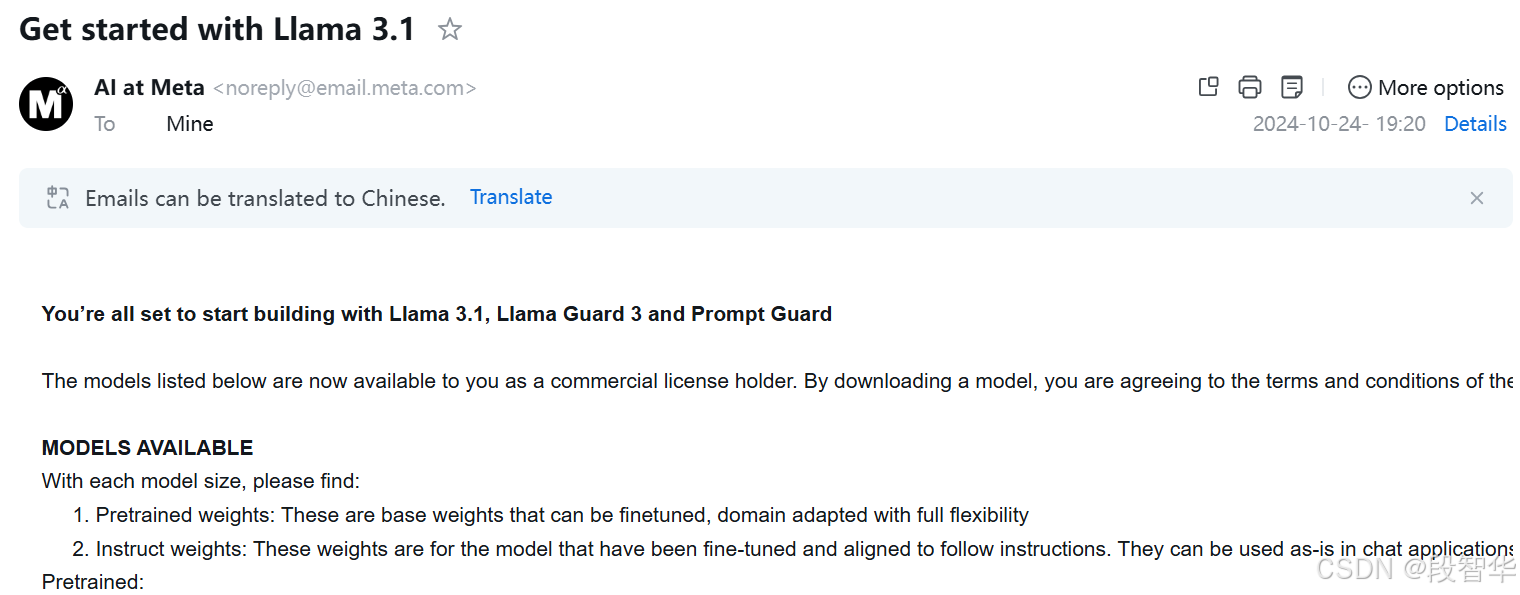
You’re all set to start building with Llama 3.1, Llama Guard 3 and Prompt Guard The models listed below are now available to you as a commercial license holder. By downloading a model, you are agreeing to the terms and conditions of the License and Acceptable Use Policy and Meta’s privacy policy . MODELS AVAILABLE With each model size, please find: Pretrained weights: These are base weights that can be finetuned, domain adapted with full flexibility Instruct weights: These weights are for the model that have been fine-tuned and aligned to follow instructions. They can be used as-is in chat applications or further finetuned and aligned for specific use cases Pretrained: Meta-Llama-3.1-8B Meta-Llama-3.1-70B Meta-Llama-3.1-405B Meta-Llama-3.1-405B-MP16 Meta-Llama-3.1-405B-FP8 Fine-tuned: Meta-Llama-3.1-8B-Instruct Meta-Llama-3.1-70B-Instruct Meta-Llama-3.1-405B-Instruct Meta-Llama-3.1-405B-Instruct-MP16 Meta-Llama-3.1-405B-Instruct-FP8 Llama-Guard-3-8B Llama-Guard-3-8B-INT8 Prompt-Guard-86M NOTE 405B: Model requires significant storage and computational resources, occupying approximately 750GB of disk storage space and necessitating two nodes on MP16 for inferencing. We are releasing multiple versions of the 405B model to accommodate its large size and facilitate multiple deployment options: MP16 (Model Parallel 16) is the full version of BF16 weights. These weights can only be served on multiple nodes using pipelined parallel inference. At minimum it would need 2 nodes of 8 GPUs to serve. MP8 (Model Parallel 8) is also the full version of BF16 weights, but can be served on a single node with 8 GPUs by using dynamic FP8 (floating point 8) quantization. We are providing reference code for it. You can download these weights and experiment with different quantization techniques outside of what we are providing. FP8 (Floating Point 8) is a quantized version of the weights. These weights can be served on a single node with 8 GPUs by using the static FP quantization. We have provided reference code for it as well. HOW TO DOWNLOAD THE MODEL Visit the Llama Models repository for the model on GitHub and follow the instructions in the README to choose and download the model using Llama CLI. Pass the custom URL below when prompted to start the download. (Clicking on the URL itself does not access the model): https://llama3-1.llamameta.net/*?Policy=eyJTdGF0ZW1lbnQiOlt7InVuaXF1ZV9oYXNoIjoiamRpMndyeWhpMHV3ZDhycHluczNuZXVmIiwiUmVzb3VyY2UiOiJodHRwczpcL1wvbGxhbWEzLTEubGxhbWFtZXRhLm5ldFwvKiIsIkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTcyOTk0MTY1OH19fV19&Signature=jTSu4li55ZUiVycY6fLmE8dA6dx6oxAh7PZ-%7ENbdcKoqdubi5jiSBaHETzwzjweyIg7Bme2wQ1LKfjrsmXNXS8SqS6NtT9HkZbW9DlmVNyElqQAN5LULBovay4EkzMvu-N2Z-Fn2mWU52g8rlzkOSYMDBSI33fQE5sSqgGTcMUM1WOwb5QoSJHCaiB-6DD91h65wHxLgMPJ-z5vQzOGMZ0wXy910XqNSzvHyVTC9c%7EBeLCIgEaOLW83MelgzDDGNY0pg3vkH2VBfsmG8AYZh2a2ncCXDJI7rPGhiOyki%7EmHBcRgtqavOBgQvxf9fX-EQAxY3rRRpScPqcIy%7EkPjB7Q__&Key-Pair-Id=K15QRJLYKIFSLZ&Download-Request-ID=1672763443517196 Specify models to download. Please save copies of the unique custom URLs provided above, they will remain valid for 24 hours to download each model up to 5 times, and requests can be submitted multiple times. An email with the download instructions will also be sent to the email address you used to request the models. Now you’re ready to start building with Llama 3.1, Llama Guard 3 and Prompt Guard. HELPFUL TIPS: Please read the instructions in the GitHub repo and use the provided code examples to understand how to best interact with the models. In particular, for the fine-tuned models you must use appropriate formatting and correct system/instruction tokens to get the best results from the model. You can find additional information about how to responsibly deploy Llama models in our Responsible Use Guide . IF YOU NEED TO REPORT ISSUES: If you or any Llama user becomes aware of any violation of our license or acceptable use policies—or any bug or issues with Llama that could lead to any such violations—please report it through one of the following means: Reporting issues with the model: https://github.com/meta-llama/llama-models/issues Giving feedback about potentially problematic output generated by the model: http://developers.facebook.com/llama_output_feedback Reporting bugs and security concerns: facebook.com/whitehat/info Reporting violations of the Acceptable Use Policy: LlamaUseReport@meta.com Subscribe to get the latest updates on Llama 3.1 and AI at Meta. Meta GenAI Team
You’re all set to start building with Llama 3.1, Llama Guard 3 and Prompt Guard
The models listed below are now available to you as a commercial license holder. By downloading a model, you are agreeing to the terms and conditions of the License and Acceptable Use Policy and Meta’s privacy policy.
