







ES 如何才能让数据更快的被检索使用。一句话概括了 Lucene 的设计思路就是"开新文件"。从另一个方面看,开新文件也会给服务器带来负载压力。因为默认每 1 秒,都会有一个新文件产生,每个文件都需要有文件句柄,内存,CPU 使用等各种资源。一天有 86400 秒,设想一下,每次请求要扫描一遍 86400 个文件,这个响应性能绝对好不了!
为了解决这个问题,ES 会不断在后台运行任务,主动将这些零散的 segment 做数据归并,尽量让索引内只保有少量的,每个都比较大的,segment 文件。这个过程是有独立的线程来进行的,并不影响新 segment 的产生。
归并过程中,索引状态如图 2-7,尚未完成的较大的 segment 是被排除在检索可见范围之外的:
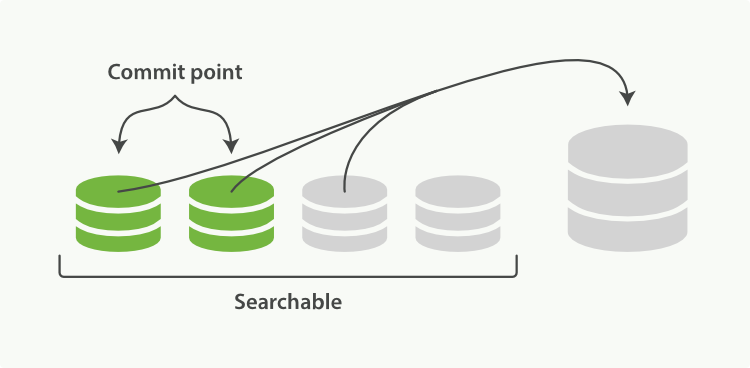
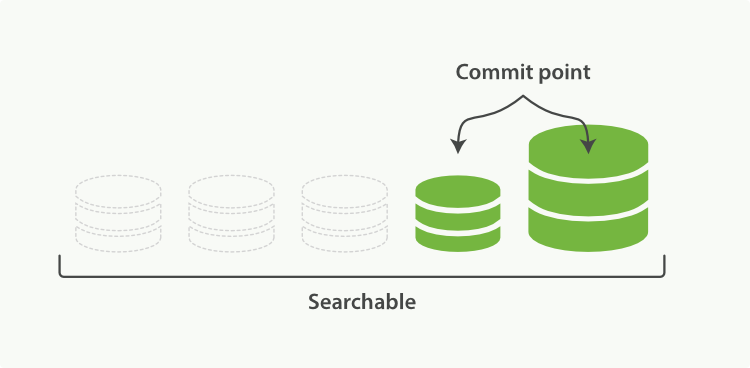
当归并完成,较大的这个 segment 刷到磁盘后,commit 文件做出相应变更,删除之前几个小 segment,改成新的大 segment。等检索请求都从小 segment 转到大 segment 上以后,删除没用的小 segment。这时候,索引里 segment 数量就下降了,状态如图 2-8 所示:
归并策略
分层合并策略
这是ElasticSearch默认使用的合并策略。该策略将大小相似的段放在一起合并,当然段的数量会限制在每层允许的最大数量之中。依据每层允许的段数量的最大值,可以区分出一次合并中段的数量。在索引过程中,该合并策略将会计算索引中允许存在多少个段,这个值称为预算。如果索引中段的数量大于预算值,分层合并策略会首先按照段的大小(删除文档也会考虑在内)降序排序。随后会找出开销最小的合并方案,合并的开销计算会优先考虑比较小的段以及删除文档较多的段。 如果合并产生的段比index.merge.policy.max_merged_segment属性值更大,该合并策略将减少合并段的数量,以保持新段的大小在预算之下。这意味着,如果index.merge.policy.max_merged_segment属性值比较低,那么索引中段的数量就会比较多,查询的性能也就会比较低。用户应该根据应该程序的数量量,来监测并调整合并策略来满足业务需求。
字节大小对数合并策略
这合并策略将创建由多个大小处于对数运算后大小在指定范围索引组成的索引。索引中存在数量较少的大段,同时也会有数量低于合并因子数(默认是10)的小段。读者可以想象较少的段处于同一个数量级,段的数量低于合并因子。当一个新段产生并且其大小与其它段不在一个数量级时,所有处于该数量级的段就会合并。索引中段的数量与经对数运算后新段字节大小成比例。该合并策略通常能够在使段合并开销最少的情况下将索引中段的数量保持在一个比较低的水平。
文档数量对数合并策略
该合并策略与log_byte_size合并策略类似,只是将以段的字节大小来计算的方式换成了文档数量。该合并策略适用于索引中文档大小差别不大或者用户希望每个段中文档的数量相近的场景。
归并策略配置
在tiered合并策略中,用户可以更改如下的配置项:
index.merge.policy.expunge_default_allowed:默认值为10,该参数指定了段中删除文档的比例。当执行expungeDeletes方法(已经废弃)时,删除文档超过设定比例的段将被合并。
index.merge.policy.floor_segment:该属性用于阻止碎片段的频繁刷新。小于或者等于该设定值的段将考虑被合并。默认值为2M。
index.merge.policy.max_merge_at_once:该属性指定了索引过程中同一时刻用于合并的段的最大数量,默认为10。如果将值设置得更大,一次合并操作将合并更多的段,同时合并过程也需要更多的I/O资源。
index.merge.policy.max_merge_at_once_explicit:该属性指定了在对索引进行optimize操作或者expungeDelete操作时一次合并的段的最大数量。默认值为30。该值不影响索引过程段的合并操作中段的最大数量。
