







PaddleOCR安装参考官网或者Gitee说明文档:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/quickstart.md
可以先安装CPU版本跑起来:
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install "paddleocr>=2.0.1"
paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu false先跑CPU版本的目的是验证Python环境是否OK。
然后开始折腾GPU版本,经过验证非docker方式只需要安装CUDA和cuDNN便可以:
通过NVIDIA官网下载CUDA驱动:
https://developer.nvidia.com/cuda-12-0-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=deb_local
正常应该下载run文件安装,Ubuntu下可能由于测试机配置不足,在解压run文件过程中进程就被操作系统kill掉了,最后改用deb方式安上:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.0.0/local_installers/cuda-repo-ubuntu2204-12-0-local_12.0.0-525.60.13-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204-12-0-local_12.0.0-525.60.13-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2204-12-0-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda虽然指定安装12.0版本,但是sudo apt-get -y install cuda命令最终还是安装了最新版本12.2
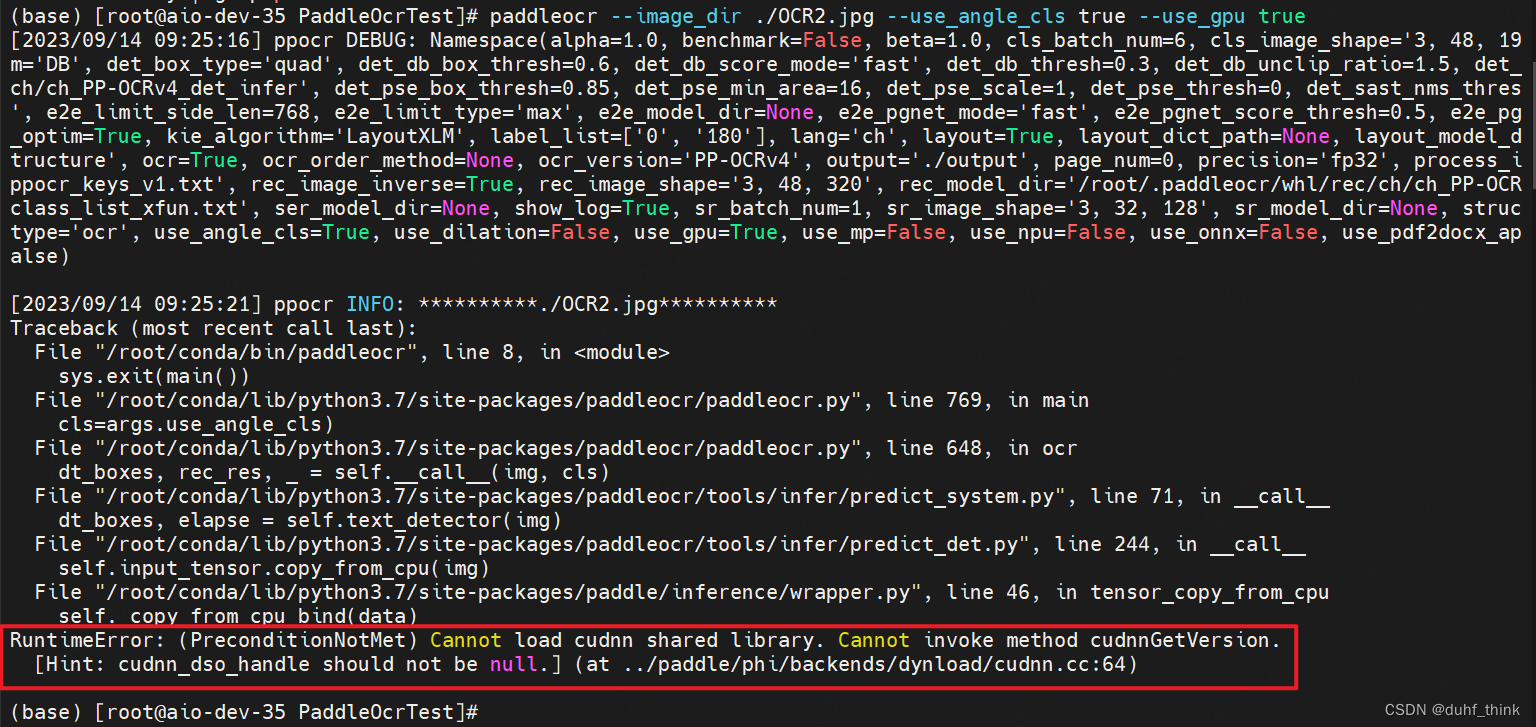
安装cudnn,从官网(https://developer.nvidia.com/rdp/cudnn-download)下载安装包,如果是Ubuntu可以下载deb包直接安装,如果是CentOS则需要下载tar包自行解压,cudnn就是一堆头文件和链接库。CentOS下需要将解压文件复制到/usr/local/cuda下,否则会提示初始错误:
tar -xvf cudnn-linux-x86_64-8.9.5.29_cuda12-archive.tar.xz
cd cudnn-linux-x86_64-8.9.5.29_cuda12-archive
cp include/cudnn*.h /usr/local/cuda/include/
cp -R lib/* /usr/local/cuda/lib64/安装完毕后GPU方式运行PaddleOCR可能提示一些库找不到,一般是动态链接库文件存在,但是未加入到LD_LIBRARY_PATH所导致:
paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu true此时主要借助locate命令寻找系统上是否有这些库,如果locate命令没有,Ubuntu下apt install plocate,CentOS下yum install mlocate,CentOS需要额外执行updatedb命令更新数据locate数据库,时间挺长。
例如我的Ubuntu环境中提示libcudnn.so.8和libcublas.so.12.2.5.6两个文件报错:
locate libcudnn.so.8
locate libcublas.so.12.2.5.6找到提示报错的so文件后,后将文件软链到/usr/lib下(CentOS对应是/usr/lib64),并所在路径注册到LD_LIBRARY_PATH变量中(需要写在/etc/profile中,然后source一下)
【Ubuntu】
cd /usr/lib
sudo ln -s /home/duhf/.local/lib/python3.10/site-packages/nvidia/cudnn/lib/libcudnn.so.8 libcudnn.so
export LD_LIBRARY_PATH=/home/duhf/.local/lib/python3.10/site-packages/nvidia/cudnn/lib/:$LD_LIBRARY_PATH
【CentOS】
cd /usr/lib
sudo ln -s /usr/local/cuda-12.2/targets/x86_64-linux/lib/libcublas.so.12.2.5.6 libcublas.so