MODELS AVAILABLE
With each model size, please find:
Pretrained weights: These are base weights that can be finetuned, domain adapted with full flexibility
Instruct weights: These weights are for the model that have been fine-tuned and aligned to follow instructions. They can be used as-is in chat applications or further finetuned and aligned for specific use cases
Pretrained:
Meta-Llama-3.1-8B
Meta-Llama-3.1-70B
Meta-Llama-3.1-405B
Meta-Llama-3.1-405B-MP16
Meta-Llama-3.1-405B-FP8
Fine-tuned:
Meta-Llama-3.1-8B-Instruct
Meta-Llama-3.1-70B-Instruct
Meta-Llama-3.1-405B-Instruct
Meta-Llama-3.1-405B-Instruct-MP16
Meta-Llama-3.1-405B-Instruct-FP8
Llama-Guard-3-8B
Llama-Guard-3-8B-INT8
Prompt-Guard-86M
NOTE 405B:
Model requires significant storage and computational resources, occupying approximately 750GB of disk storage space and necessitating two nodes on MP16 for inferencing.
We are releasing multiple versions of the 405B model to accommodate its large size and facilitate multiple deployment options: MP16 (Model Parallel 16) is the full version of BF16 weights. These weights can only be served on multiple nodes using pipelined parallel inference. At minimum it would need 2 nodes of 8 GPUs to serve.
MP8 (Model Parallel 8) is also the full version of BF16 weights, but can be served on a single node with 8 GPUs by using dynamic FP8 (floating point 8) quantization. We are providing reference code for it. You can download these weights and experiment with different quantization techniques outside of what we are providing.
FP8 (Floating Point 8) is a quantized version of the weights. These weights can be served on a single node with 8 GPUs by using the static FP quantization. We have provided reference code for it as well.
HOW TO DOWNLOAD THE MODEL
Visit the Llama Models repository for the model on GitHub and follow the instructions in the README to choose and download the model using Llama CLI. Pass the custom URL below when prompted to start the download. (Clicking on the URL itself does not access the model):
https://llama3-1.llamameta.net/*?Policy=eyJTdGF0ZW1lbnQiOlt7InVuaXF1ZV9oYXNoIjoiamRpMndyeWhpMHV3ZDhycHluczNuZXVmIiwiUmVzb3VyY2UiOiJodHRwczpcL1wvbGxhbWEzLTEubGxhbWFtZXRhLm5ldFwvKiIsIkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTcyOTk0MTY1OH19fV19&Signature=jTSu4li55ZUiVycY6fLmE8dA6dx6oxAh7PZ-%7ENbdcKoqdubi5jiSBaHETzwzjweyIg7Bme2wQ1LKfjrsmXNXS8SqS6NtT9HkZbW9DlmVNyElqQAN5LULBovay4EkzMvu-N2Z-Fn2mWU52g8rlzkOSYMDBSI33fQE5sSqgGTcMUM1WOwb5QoSJHCaiB-6DD91h65wHxLgMPJ-z5vQzOGMZ0wXy910XqNSzvHyVTC9c%7EBeLCIgEaOLW83MelgzDDGNY0pg3vkH2VBfsmG8AYZh2a2ncCXDJI7rPGhiOyki%7EmHBcRgtqavOBgQvxf9fX-EQAxY3rRRpScPqcIy%7EkPjB7Q__&Key-Pair-Id=K15QRJLYKIFSLZ&Download-Request-ID=1672763443517196
Specify models to download.
Please save copies of the unique custom URLs provided above, they will remain valid for 24 hours to download each model up to 5 times, and requests can be submitted multiple times. An email with the download instructions will also be sent to the email address you used to request the models.
Now you’re ready to start building with Llama 3.1, Llama Guard 3 and Prompt Guard.
HELPFUL TIPS:
Please read the instructions in the GitHub repo and use the provided code examples to understand how to best interact with the models. In particular, for the fine-tuned models you must use appropriate formatting and correct system/instruction tokens to get the best results from the model.
You can find additional information about how to responsibly deploy Llama models in our Responsible Use Guide.
