







1. 熵
1.1 信息熵
表示随机变量的不确定性,熵越大不确定性越大。在决策树算法中,熵是一个非常非常重要的概念。一件事发生的概率越小,我们说它所蕴含的信息量越大。比如:我们听女人能怀孕不奇怪,如果某天听到哪个男人怀孕了,那这个信息量就很大了…。
所以我们这样衡量信息量:
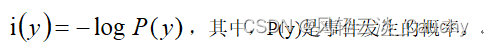
信息熵就是所有可能发生的事件的信息量的期望:
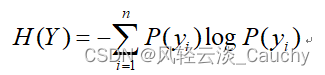
1.2 条件熵
已知随机变量 X的条件下随机变量 Y的不确定性
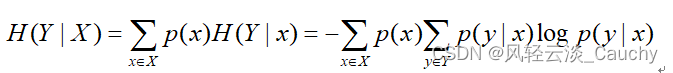
1.3 相对熵
相对熵也称为KL散度(Kullback-Leibler divergence),表示同一个随机变量的两个不同分布间的距离。
设 p(x),q(x) 分别是 离散随机变量X的两个概率分布,则p对q的相对熵是:
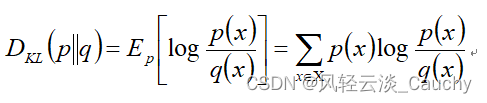
总的来说,相对熵是用来衡量同一个随机变量的两个不同分布之间的距离。在实际应用中,假如p(x)是目标真实的分布,而q(x)是预测得来的分布,为了让这两个分布尽可能的相同的,就需要最小化KL散度。
1.4 交叉熵
设 p(x),q(x) 分别是 离散随机变量X的两个概率分布,其中p(x)是目标分布,p和q的交叉熵可以看做是,使用分布q(x) 表示目标分布p(x)的困难程度:
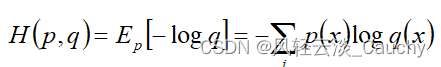
特别的,在逻辑回归中,p:真实样本分布,服从参数为p的0-1分布,即X∼B(1,p);q:待估计的模型,服从参数为q的0-1分布,即X∼B(1,q)。则
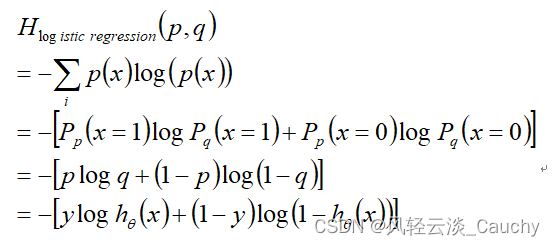
对所有样本取均值,得:
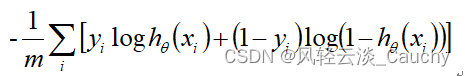
1.5 信息增益
当我们用另一个变量X对原变量Y分类后,原变量Y的不确定性就会减小了(即熵值减小)。而熵就是不确定性,不确定程度减少了多少其实就是信息增益。这就是信息增益的由来,所以信息增益定义如下:
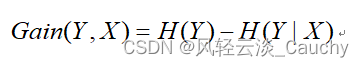
2. Softmax函数
归一化指数函数,或Softmax函数,实际上是有限项离散概率分布的梯度对数归一化。因此,Softmax函数在包括 多项逻辑回归,多项线性判别分析,朴素贝叶斯分类器和人工神经网络等的多种基于概率的多分类问题方法中都有着广泛应用。特别地,在多项逻辑回归和线性判别分析中,函数的输入是从K个不同的线性函数得到的结果,而样本向量 x 属于第 j 个分类的概率为:
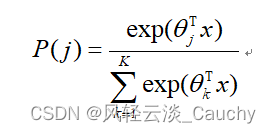
通过softmax函数,可以使得P(j)的范围在[0,1]之间。在回归和分类的问题中,通常θ是待求参数,通过寻找使得P(j)最大的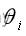
作为最佳参数。
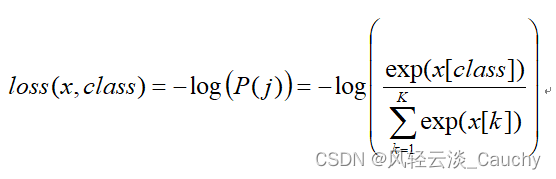















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









