






从直觉的角度透彻理解层次聚类
本节讲解聚类中另外一个非常重要的内容层次聚类(Hierarchical Clustering),前面我们讲解了K-均值聚类算法,只要做机器学习算法,并涉及非监督学习的情况下,多少有点了解K-均值聚类算法,前面我们讲解了K-均值聚类算法的内幕信息及使用的注意点,怎么选择K-均值聚类算法的分组个数,以及在分组内部怎么选择初始点,这些都是要注意的,并通过代码展示了K-均值聚类算法的使用。大型商场如沃尔玛、麦德龙商场,寻求重点的目标客户和潜在的目标客户,营销的目标客户是工资收入不错,又很舍得花钱的客户,是商场收入的主要来源;第二种情况是潜在的客户,收入很高,但花钱花的不多,是商场以后增长的核心动力。对大家有非常大的学习意义和借鉴意义。
大家在自己家学习或者工作的过程中是否使用过层次聚类,对层次聚类的认识是什么?层次聚类是一种分组聚类的算法,功能和K-均值聚类是类似的。大家以前可能很少接触过层次聚类算法,对于层次聚类内部的工作机制,大家如果是第一次接触,需要一点时间消化;从美国硅谷的经历来看,层次聚类在非监督学习中是很重要的,其他很多算法基于这个算法衍生出来。层次聚类在非监督学习中运用非常广泛。
本节讲解5个部分的内容:1.层次聚类的作用及类别。2. 凝聚层次聚类(Agglomerative Hierarchical Clustering)运行的4个步骤。3.树状图(Dendrogram)的工作机制解密。4. 层次聚类在内部是如何使用树状图进行聚类。5.寻求最优的分组个数。
层次聚类的作用是什么?层次聚类用于非监督学习中的聚类。
如图所示,左侧图是一堆数据,不知道里面有什么规律;按照层次聚类的算法找出规律,这个算法基本不需要你干预,跟前面的分类及回归有一个核心的区别,分类及回归有一个前提,每次训练的时候,要对实际值去评估一下预测值的误差,然后进行调整。聚类这没有什么标准,当然最终能够完成聚类,聚类的过程也是有标准的,采用一个适合的算法,在所有的非监督学习算法中,数学主要用到高中空间几何的内容,算法已经在内部封装完成了,不需要任何的干预。从结果上看,达到和K-均值聚类差不多的效果。
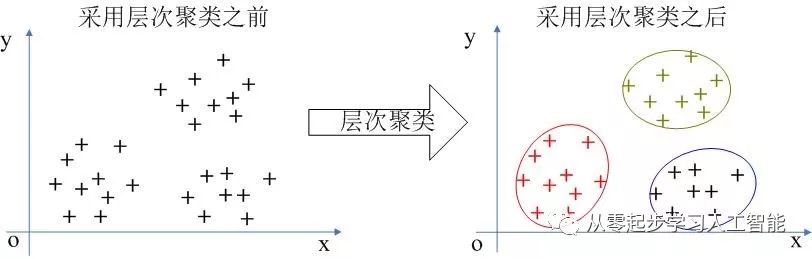
层次聚类
实质上,层次聚类有两种,一种是凝聚(Agglomerative)聚类,另一种是分裂(Divisive)聚类,本节只讲解凝聚聚类,分裂聚类可以自学,因为它只是不同的实现。面向接口的编程,接口是一致的,实现可以不同。如果告诉了你接口及其中一种实现,则另外一种实现不应该是很大的问题。
凝聚层次聚类具体的工作过程如下,这个过程非常清晰,因为有前面K-均值聚类背景的铺垫,层次聚类是另外一个非监督学习,非常容易理解。
(1) 数据集中有很多数据,每一个数据都把它变成一个分组,整个数据集可能有100万条数据,那构成100万个分组,这是凝聚层次聚类的第一步。
(2) 寻找两个最近的数据,把这两个最近的数据放在一起,这就是引力原则。物以类聚, 寻找两个最近的数据,把这两个最近的数据放在一起,这就是引力原则。物以类聚,大家在一块更容易成为一组。例如,如果在美国硅谷,在硅谷和一群人、或者若干群人形成了一个分组后若干分组;如果在上海张江,搞芯片或者互联网企业,通过兴趣、距离聚集起来,也会形成一个分组;原来是N条数据,现在就变成了N-1条数据了。因为两个最近的点构成了一个分组,那什么是最近?这里从几何空间的欧几里得距离来计算的,计算公式为坐标差的平方和的开方,这个公式我们在前面的章节讲解过,如图33-6所示。这样就找到两个最近的点,然后把这两个点分成一组,变成了N-1个分组。(3) 按照这个思路继续下去,把最近的两个分组合成一个分组,这样就变成N-2个分组了。
(4) 一直循环第三个步骤,最后的结果是从N个分组变成了1个分组。同学们可能很好奇,这不是聚类分组吗,为什么分成了一组?开始是N组,结果分成了1组。这涉及到一个问题,凝聚层次聚类算法在完成了这个步骤,将这些数据分成了一个很大很大的组,这个组涵盖了所有的数据,它会有下一步的动作。
如图所示,假设有2个组,计算两个组的之间的距离有几种方式:
第一种方式,找这两个组中距离最近的两个点。
第二种方式,找这两个组中距离最远的两个点。
第三种方式,计算两个组的所有点之间距离的平均值。
第四种方式,两个组的质心之间的距离。
其实这个不要怎么关心,知道怎么算两个分组之间的距离就行了,初步有这四种方式,实际不止这4种。
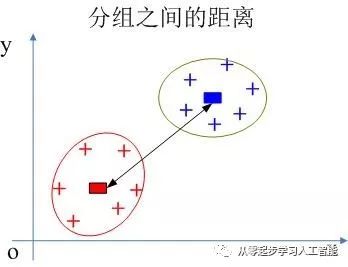
两个组之间的距离

本文根据王家林老师《30个真实商业案例代码中成为AI实战专家(10大机器学习案例、13大深度学习案例、7大增强学习案例)课程》整理。















 8826
8826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