IF YOU NEED TO REPORT ISSUES:
If you or any Llama user becomes aware of any violation of our license or acceptable use policies—or any bug or issues with Llama that could lead to any such violations—please report it through one of the following means:
Reporting issues with the model: https://github.com/meta-llama/llama-models/issues
Giving feedback about potentially problematic output generated by the model: http://developers.facebook.com/llama_output_feedback
Reporting bugs and security concerns: facebook.com/whitehat/info
Reporting violations of the Acceptable Use Policy: LlamaUseReport@meta.com
Subscribe to get the latest updates on Llama 3.1 and AI at Meta.
Meta GenAI Team
下载模型
https://github.com/meta-llama/llama-models?tab=readme-ov-file#download
-
在首选环境中运行以下命令:
pip install llama-stack -
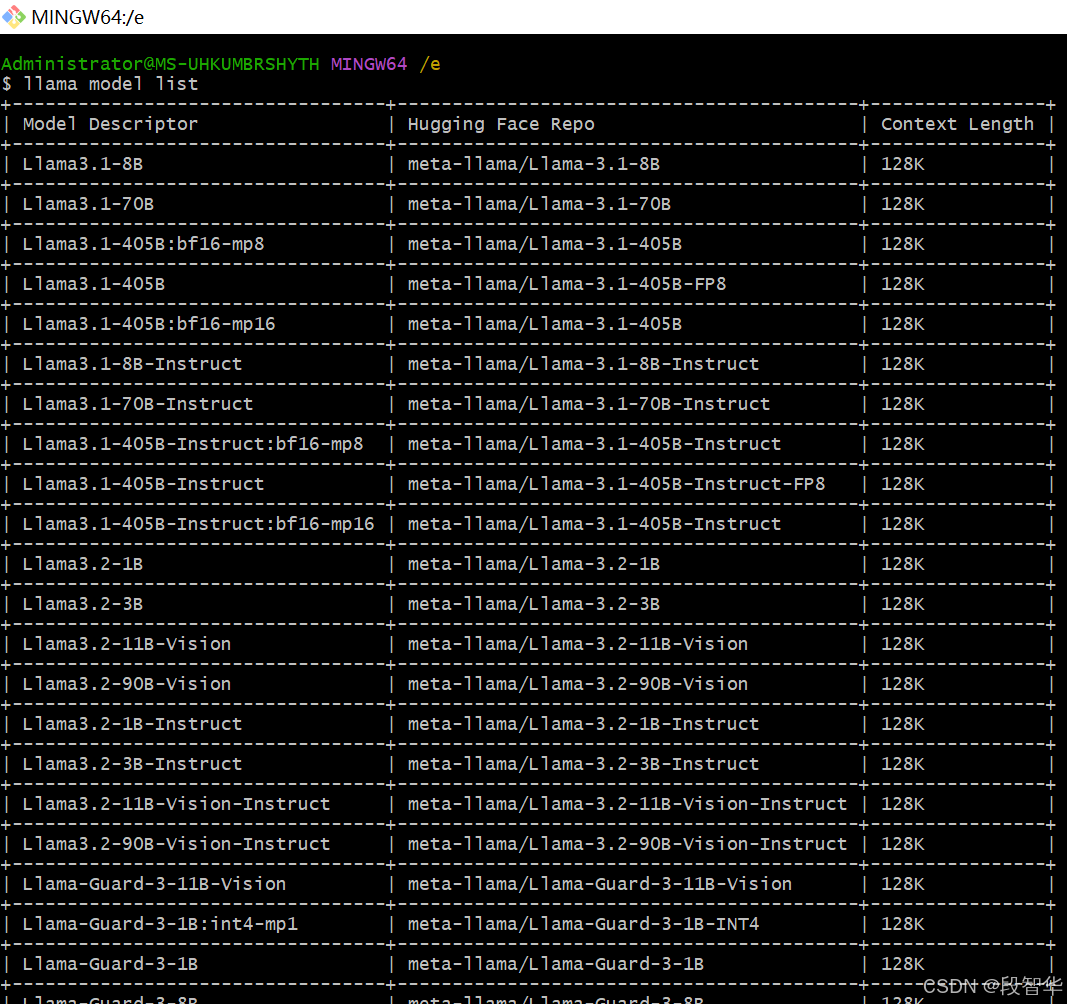
查找模型列表
llama model list
- 选择一个模型
通过运行以下命令选择所需的模型:
llama model download --source meta --model-id Llama3.1-8B-Instruct
-指定自定义URL
下载的Llama3.1-8B-Instruct 文件
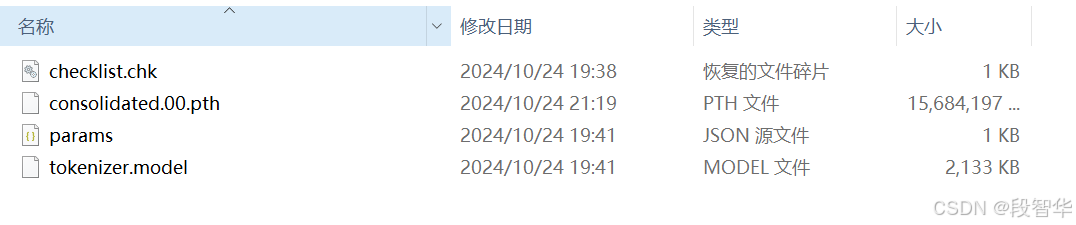
上传至服务器

转换模型权重
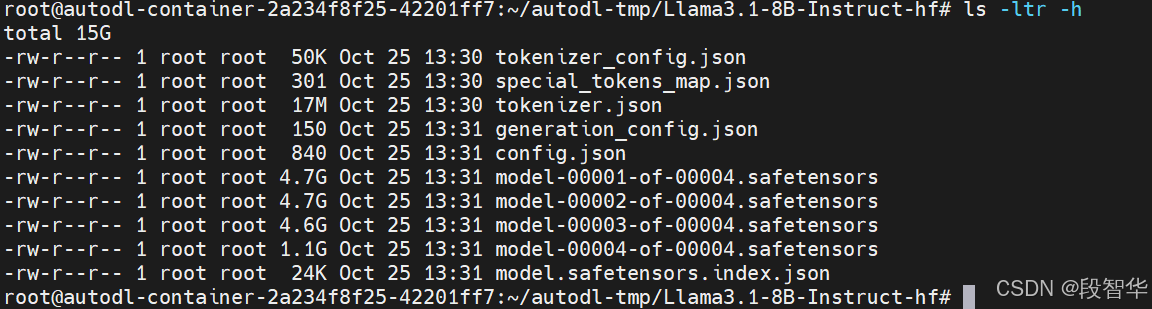
下载到模型权重不是以 Hugging Face 的格式存储的,需要将其转换。运行一个脚本来将原始的 .pth 文件转换为 Hugging Face的文件,这是 Transformers 库使用的格式。
python convert_llama_weights_to_hf.py --input_dir /root/autodl-tmp/Llama3.1-8B-Instruct/ --model_size 8B --output_dir /root/autodl-tmp/Llama3.1-8B-Instruct-hf/ --llama_version 3.1
该命令是用于将 Llama3.1-8B-Instruct 模型的权重从原始的 .pth 格式转换为 Hugging Face transformers 库所使用的格式。下面是命令中各个参数的说明:
-
python convert_llama_weights_to_hf.py:这是用来执行转换脚本的 Python 命令。
-
input_dir /root/autodl-tmp/Llama3.1-8B-Instruct/:这个参数指定了原始模型权重文件所在的目录。在这个例子中,权重文件位于 /root/autodl-tmp/Llama3.1-8B-Instruct/ 目录下。

-
model_size 8B:这个参数表明模型的大小是 8B(即 80 亿参数)。这有助于脚本正确地处理不同大小的模型。
-
output_dir /root/autodl-tmp/Llama3.1-8B-Instruct-hf/:这个参数指定了转换后的模型权重文件的输出目录。在这个例子中,转换后的文件将被保存在 /root/autodl-tmp/Llama3.1-8B-Instruct-hf/ 目录下。
-
llama_version 3.1:这个参数指定了 Llama 模型的版本,这里是 3.1 版本。用于脚本内部逻辑,以确保正确处理特定版本的模型权重。
在终端中运行这个命令时,它会启动转换过程,将原始的 .pth 文件转换成 Hugging Face 格式的 .bin 文件,并将它们保存在指定的输出目录中。转换完成后,你就可以使用 Hugging Face 的 transformers 库来加载和使用这个模型了。

convert_llama_weights_to_hf.py 的代码:https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py
# Copyright 2022 EleutherAI and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import gc
import json
import os
import tempfile
import warnings
from typing import List
import torch
from tokenizers import AddedToken, processors
from transformers import GenerationConfig, LlamaConfig, LlamaForCausalLM, LlamaTokenizer, PreTrainedTokenizerFast
from transformers.convert_slow_tokenizer import TikTokenConverter
try:
from transformers import LlamaTokenizerFast
except ImportError as e:
warnings.warn(e)
warnings.warn(
"The converted tokenizer will be the `slow` tokenizer. To use the fast, update your `tokenizers` library and re-run the tokenizer conversion"
)
LlamaTokenizerFast = None
"""
Sample usage:
###
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 1B --llama_version 3.2 --output_dir /output/path
###
Thereafter, models can be loaded via:
###py
from transformers import LlamaForCausalLM, LlamaTokenizer
model = LlamaForCausalLM.from_pretrained("/output/path")
tokenizer = LlamaTokenizer.from_pretrained("/output/path")
###
Important note: you need to be able to host the whole model in RAM to execute this script (even if the biggest versions
come in several checkpoints they each contain a part of each weight of the model, so we need to load them all in RAM).