index.merge.policy.max_merged_segment:默认值为5GB,该属性指定了索引过程中单个段的最大容量。这个值是一个近似值,因为合并操作中,段的大小等于待合并段的总大小减去各个段中删除文档的大小。
index.merge.policy.segments_per_tier:该属性指定了每层段的数量。较小的值带来较少的段。这意味着更多的合并操作,和更低索引性能。默认值为10,其值应该不低于index.merge.policy.max_merge_at_once属性值,否则就会使合并次数过多,引起性能问题。
index.reclaim_deletes_weight:默认值为2.0,该属性指定了删除文档在合并操作中的重要程度。如果属性值设置为0,删除文档对合并段的选择没有影响。其值越高,表示删除文档在对待合并段的选择影响越大。(译者注:光从字面上无法理解其属性,看TieredMergePolicy源码中reclaimDeletesWeight成员变量更容易理解)
index.compound_format:0~1 如果合并的段是小于总索引的此百分比,然后将其写在复合格式,否则它被写入以非复合格式, 默认值0.1。该属性可用于系统出现文件句柄数量太多错误时使用,但是会降低搜索和索引的性能。
index.merge.async:该属性值为Boolean类型,指定合并操作是否异步进行,默认值为true。
index.merge.async_interval:当index.merge.asnyc值为true时(合并会异步进行),该属性指定了两次合并操作的间隔。默认值为1s。请注意该属性值要尽量设置得低一点,以便于尽快实施合并操作,减少索引中段的数量。
log_byte_size合并策略中,用户可以更改如下的配置项:
merge_factor:指定了索引过程中段合并的频繁程度。merge_factor值越小,搜索就越快,内存使用也越小,但是会使索引的速度变慢。相反,其值越大,索引的速度就是越快(因为更少的合并操作),但是搜索就会变慢,内存使用就会增多。建议在批量索引中使用较大的值,在普通索引操作中使用较小的值。
min_merge_size:该属性定义了合并段的最小容量(整个段文件的字节数总和)。如果段的容量低于指定值,但是满足merge_factor的要求,该段就会被合并。默认值为1.6MB,且该属性对减少碎片段很有用。但是,如果属性值设置过高,会增加合并的开销。
max_merge_size:该属性定义了合并段的最大容量(整个段文件的字节数总和)。默认情况下没有设置值。因此对段的最大容量没有限制。
maxMergeDocs:该属性定义了合并段的最大文档数。默认情况下没有设置值。因此对段的最大文档数没有限制。
calibrate_size_by_deletes:该属性值为Boolean类型,默认值为true,指定了标记删除文档的容量在计算段容量时应该予以考虑。
index.compund_format:该属性值为Boolean类型,指定索引是否应该存储为压缩格式。默认情况下为false。其用法请参考tiered合并策略对此属性的解释。
在log_doc合并策略中,用户可以更改如下的配置项
merge_factor:与log_byte_size合并策略中的属性一样,请考虑该合并策略中对属性的解释。
min_merge_docs:该属性定义了最小段的最小文档数。如果段的文档数低于该值,但是满足merge_factor属性条件,则段会被合并。属性的默认值为1000,且该属性对减少碎片段很有用。但是,如果属性值设置过高,会增加合并的开销。
max_merge_docs:该属性定义了待合并段的最大文档数。默认情况下没有设置,因此对一个段中允许拥有的最大文档数量没有限制。
calibrate_size_by_deletes:该属性值为Boolean类型,默认值为true,指定了标记删除文档的容量在计算段容量时应该予以考虑。