export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64/:$LD_LIBRARY_PATH如果是其他内容报错则Google/Baidu解决,例如缺少openssl-1.1.1可以如下解决:
wget https://www.openssl.org/source/openssl-1.1.1o.tar.gz
cd openssl-1.1.1o
./config
make
make test
sudo make install
find / -name libssl.so.1.1
ln -s /usr/local/lib64/libssl.so.1.1 /usr/lib64/libssl.so.1.1
ln -s /usr/local/lib64/libssl.so.1.1 /usr/lib/libssl.so.1.1
find / -name libcrypto.so.1.1
ln -s /home/ubuntu/openssl-1.1.1o/libcrypto.so.1.1 /usr/lib64/libcrypto.so.1.1
ln -s /home/ubuntu/openssl-1.1.1o/libcrypto.so.1.1 /usr/lib/libcrypto.so.1.1
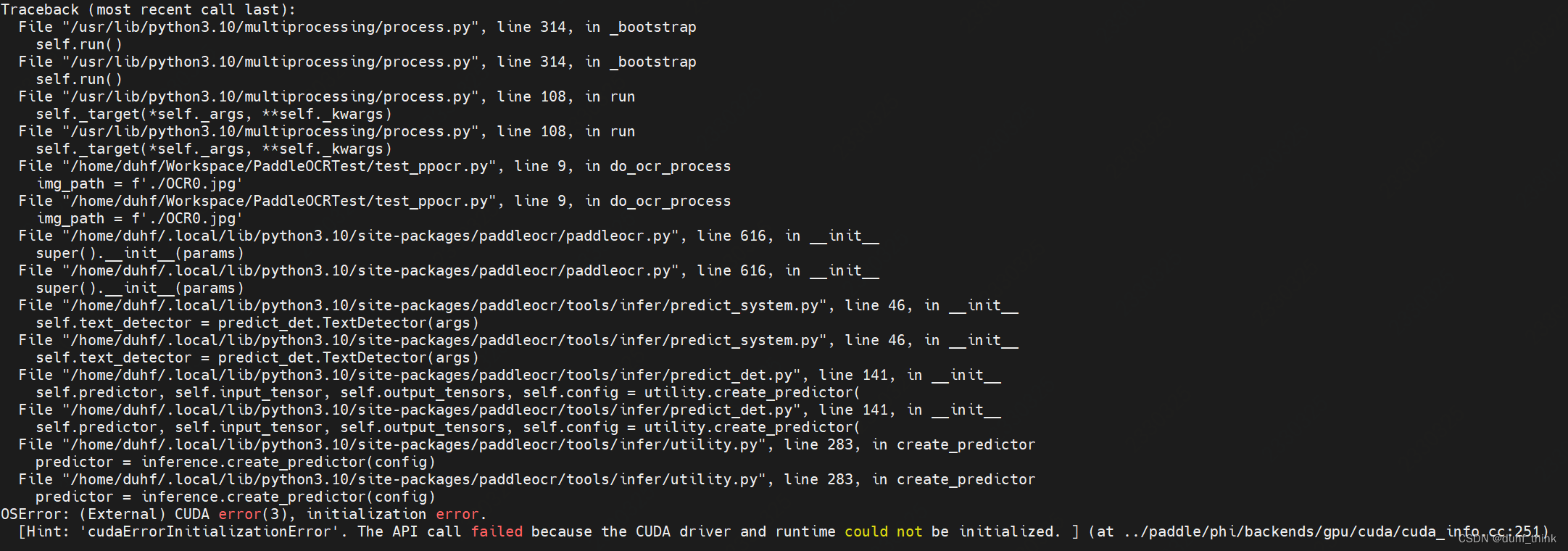
如果通过代码调用,发现async和threading均无法实现并发效果,最后只能借助multiprocessing以多进程方式实现并发。但是需要注意的是将所有与paddle相关的模块都放到 multiprocessing 里 import ,否则会导致初始化失败(这一坑真是坑爹啊):
【错误代码】
from paddleocr import PaddleOCR, draw_ocr
import time
from multiprocessing import Process
from PIL import Image # 显示结果,如果本地没有simfang.ttf,可以在doc/fonts目录下下载
def do_ocr_process(i:int):
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
print(f"\n---------------------------------- {i} ----------------------------------\n")