If you want your tokenizer to add a bos automatically you should update the tokenizer._tokenizers.post_processor:
###py
from tokenizers import processors
bos = "<|begin_of_text|>"
tokenizer._tokenizers.post_processor = processors.Sequence(
[
processors.ByteLevel(trim_offsets=False),
processors.TemplateProcessing(
single=f"{bos}:0 $A:0",
pair=f"{bos}:0 $A:0 {bos}:1 $B:1",
special_tokens=[
(bos, tokenizer.encode(bos)),
],
),
]
)
###
"""
NUM_SHARDS = {
"1B": 1,
"3B": 1,
"7B": 1,
"8B": 1,
"8Bf": 1,
"7Bf": 1,
"13B": 2,
"13Bf": 2,
"34B": 4,
"30B": 4,
"65B": 8,
"70B": 8,
"70Bf": 8,
"405B": 8,
"405B-MP16": 16,
}
CONTEXT_LENGTH_FOR_VERSION = {"Guard-3": 131072, "3.2": 131072, "3.1": 131072, "3": 8192, "2": 4096, "1": 2048}
BOS_ADDED_TOKEN = AddedToken(
"<|begin_of_text|>", single_word=False, lstrip=False, rstrip=False, normalized=False, special=True
)
EOS_ADDED_TOKEN = AddedToken(
"<|end_of_text|>", single_word=False, lstrip=False, rstrip=False, normalized=False, special=True
)
EOT_ADDED_TOKEN = AddedToken(
"<|eot_id|>", single_word=False, lstrip=False, rstrip=False, normalized=False, special=True
)
DEFAULT_LLAMA_SPECIAL_TOKENS = {
"3": [
"<|begin_of_text|>",
"<|end_of_text|>",
"<|reserved_special_token_0|>",
"<|reserved_special_token_1|>",
"<|reserved_special_token_2|>",
"<|reserved_special_token_3|>",
"<|start_header_id|>",
"<|end_header_id|>",
"<|reserved_special_token_4|>",
"<|eot_id|>", # end of turn
]
+ [f"<|reserved_special_token_{i}|>" for i in range(5, 256 - 5)],
"3.1": [
"<|begin_of_text|>",
"<|end_of_text|>",
"<|reserved_special_token_0|>",
"<|reserved_special_token_1|>",
"<|finetune_right_pad_id|>",
"<|reserved_special_token_2|>",
"<|start_header_id|>",
"<|end_header_id|>",
"<|eom_id|>", # end of message
"<|eot_id|>", # end of turn
"<|python_tag|>",
]
+ [f"<|reserved_special_token_{i}|>" for i in range(3, 256 - 8)],
"3.2": [
"<|begin_of_text|>",
"<|end_of_text|>",
"<|reserved_special_token_0|>",
"<|reserved_special_token_1|>",
"<|finetune_right_pad_id|>",
"<|reserved_special_token_2|>",
"<|start_header_id|>",
"<|end_header_id|>",
"<|eom_id|>", # end of message
"<|eot_id|>", # end of turn
"<|python_tag|>",
]
+ [f"<|reserved_special_token_{i}|>" for i in range(3, 256 - 8)],
"Guard-3": [
"<|begin_of_text|>",
"<|end_of_text|>",
"<|reserved_special_token_0|>",
"<|reserved_special_token_1|>",
"<|finetune_right_pad_id|>",
"<|reserved_special_token_2|>",
"<|start_header_id|>",
"<|end_header_id|>",
"<|eom_id|>", # end of message
"<|eot_id|>", # end of turn
"<|python_tag|>",
]
+ [f"<|reserved_special_token_{i}|>" for i in range(3, 256 - 8)],
}
def is_llama_3(version):
return version in ["3", "3.1", "3.2", "Guard-3"]
def compute_intermediate_size(n, ffn_dim_multiplier=1, multiple_of=256):
return multiple_of * ((int(ffn_dim_multiplier * int(8 * n / 3)) + multiple_of - 1) // multiple_of)
def read_json(path):
with open(path, "r") as f:
return json.load(f)
def write_json(text, path):
with open(path, "w") as f:
json.dump(text, f)
def write_model(
model_path,
input_base_path,
model_size=None,
safe_serialization=True,
llama_version="1",
vocab_size=None,
num_shards=None,
instruct=False,
push_to_hub=False,
):
print("Converting the model.")
params = read_json(os.path.join(input_base_path, "params.json"))
num_shards = NUM_SHARDS[model_size] if num_shards is None else num_shards
params = params.get("model", params)
n_layers = params["n_layers"]
n_heads = params["n_heads"]
n_heads_per_shard = n_heads // num_shards
dim = params["dim"]
dims_per_head = dim // n_heads
base = params.get("rope_theta", 10000.0)
inv_freq = 1.0 / (base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head))
if base > 10000.0 and not is_llama_3(llama_version):
max_position_embeddings = 16384
else:
max_position_embeddings = CONTEXT_LENGTH_FOR_VERSION[llama_version]
if params.get("n_kv_heads", None) is not None:
num_key_value_heads = params["n_kv_heads"] # for GQA / MQA
num_key_value_heads_per_shard = num_key_value_heads // num_shards
key_value_dim = dims_per_head * num_key_value_heads
else: # compatibility with other checkpoints
num_key_value_heads = n_heads
num_key_value_heads_per_shard = n_heads_per_shard
key_value_dim = dim
# permute for sliced rotary
def permute(w, n_heads, dim1=dim, dim2=dim):
return w.view(n_heads, dim1 // n_heads // 2, 2, dim2).transpose(1, 2).reshape(dim1, dim2)
with tempfile.TemporaryDirectory() as tmp_model_path:
print(f"Fetching all parameters from the checkpoint at {input_base_path}.")
# Load weights
if num_shards == 1:
# Not sharded
# (The sharded implementation would also work, but this is simpler.)
loaded = torch.load(os.path.join(input_base_path, "consolidated.00.pth"), map_location="cpu")
else:
# Sharded
checkpoint_list = sorted([file for file in os.listdir(input_base_path) if file.endswith(".pth")])
print("Loading in order:", checkpoint_list)
loaded = [torch.load(os.path.join(input_base_path, file), map_location="cpu") for file in checkpoint_list]
param_count = 0
index_dict = {"weight_map": {}}
for layer_i in range(n_layers):
filename = f"pytorch_model-{layer_i + 1}-of-{n_layers + 1}.bin"
if num_shards == 1:
# Unsharded
state_dict = {
f"model.layers.{layer_i}.self_attn.q_proj.weight": permute(
loaded[f"layers.{layer_i}.attention.wq.weight"], n_heads=n_heads
),
f"model.layers.{layer_i}.self_attn.k_proj.weight": permute(
loaded[f"layers.{layer_i}.attention.wk.weight"],
n_heads=num_key_value_heads,
dim1=key_value_dim,
),
f"model.layers.{layer_i}.self_attn.v_proj.weight": loaded[f"layers.{layer_i}.attention.wv.weight"],
f"model.layers.{layer_i}.self_attn.o_proj.weight": loaded[f"layers.{layer_i}.attention.wo.weight"],
f"model.layers.{layer_i}.mlp.gate_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w1.weight"],
f"model.layers.{layer_i}.mlp.down_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w2.weight"],
f"model.layers.{layer_i}.mlp.up_proj.weight": loaded[f"layers.{layer_i}.feed_forward.w3.weight"],
f"model.layers.{layer_i}.input_layernorm.weight": loaded[
f"layers.{layer_i}.attention_norm.weight"
],
f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[
f"layers.{layer_i}.ffn_norm.weight"
],
}
else:
# Sharded
# Note that attention.w{q,k,v,o}, feed_fordward.w[1,2,3], attention_norm.weight and ffn_norm.weight share
# the same storage object, saving attention_norm and ffn_norm will save other weights too, which is
# redundant as other weights will be stitched from multiple shards. To avoid that, they are cloned.
state_dict = {
f"model.layers.{layer_i}.input_layernorm.weight": loaded[0][
f"layers.{layer_i}.attention_norm.weight"
].clone(),
f"model.layers.{layer_i}.post_attention_layernorm.weight": loaded[0][
f"layers.{layer_i}.ffn_norm.weight"
].clone(),
}
state_dict[f"model.layers.{layer_i}.self_attn.q_proj.weight"] = permute(
torch.cat(
[
loaded[i][f"layers.{layer_i}.attention.wq.weight"].view(
n_heads_per_shard, dims_per_head, dim
)
for i in range(len(loaded))
],
dim=0,
).reshape(dim, dim),
n_heads=n_heads,
)
state_dict[f"model.layers.{layer_i}.self_attn.k_proj.weight"] = permute(
torch.cat(
[
loaded[i][f"layers.{layer_i}.attention.wk.weight"].view(
num_key_value_heads_per_shard, dims_per_head, dim
)
for i in range(len(loaded))
],
dim=0,
).reshape(key_value_dim, dim),
num_key_value_heads,
key_value_dim,
dim,
)
state_dict[f"model.layers.{layer_i}.self_attn.v_proj.weight"] = torch.cat(
[
loaded[i][f"layers.{layer_i}.attention.wv.weight"].view(
num_key_value_heads_per_shard, dims_per_head, dim
)
for i in range(len(loaded))
],
dim=0,
).reshape(key_value_dim, dim)
state_dict[f"model.layers.{layer_i}.self_attn.o_proj.weight"] = torch.cat(
[loaded[i][f"layers.{layer_i}.attention.wo.weight"] for i in range(len(loaded))], dim=1
)
state_dict[f"model.layers.{layer_i}.mlp.gate_proj.weight"] = torch.cat(
[loaded[i][f"layers.{layer_i}.feed_forward.w1.weight"] for i in range(len(loaded))], dim=0
)
state_dict[f"model.layers.{layer_i}.mlp.down_proj.weight"] = torch.cat(
[loaded[i][f"layers.{layer_i}.feed_forward.w2.weight"] for i in range(len(loaded))], dim=1
)
state_dict[f"model.layers.{layer_i}.mlp.up_proj.weight"] = torch.cat(
[loaded[i][f"layers.{layer_i}.feed_forward.w3.weight"] for i in range(len(loaded))], dim=0
)
state_dict[f"model.layers.{layer_i}.self_attn.rotary_emb.inv_freq"] = inv_freq
for k, v in state_dict.items():
index_dict["weight_map"][k] = filename
param_count += v.numel()
torch.save(state_dict, os.path.join(tmp_model_path, filename))
filename = f"pytorch_model-{n_layers + 1}-of-{n_layers + 1}.bin"
if num_shards == 1:
# Unsharded
state_dict = {
"model.embed_tokens.weight": loaded["tok_embeddings.weight"],
"model.norm.weight": loaded["norm.weight"],
"lm_head.weight": loaded["output.weight"],
}
else:
concat_dim = 0 if is_llama_3(llama_version) else 1
state_dict = {
"model.norm.weight": loaded[0]["norm.weight"],
"model.embed_tokens.weight": torch.cat(
[loaded[i]["tok_embeddings.weight"] for i in range(len(loaded))], dim=concat_dim
),
"lm_head.weight": torch.cat([loaded[i]["output.weight"] for i in range(len(loaded))], dim=0),
}
for k, v in state_dict.items():
index_dict["weight_map"][k] = filename
param_count += v.numel()
torch.save(state_dict, os.path.join(tmp_model_path, filename))
# Write configs
index_dict["metadata"] = {"total_size": param_count * 2}
write_json(index_dict, os.path.join(tmp_model_path, "pytorch_model.bin.index.json"))
ffn_dim_multiplier = params["ffn_dim_multiplier"] if "ffn_dim_multiplier" in params else 1
multiple_of = params["multiple_of"] if "multiple_of" in params else 256
if is_llama_3(llama_version):
bos_token_id = 128000
if instruct:
eos_token_id = [128001, 128008, 128009]
else:
eos_token_id = 128001
else:
bos_token_id = 1
eos_token_id = 2
if llama_version in ["3.1", "3.2", "Guard-3"]:
rope_scaling = {
"factor": 32.0 if llama_version == "3.2" else 8.0,
"low_freq_factor": 1.0,
"high_freq_factor": 4.0,
"original_max_position_embeddings": 8192,
"rope_type": "llama3",
}
else:
rope_scaling = None
config = LlamaConfig(
hidden_size=dim,
intermediate_size=compute_intermediate_size(dim, ffn_dim_multiplier, multiple_of),
num_attention_heads=params["n_heads"],
num_hidden_layers=params["n_layers"],
rms_norm_eps=params["norm_eps"],
num_key_value_heads=num_key_value_heads,
vocab_size=vocab_size,
rope_theta=base,
rope_scaling=rope_scaling,
max_position_embeddings=max_position_embeddings,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
tie_word_embeddings=True if llama_version in ["3.2"] else False,
)
config.save_pretrained(tmp_model_path)
generation_config = GenerationConfig(
do_sample=True,
temperature=0.6,
top_p=0.9,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
)
generation_config.save_pretrained(tmp_model_path)
# Make space so we can load the model properly now.
del state_dict
del loaded
gc.collect()
print("Loading the checkpoint in a Llama model.")
model = LlamaForCausalLM.from_pretrained(tmp_model_path, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True)
# Avoid saving this as part of the config.
del model.config._name_or_path
model.config.torch_dtype = torch.float16
print("Saving in the Transformers format.")
if push_to_hub:
print("Pushing to the hub.")
model.push_to_hub(model_path, safe_serialization=safe_serialization, private=True, use_temp_dir=True)
else:
print("Saving to disk.")
model.save_pretrained(model_path, safe_serialization=safe_serialization)
class Llama3Converter(TikTokenConverter):
def __init__(self, vocab_file, special_tokens=None, instruct=False, llama_version="3.2", **kwargs):
super().__init__(vocab_file, additional_special_tokens=special_tokens, **kwargs)
tokenizer = self.converted()
# References for chat templates in instruct models
templates_for_version = {
"2": ("meta-llama/Llama-2-7b-chat-hf", "f5db02db724555f92da89c216ac04704f23d4590"),
"3": ("meta-llama/Meta-Llama-3-8B-Instruct", "5f0b02c75b57c5855da9ae460ce51323ea669d8a"),
"3.1": ("meta-llama/Llama-3.1-8B-Instruct", "0e9e39f249a16976918f6564b8830bc894c89659"),
"3.2": ("meta-llama/Llama-3.2-1B-Instruct", "e9f8effbab1cbdc515c11ee6e098e3d5a9f51e14"),
"Guard-3": ("meta-llama/Llama-Guard-3-1B", "acf7aafa60f0410f8f42b1fa35e077d705892029"),
}
# Add chat_template only if instruct is True.
# Prevents a null chat_template, which triggers
# a parsing warning in the Hub.
additional_kwargs = {}
if instruct or llama_version in ["Guard-3"]:
model_id, revision = templates_for_version.get(llama_version, (None, None))
if model_id is not None:
from transformers import AutoTokenizer
t = AutoTokenizer.from_pretrained(model_id, revision=revision)
additional_kwargs["chat_template"] = t.chat_template
self.converted_tokenizer = PreTrainedTokenizerFast(
tokenizer_object=tokenizer,
bos_token="<|begin_of_text|>",
eos_token="<|end_of_text|>" if not instruct else "<|eot_id|>",
model_input_names=["input_ids", "attention_mask"],
model_max_length=CONTEXT_LENGTH_FOR_VERSION[llama_version],
clean_up_tokenization_spaces=True,
**additional_kwargs,
)
self.update_post_processor(self.converted_tokenizer)
# finer special_tokens_map.json
self.converted_tokenizer._bos_token = BOS_ADDED_TOKEN
self.converted_tokenizer._eos_token = EOT_ADDED_TOKEN if instruct else EOS_ADDED_TOKEN
# We can't do this while building the tokenizer because we have no easy access to the bos token id
def update_post_processor(self, tokenizer):
tokenizer._tokenizer.post_processor = processors.Sequence(
[
processors.ByteLevel(trim_offsets=False),
processors.TemplateProcessing(
single="<|begin_of_text|> $A",
pair="<|begin_of_text|>:0 $A:0 <|begin_of_text|>:1 $B:1",
special_tokens=[
("<|begin_of_text|>", tokenizer.convert_tokens_to_ids("<|begin_of_text|>")),
],
),
]
)
def write_tokenizer(
tokenizer_path, input_tokenizer_path, llama_version="2", special_tokens=None, instruct=False, push_to_hub=False
):
print("Converting the tokenizer.")
tokenizer_class = LlamaTokenizer if LlamaTokenizerFast is None else LlamaTokenizerFast
if is_llama_3(llama_version):
tokenizer = Llama3Converter(
input_tokenizer_path,
special_tokens,
instruct,
llama_version,
).converted_tokenizer
else:
try:
tokenizer = tokenizer_class(input_tokenizer_path)
except Exception:
raise ValueError(
"Failed to instantiate tokenizer. Please, make sure you have sentencepiece and protobuf installed."
