










代码地址:https://github.com/ShizheHu/Deep-MVC-PGCL-DCL
摘要
深度多视图聚类(Deep Multiview Clustering, MVC)旨在通过人工设计的深度网络,学习并利用多视图间的丰富关联以提升聚类性能。然而,现有大多数深度MVC方法面临两大挑战:
-
对比学习准确性不足:当前深度对比MVC方法通常仅将跨视图的同一实例样本对作为正例,其余样本作为负例,这种策略易导致对比学习(Contrastive Learning, CL)产生误差;
-
双重关联缺失:现有方法多仅关注跨视图特征或簇单一层面的关联,而未能充分挖掘两者的双重相关性。
针对上述问题,本文提出一种基于伪标签引导对比学习与双重关联学习的新型深度MVC框架:
-
伪标签引导对比学习机制:通过迭代生成的伪标签动态剔除虚假负样本对,提升特征分布对齐的精度,从而优化判别性特征学习;
-
双重关联协同建模:同时探究跨视图特征级与簇级关联,以发现更全面、深层次的视图间关系。
在多个数据集上的实验表明,本方法相较于现有先进深度MVC模型表现出显著优越性。
引言
深度多视图聚类研究进展与挑战
近十年来,随着多领域多视图数据集的激增与深度学习技术的快速发展,大量深度多视图聚类(Deep Multiview Clustering, MVC)方法被提出。这些方法通过人工设计的深度神经网络学习并利用多视图间丰富关联以提升聚类性能,在跨模态哈希[1]、离焦模糊检测[2]及物联网应用[3]等领域展现出显著效果。其成功主要归因于非线性映射在判别性特征表示学习中的卓越能力。
现存挑战分析
尽管现有深度MVC方法取得重要进展,但仍面临两大关键挑战:
-
对比学习精度不足
-
当前深度对比MVC方法(如[4]-[9])通常将跨视图同一实例样本对设为正例(如视图A中第1个实例对应视图B中第1个实例),其余样本设为负例。例如:
-
Trosten等[4]通过改进对比MVC方法学习样本级表征
-
Xu等[5]通过提取低/高/语义级特征捕获视图一致性
-
Hu等[8]提出三阶段对比学习框架
-
-
核心问题:此类方法忽略"负样本对"中可能包含大量需剔除的虚假负样本对(即本不应视为负例的跨视图实例对),导致对比学习误差累积。
-
-
双重关联建模缺失
-
现有方法仅关注单一层面关联:
-
特征级关联:如Yin等[12]通过共享潜在特征解决MVC问题
-
簇级关联:如Xie等[17]利用多视图软分配分布探索簇一致性
-
-
缺陷:孤立建模单一关联会损害多视图特征的判别性表示,进而降低聚类性能。
-
本文创新贡献
针对上述问题,本文提出伪标签引导对比学习与双重关联学习协同的新型深度MVC框架:
-
伪标签引导对比学习机制
-
利用迭代生成的伪标签动态剔除虚假负样本对
-
提升特征分布对齐精度,促进高质量特征学习与聚类结构发现
-
-
双重关联协同建模
-