img_path = f'./OCR0.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/home/duhf/Downloads/ppocr_img/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save(f'result{i}.jpg')
time.sleep(1)
【正确代码】
import time
from multiprocessing import Process
def do_ocr_process(i:int):
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image # 显示结果,如果本地没有simfang.ttf,可以在doc/fonts目录下下载
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
print(f"\n---------------------------------- {i} ----------------------------------\n")
img_path = f'./OCR0.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/home/duhf/Downloads/ppocr_img/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save(f'./result{i}.jpg')
time.sleep(1)
def multi_process():
print("============================================")
process_list = []
for i in range(5):
p = Process(target=do_ocr_process,args=(i,))
p.start()
process_list.append(p)
for p in process_list:
p.join()
st = time.time()
multi_process()
ed = time.time()
print(f">>>>> use time {ed-st}")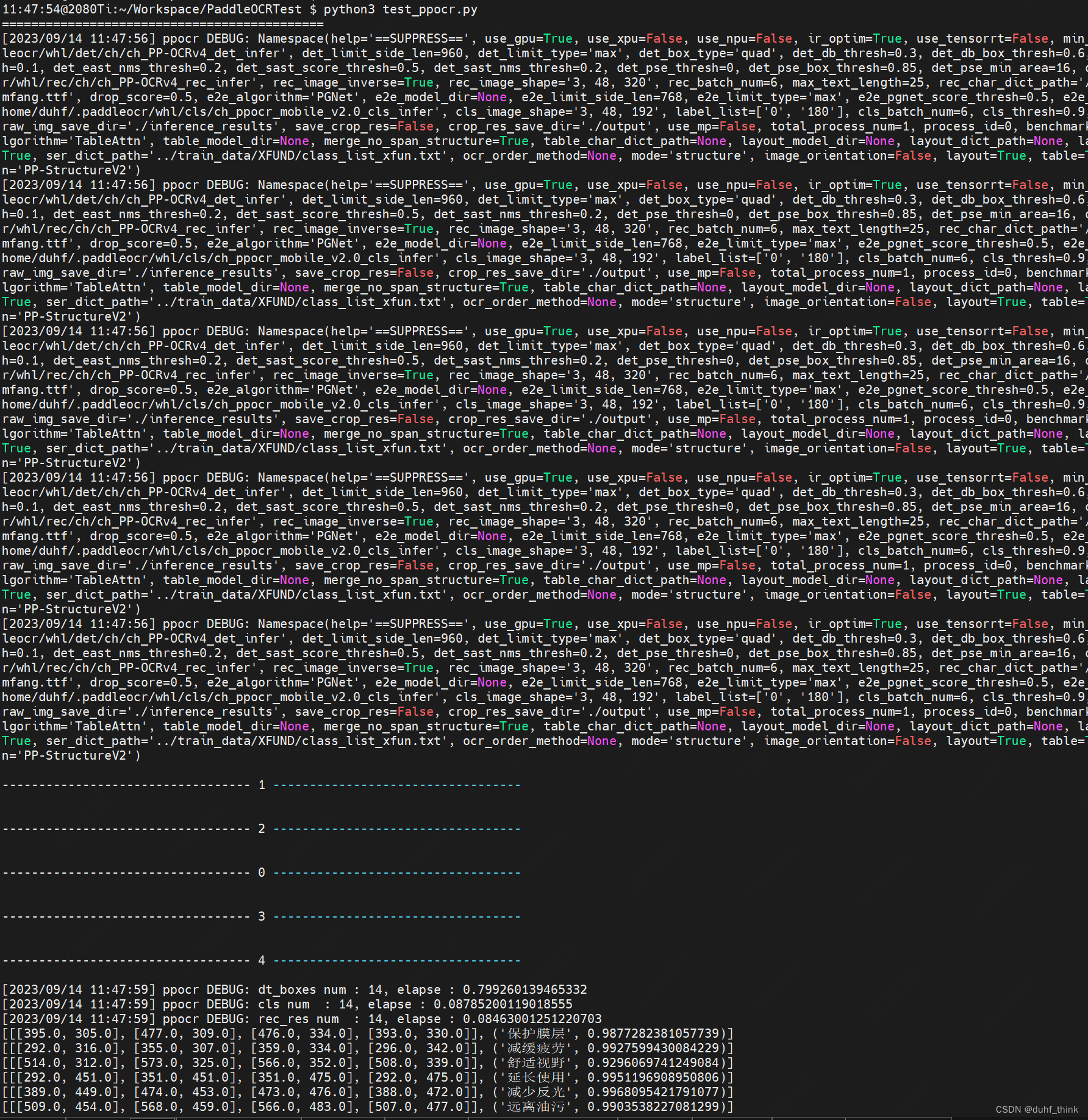

















 3311
3311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