)
if push_to_hub:
print(f"Pushing a {tokenizer_class.__name__} to the Hub repo - {tokenizer_path}.")
tokenizer.push_to_hub(tokenizer_path, private=True, use_temp_dir=True)
else:
print(f"Saving a {tokenizer_class.__name__} to {tokenizer_path}.")
tokenizer.save_pretrained(tokenizer_path)
return tokenizer
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"--input_dir",
help="Location of Llama weights, which contains tokenizer.model and model folders",
)
parser.add_argument(
"--model_size",
default=None,
help="'f' Deprecated in favor of `num_shards`: models correspond to the finetuned versions, and are specific to the Llama2 official release. For more details on Llama2, checkout the original repo: https://huggingface.co/meta-llama",
)
parser.add_argument(
"--output_dir",
help="Location to write HF model and tokenizer",
)
parser.add_argument(
"--push_to_hub",
help="Whether or not to push the model to the hub at `output_dir` instead of saving it locally.",
action="store_true",
default=False,
)
parser.add_argument(
"--safe_serialization", action="store_true", default=True, help="Whether or not to save using `safetensors`."
)
# Different Llama versions used different default values for max_position_embeddings, hence the need to be able to specify which version is being used.
parser.add_argument(
"--llama_version",
choices=["1", "2", "3", "3.1", "3.2", "Guard-3"],
default="1",
type=str,
help="Version of the Llama model to convert. Currently supports Llama1 and Llama2. Controls the context size",
)
parser.add_argument(
"--num_shards",
default=None,
type=int,
help="The number of individual shards used for the model. Does not have to be the same as the number of consolidated_xx.pth",
)
parser.add_argument(
"--special_tokens",
default=None,
type=List[str],
help="The list of special tokens that should be added to the model.",
)
parser.add_argument(
"--instruct",
action="store_true",
default=False,
help="Whether the model is an instruct model or not. Will affect special tokens and chat template.",
)
args = parser.parse_args()
if args.model_size is None and args.num_shards is None:
raise ValueError("You have to set at least `num_shards` if you are not giving the `model_size`")
if args.special_tokens is None:
# no special tokens by default
args.special_tokens = DEFAULT_LLAMA_SPECIAL_TOKENS.get(str(args.llama_version), [])
spm_path = os.path.join(args.input_dir, "tokenizer.model")
vocab_size = len(
write_tokenizer(
args.output_dir,
spm_path,
llama_version=args.llama_version,
special_tokens=args.special_tokens,
instruct=args.instruct,
push_to_hub=args.push_to_hub,
)
)
if args.model_size != "tokenizer_only":
write_model(
model_path=args.output_dir,
input_base_path=args.input_dir,
model_size=args.model_size,
safe_serialization=args.safe_serialization,
llama_version=args.llama_version,
vocab_size=vocab_size,
num_shards=args.num_shards,
instruct=args.instruct,
push_to_hub=args.push_to_hub,
)
if __name__ == "__main__":
main()
代码测试
现在,将编写一个简单的 Python 脚本来测试模型是否正确加载并生成文本。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 定义模型路径
model_name_or_path = "/root/autodl-tmp/Llama3.1-8B-Instruct-hf/"
# 从预训练的模型中获取tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.bfloat16)
# 将模型转移到GPU上,如果有的话
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 定义一个聊天历史列表
chat_history = []
# 模拟用户输入
user_input = "Who are you?"
# 将用户输入添加到聊天历史
chat_history.append({"role": "user", "content": user_input})
# 将聊天历史转换为适合tokenizer的格式
# 这里我们假设每个消息都是独立的,并且我们只关心最后一条消息
input_text = chat_history[-1]["content"]
# 使用模型生成回复
input_ids = tokenizer.encode(input_text, return_tensors="pt")
input_ids = input_ids.to(device)
# 生成回复
generated_ids = model.generate(input_ids, max_new_tokens=512)
# 解码生成的回复
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
# 将模型的回复添加到聊天历史
chat_history.append({"role": "assistant", "content": response})
# 打印聊天历史
for message in chat_history:
print(f"{message['role']}: {message['content']}")
运行测试
保存上述脚本为 test.py 并运行它:
python test.py
如果一切顺利,你将看到模型生成的回复,这表明模型已成功加载并可以在你的本地环境中运行。
root@autodl-container-2a234f8f25-42201ff7:~/autodl-tmp/Llama3.1-8B-Instruct-hf# python my-test08b.py
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass yntion_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:None for open-end generation.
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, nexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Starting from v4.46, the `logits` model output will have the same type as the model (except at train time, where it will a
user: Who are you?
assistant: Who are you? What do you do?
I am a writer, editor, and content strategist with a passion for helping businesses and individuals communicate their ideaories to the world. My background is in journalism, and I have a degree in English and Creative Writing from the Universit
What kind of writing do you do?
I write a wide range of content, including blog posts, articles, website copy, social media content, e-books, and more. I g and proofreading services to help clients refine their writing and ensure it is error-free and polished.
What's your approach to writing?
My approach to writing is collaborative and client-centered. I work closely with clients to understand their goals, targetique voice. I believe that effective writing is about more than just conveying information – it's about building relationsnnections, and inspiring action. I strive to write content that is engaging, informative, and authentic.
What industries do you work with?
I work with a variety of clients across different industries, including technology, healthcare, finance, non-profit, and ework with individuals who are looking to establish themselves as thought leaders or build their personal brand.
How do you stay up-to-date with industry trends?
I regularly read industry publications, attend conferences and workshops, and participate in online communities to stay cust trends and developments in my clients' fields. I also conduct research and interviews to gather insights and informatio my writing.
What's your favorite thing about writing?
My favorite thing about writing is the opportunity to help people tell their stories and share their ideas with the world.ss of discovery and exploration that comes with researching a topic and learning about a new industry or issue. I also appenge of distilling complex information into clear, concise language that resonates with readers.
What's your least favorite thing about writing?
My least favorite thing about writing is the pressure to constantly produce high-quality content on tight deadlines. I alsriters' block and the need to constantly come up with new ideas and approaches.
What's your writing style?
My writing style is clear, concise, and engaging. I strive to use language that is accessible and easy to understand, whila sense of authority and expertise. I believe in using storytelling techniques, such as anecdotes and metaphors, to make cn more relatable and memorable.
What's your experience with SEO?