index.compund_format:该属性值为Boolean类型,指定索引是否应该存储为压缩格式。默认情况下为false。其用法请参考tiered合并策略对此属性的解释。
与前面的合并策略类似,上面提到的属性,都应该加上index.merge.policy前缀。因此,如果我们想设置min_merge_docs属性值,就应该使用index.merge.policy.min_merge_docs属性。 此外,log_doc合并策略支持index.merge.async属性和index.merge.async_interval,用法与tiered合并策略一样。
合并的限速配置
segment 归并的过程,需要先读取 segment,归并计算,再写一遍 segment,最后还要保证刷到磁盘。可以说,这是一个非常消耗磁盘 IO 和 CPU 的任务。所以,ES 提供了一些限速机制,确保这个任务不会过分影响到其他任务。
通过内存控制频率
indices.memory.index_buffer_size : 5%
index.cache.field.max_size: 50000 每个segment中可包含的最大的doc数目
控制合并io速率
Indices.store.throttle.type : merge 调节只在merge阶段有效 none 关闭调节 all 全阶段打开调节
Index.store.throttl.max_bytes_per_sec: 100mb 限制Io操作为每秒100mb
在 5.0 之前,默认值是 20MB。5.0 开始,ES 对此作了大幅度改进,使用了 Lucene 的 CMS(ConcurrentMergeScheduler) 的 auto throttle 机制,不再需要手动配置了。官方文档中都已经删除了相关介绍,不过从源码中还是可以看到,这个值目前的默认设置是 10240 MB。
对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器来说,这个限速是明显过低的。社区广泛的建议是可以适当调大到 100MB或者更高。
归并线程的控制
index.merge.scheduler.max_thread_count 归并线程的数目,ES 也是有所控制的。默认是: Math.min(3, Runtime.getRuntime().availableProcessors() / 2)。即服务器 CPU 核数的一半大于 3 时,启动 3 个归并线程;否则启动跟 CPU 核数的一半相等的线程数。如果你确定自己磁盘性能跟不上,可以降低,免得 IO 情况更加恶化。
强制合并 forcemerge 接口
既然默认的最大 segment 大小是 5GB。那么一个比较庞大的数据索引,就必然会有为数不少的 segment 永远存在,这对文件句柄,内存等资源都是极大的浪费。但是由于归并任务太消耗资源,所以一般不太选择加大
index.merge.policy.max_merged_segment
配置,而是在负载较低的时间段,通过 forcemerge 接口,强制归并 segment。
# curl -XPOST http://127.0.0.1:9200/logstash-2015-06.10/_forcemerge?max_num_segments=1
由于 forcemerge 线程对资源的消耗比普通的归并线程大得多,所以,绝对不建议对还在写入数据的热索引执行这个操作。这个问题对于 Elastic Stack 来说非常好办,一般索引都是按天分割的。
在2.0之前是
optimize
接口。
参考文章:
https://kibana.logstash.es/content/elasticsearch/principle/indexing-performance.html















 1127
1127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









