







版权声明:转载请注明作者(独孤尚良dugushangliang)出处:https://blog.csdn.net/dugushangliang/article/details/117290636
先构建一个pandas的dataframe,代码如下:
import pandas as pd
d = {'one' : pd.Series([1., 2., 3.], index=['a', 'b', 'c']), 'two' : pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
my_df = pd.DataFrame(d)my_df是一个二维的结构,如下图所示:

stack函数会把列索引转成行索引,即把列索引换成二级的行索引,即所有列压缩到一列。请注意,这个的空值会跳过,下图中的数据结构只有7个元素,7行1列。
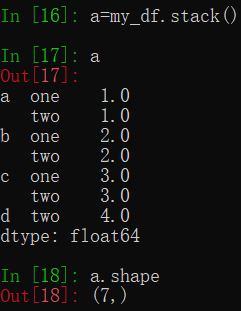
a['b','two']
a['d','two']
#上面两个索引是可以的,下面的是会报错KeyError
a['d','one']unstack函数会把行索引转成列索引,即把行索引换成二级的列索引,即所有行压缩到一行。注:实际上,Python似乎不分行向量或列向量,如果对一个Series对象进行转置,则还是其本身。根据shape函数的返回可知,这是一个8行1列的数据结构。
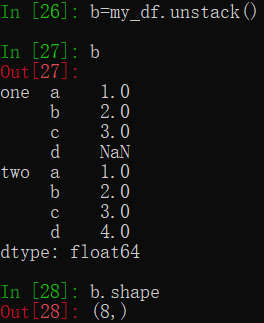
stack函数会把二级的行索引转成列索引,恢复其二维结构。

我们看到,用过stack函数后可以用unstack函数来恢复其原貌。反过来如何呢?

会报错:AttributeError: 'Series' object has no attribute 'stack'
我们发现,stack和unstack两个函数的组合,如下所示,只有前两个是可以的没有问题的。这是因为一个二维数据经过stack或unstack后,变成了一个Series结构,而Series有unstack没有stack。
my_df.stack().unstack()
my_df.unstack().unstack()
#my_df.stack().stack()
#my_df.unstack().stack()a=my_df.stack()
print(type(a))
print(dir(a))如下图所示,用过了unstack后,怎么恢复原状呢?转置一下即可。

独孤尚良dugushangliang——著















 7145
7145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