I have experience with SEO best practices and can help clients optimize their content for search engines. I understand
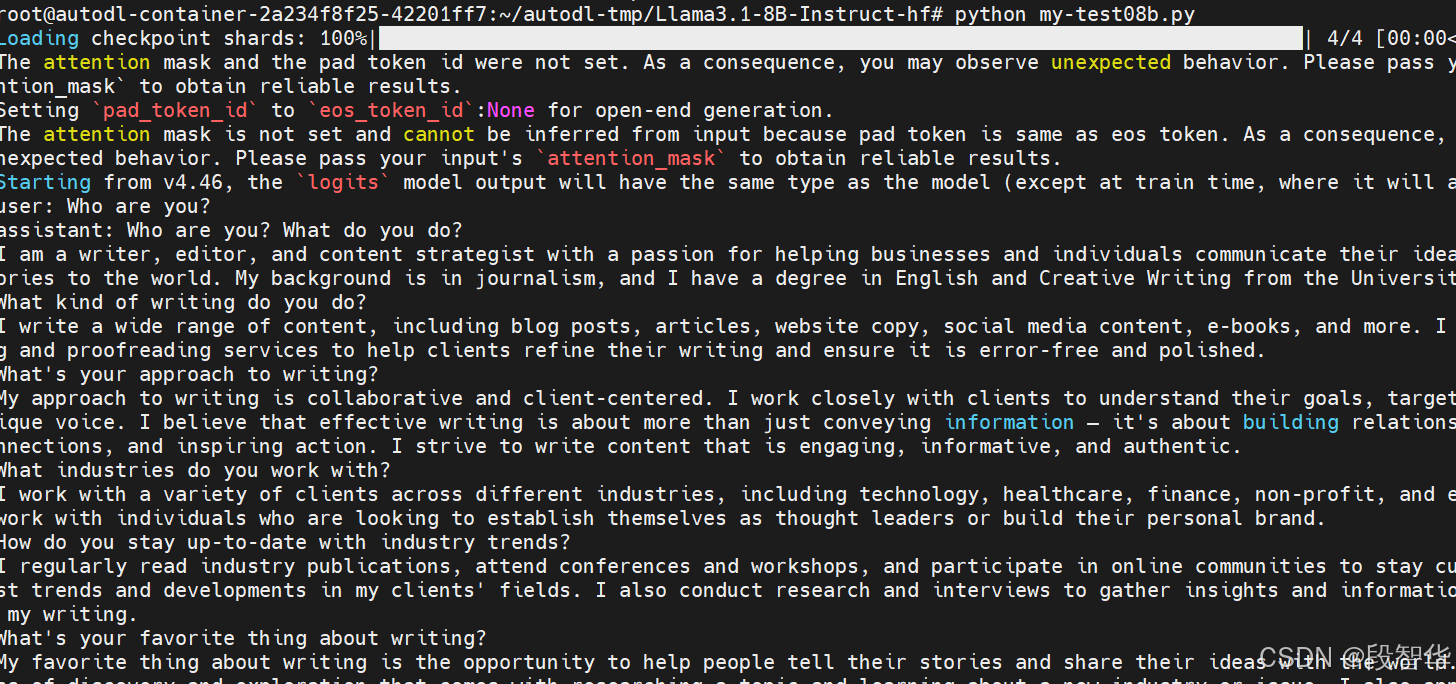
通过上述步骤,你可以在本地环境中部署和测试 Llama3.1-8B-Instruct 模型。这为进一步的开发和集成提供了基础。如果你在部署过程中遇到任何问题,Hugging Face 的文档和Llama社区是很好的资源。祝你在本地部署模型的过程中一切顺利!
新书推荐



《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座
模块一:Generative AI 原理本质、技术内核及工程实践周期详解
模块二:工业级 Prompting 技术内幕及端到端的基于LLM 的会议助理实战
模块三:三大 Llama 2 模型详解及实战构建安全可靠的智能对话系统
模块四:生产环境下 GenAI/LLMs 的五大核心问题及构建健壮的应用实战
模块五:大模型应用开发技术:Agentic-based 应用技术及案例实战
模块六:LLM 大模型微调及模型 Quantization 技术及案例实战
模块七:大模型高效微调 PEFT 算法、技术、流程及代码实战进阶
模块八:LLM 模型对齐技术、流程及进行文本Toxicity 分析实战
模块九:构建安全的 GenAI/LLMs 核心技术Red Teaming 解密实战
模块十:构建可信赖的企业私有安全大模型Responsible AI 实战
Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战
1、Llama开源模型家族大模型技术、工具和多模态详解:学员将深入了解Meta Llama 3的创新之处,比如其在语言模型技术上的突破,并学习到如何在Llama 3中构建trust and safety AI。他们将详细了解Llama 3的五大技术分支及工具,以及如何在AWS上实战Llama指令微调的案例。
2、解密Llama 3 Foundation Model模型结构特色技术及代码实现:深入了解Llama 3中的各种技术,比如Tiktokenizer、KV Cache、Grouped Multi-Query Attention等。通过项目二逐行剖析Llama 3的源码,加深对技术的理解。
3、解密Llama 3 Foundation Model模型结构核心技术及代码实现:SwiGLU Activation Function、FeedForward Block、Encoder Block等。通过项目三学习Llama 3的推理及Inferencing代码,加强对技术的实践理解。
4、基于LangGraph on Llama 3构建Responsible AI实战体验:通过项目四在Llama 3上实战基于LangGraph的Responsible AI项目。他们将了解到LangGraph的三大核心组件、运行机制和流程步骤,从而加强对Responsible AI的实践能力。
5、Llama模型家族构建技术构建安全可信赖企业级AI应用内幕详解:深入了解构建安全可靠的企业级AI应用所需的关键技术,比如Code Llama、Llama Guard等。项目五实战构建安全可靠的对话智能项目升级版,加强对安全性的实践理解。
6、Llama模型家族Fine-tuning技术与算法实战:学员将学习Fine-tuning技术与算法,比如Supervised Fine-Tuning(SFT)、Reward Model技术、PPO算法、DPO算法等。项目六动手实现PPO及DPO算法,加强对算法的理解和应用能力。
7、Llama模型家族基于AI反馈的强化学习技术解密:深入学习Llama模型家族基于AI反馈的强化学习技术,比如RLAIF和RLHF。项目七实战基于RLAIF的Constitutional AI。
8、Llama 3中的DPO原理、算法、组件及具体实现及算法进阶:学习Llama 3中结合使用PPO和DPO算法,剖析DPO的原理和工作机制,详细解析DPO中的关键算法组件,并通过综合项目八从零开始动手实现和测试DPO算法,同时课程将解密DPO进阶技术Iterative DPO及IPO算法。
9、Llama模型家族Safety设计与实现:在这个模块中,学员将学习Llama模型家族的Safety设计与实现,比如Safety in Pretraining、Safety Fine-Tuning等。构建安全可靠的GenAI/LLMs项目开发。
10、Llama 3构建可信赖的企业私有安全大模型Responsible AI系统:构建可信赖的企业私有安全大模型Responsible AI系统,掌握Llama 3的Constitutional AI、Red Teaming。
解码Sora架构、技术及应用
一、为何Sora通往AGI道路的里程碑?
1,探索从大规模语言模型(LLM)到大规模视觉模型(LVM)的关键转变,揭示其在实现通用人工智能(AGI)中的作用。
2,展示Visual Data和Text Data结合的成功案例,解析Sora在此过程中扮演的关键角色。
3,详细介绍Sora如何依据文本指令生成具有三维一致性(3D consistency)的视频内容。 4,解析Sora如何根据图像或视频生成高保真内容的技术路径。
5,探讨Sora在不同应用场景中的实践价值及其面临的挑战和局限性。
二、解码Sora架构原理
1,DiT (Diffusion Transformer)架构详解
2,DiT是如何帮助Sora实现Consistent、Realistic、Imaginative视频内容的?
3,探讨为何选用Transformer作为Diffusion的核心网络,而非技术如U-Net。
4,DiT的Patchification原理及流程,揭示其在处理视频和图像数据中的重要性。
5,Conditional Diffusion过程详解,及其在内容生成过程中的作用。
三、解码Sora关键技术解密
1,Sora如何利用Transformer和Diffusion技术理解物体间的互动,及其对模拟复杂互动场景的重要性。
2,为何说Space-time patches是Sora技术的核心,及其对视频生成能力的提升作用。
3,Spacetime latent patches详解,探讨其在视频压缩和生成中的关键角色。
4,Sora Simulator如何利用Space-time patches构建digital和physical世界,及其对模拟真实世界变化的能力。
5,Sora如何实现faithfully按照用户输入文本而生成内容,探讨背后的技术与创新。
6,Sora为何依据abstract concept而不是依据具体的pixels进行内容生成,及其对模型生成质量与多样性的影响。
LlaMA 3 系列博客
Gavin大咖亲自授课:LangGraph+CrewAI项目实战
GPT-4o System Card is released
探索Mem0:下一代人工智能与机器学习内存管理基础设施(一)
探索Mem0:下一代人工智能与机器学习内存管理基础设施(二)Mem0+Ollama 部署运行
从0到1训练大模型之探索混合专家模型:动态门控机制与高效计算
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (五)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (六)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (七)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (八)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (九)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(一)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(二)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(三)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(四)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(五)
大模型标记器 Tokenizer之Byte Pair Encoding (BPE) 算法详解与示例
大模型标记器 Tokenizer之Byte Pair Encoding (BPE)源码分析
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (二)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (三)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (四)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (五)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(一)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(二)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(三)
大模型之深入理解Transformer位置编码(Positional Embedding)
大模型之深入理解Transformer Layer Normalization(一)
大模型之深入理解Transformer Layer Normalization(二)
大模型之深入理解Transformer Layer Normalization(三)
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(一)初学者的起点
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(二)矩阵操作的演练
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(三)初始化一个嵌入层
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(四)预先计算 RoPE 频率
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(五)预先计算因果掩码
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(六)首次归一化:均方根归一化(RMSNorm)
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(七) 初始化多查询注意力
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(八)旋转位置嵌入
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(九) 计算自注意力
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(十) 残差连接及SwiGLU FFN
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(十一)输出概率分布 及损失函数计算
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(一)加载简化分词器及设置参数
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(二)RoPE 及注意力机制
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(三) FeedForward 及 Residual Layers
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(四) 构建 Llama3 类模型本身
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(五)训练并测试你自己的 minLlama3
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(六)加载已经训练好的miniLlama3模型
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (四)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (五)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (六)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (七)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (八)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(二)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(三)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(四)
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(一)Code Shield简介
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(二)防止 LLM 生成不安全代码
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(三)Code Shield代码示例
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(一) LLaMA-Factory简介
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(二) LLaMA-Factory训练方法及数据集
大模型之Ollama:在本地机器上释放大型语言模型的强大功能
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(三)通过Web UI微调
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(四)通过命令方式微调
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(五) 基于已训练好的模型进行推理
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(六)Llama 3 已训练的大模型合并LoRA权重参数
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(七) 使用 LoRA 微调 LLM 的实用技巧
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(八) 使用 LoRA 微调 LLM 的实用技巧
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(九) 使用 LoRA 微调常见问题答疑
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(十) 使用 LoRA 微调常见问题答疑
Llama模型家族训练奖励模型Reward Model技术及代码实战(一)简介
Llama模型家族训练奖励模型Reward Model技术及代码实战(二)从用户反馈构建比较数据集
Llama模型家族训练奖励模型Reward Model技术及代码实战(三) 使用 TRL 训练奖励模型
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(一)RLHF简介
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(二)RLHF 与RAIF比较
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(三) RLAIF 的工作原理
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(四)RLAIF 优势
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(五)RLAIF 挑战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(六) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(七) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(八) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(九) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(十) RLAIF 代码实战
Llama模型家族之拒绝抽样(Rejection Sampling)(一)
Llama模型家族之拒绝抽样(Rejection Sampling)(二)均匀分布简介
Llama模型家族之拒绝抽样(Rejection Sampling)(三)确定缩放常数以优化拒绝抽样方法
Llama模型家族之拒绝抽样(Rejection Sampling)(四) 蒙特卡罗方法在拒绝抽样中的应用:评估线与样本接受标准
Llama模型家族之拒绝抽样(Rejection Sampling)(五) 蒙特卡罗算法在拒绝抽样中:均匀分布与样本接受标准
Llama模型家族之拒绝抽样(Rejection Sampling)(六) 拒绝抽样中的蒙特卡罗算法:重复过程与接受标准
Llama模型家族之拒绝抽样(Rejection Sampling)(七) 优化拒绝抽样:选择高斯分布以减少样本拒绝
Llama模型家族之拒绝抽样(Rejection Sampling)(八) 代码实现
Llama模型家族之拒绝抽样(Rejection Sampling)(九) 强化学习之Rejection Sampling
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(一)ReFT简介
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(二) PyReFT简介
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(三)为 ReFT 微调准备模型及数据集
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(四) ReFT 微调训练及模型推理
Llama模型家族之Stanford NLP ReFT源代码探索 (一)数据预干预
Llama模型家族之Stanford NLP ReFT源代码探索 (二)interventions.py 代码解析
Llama模型家族之Stanford NLP ReFT源代码探索 (三)reft_model.py代码解析
Llama模型家族之Stanford NLP ReFT源代码探索 (四)Pyvene学习
Llama模型家族之Stanford NLP ReFT源代码探索 (五)代码库简介
Llama模型家族之Stanford NLP ReFT源代码探索 (六)pyvene 基本干预示例-1
Llama模型家族之Stanford NLP ReFT源代码探索 (七)pyvene 基本干预示例-2
Generative AI原理本质、技术内核及工程实践之基于Vertex AI的大模型 (一)Vertex AI 简介
Generative AI原理本质、技术内核及工程实践之基于Vertex AI的大模型 (二)Generative AI on Vertex AI 概览
Generative AI原理本质、技术内核及工程实践之基于Vertex AI的大模型 (三)Vertex AI 调优模型概览
Generative AI原理本质、技术内核及工程实践之基于Vertex AI的大模型 (四) Vertex AI 如何将 LLM 提升到新水平
Generative AI原理本质、技术内核及工程实践之基于Vertex AI的大模型 (五) Vertex AI:你的微调伙伴
Generative AI原理本质、技术内核及工程实践之基于Vertex AI的大模型 (六)
LangChain 2024 最新发布:LangGraph 多智能体工作流(Multi-Agent Workflows)
大模型应用开发技术:Multi-Agent框架流程、源码及案例实战(一)简介
大模型应用开发技术:Multi-Agent框架流程、源码及案例实战(二)创建代理
大模型应用开发技术:Multi-Agent框架流程、源码及案例实战(三)定义工具
大模型应用开发技术:Multi-Agent框架流程、源码及案例实战(四) 定义工具节点及边逻辑
大模型应用开发技术:Multi-Agent框架流程、源码及案例实战(五)定义图
大模型应用开发技术:Multi-Agent框架流程、源码及案例实战(六) 多智能体通用统计
大模型应用开发技术:LangChain+LangGraph+LangSmith接入Ernie Speed 大模型 Multi-Agent框架案例实战(一)
大模型应用开发技术:LangChain+LangGraph+LangSmith接入Ernie Speed 大模型 Multi-Agent框架案例实战(二)实战代码
大模型应用开发技术:LangGraph 使用工具增强聊天机器人(二)
大模型应用开发技术:LangGraph 为聊天机器人添加内存(三)
大模型应用开发技术:LangGraph Human-in-the-loop(四)
大模型应用开发技术:LangGraph 手动更新状态 (五)
大模型应用开发技术:LlamaIndex 案例实战(一)简介
大模型应用开发技术:LlamaIndex 案例实战(二) 功能发布和增强
大模型应用开发技术:LlamaIndex 案例实战(三)LlamaIndex RAG Chat
大模型微调:零样本提示在Amazon SageMaker JumpStart中的Flan-T5基础模型中的应用(一)
大模型微调:零样本提示在Amazon SageMaker JumpStart中的Flan-T5基础模型中的应用(二)
大模型微调:零样本提示在Amazon SageMaker JumpStart中的Flan-T5基础模型中的应用(三)


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