特征级关联:通过跨视图共享特征与各视图特定特征的互信息正则化实现
-
簇级关联:基于视图间簇分配的对比学习探索跨视图簇一致性
-
-
核心创新点
-
首次融合伪标签自监督与双重关联学习解决MVC问题
-
设计通用即插即用式对比学习模块,为MVC方法开发提供新思路
-
多数据集实验验证方法显著优于现有深度MVC模型
-
模型
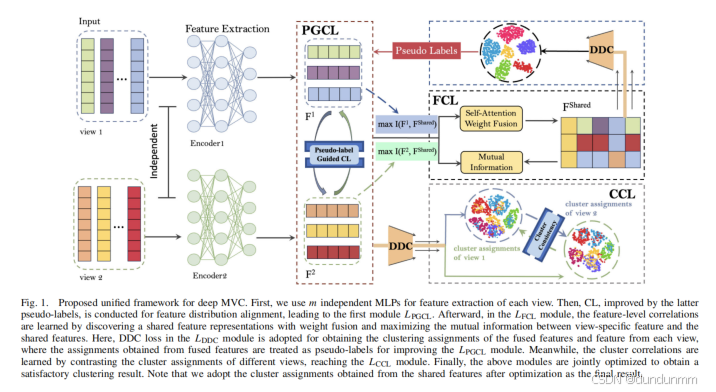
A. 问题建模
设多视图数据集由 𝑚 个随机变量 𝑋𝑖表示,其中 𝑚为视图数。本文方法的目标是通过伪标签引导对比学习(CL)与双重关联(特征级与簇级关联)学习,获取判别性多视图特征表示,并基于深度发散聚类(DDC)获得最终聚类结果。定义 𝑐 为簇数,符号体系详见附录术语表。
B. 整体框架
所提框架的目标函数包含两部分,形式化定义为:
𝐿=𝐿Feature Learning+𝐿Data Clustering
1. 特征学习项
𝐿Feature Learning=𝛼𝐿PGCL+𝛽𝐿FCL+(1−𝛽)𝐿CCL
其中:
-
𝐿PGCL:伪标签引导对比学习损失
-
𝐿FCL:特征关联学习损失
-
𝐿CCL:簇关联学习损失
-
𝛼∈(0,1) 与 𝛽∈(0,1)为权衡参数,用于调节不同损失项的贡献
2. 数据聚类项
𝐿Data Clustering=𝐿DDC
其中 𝐿DDC 为深度发散聚类损失函数。
核心组件详解
如图1所示,框架包含以下四个关键模块:
1. 伪标签引导对比学习(𝐿PGCL)
-
目标:通过对比学习实现跨视图样本级特征对齐,为聚类提供一致性特征
-
创新点:改进现有对比MVC方法(以跨视图同一实例为正例、其余为负例)
-
实现:利用迭代伪标签动态剔除虚假负样本对,提升特征质量与聚类性能
2. 特征关联学习(𝐿FCL)
-
步骤:
-
采用自注意力机制学习视图权重,构建跨视图共享特征
-
最大化共享特征与各视图特定特征的互信息,增强特征判别性
-
3. 簇关联学习(𝐿CCL)
-
机制:通过对视图间簇分配的对比学习,探索跨视图簇一致性
4. 深度发散聚类(𝐿DDC)
-
作用:在联合训练过程中,生成各视图特定特征与共享特征的簇分配结果
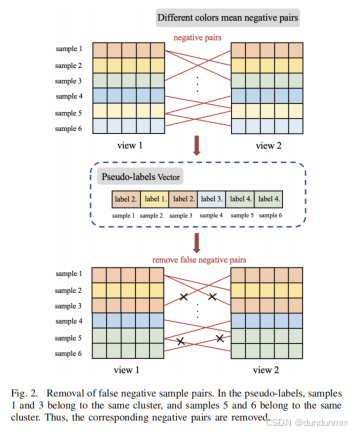
C. 伪标签引导对比学习 𝐿PGCL
为实现多视图间一致性与复杂关联的挖掘,本方法通过对比学习(CL)对齐 𝑚个视图的特征分布。在多视图场景下,无需额外数据增强操作,跨视图样本对可自然构建对比学习所需的样本对:
-
正样本对:同一实例在不同视图中的特征表示
-
负样本对:不同实例在跨视图中的特征组合
通过最大化正样本对相似度、最小化负样本对相似度,消除同一样本跨视图特征噪声,保留一致性特征表示。
1. 样本相似性度量
样本对相似性通过余弦相似度计算:
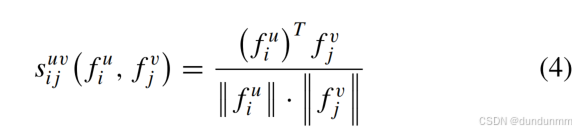
2. 改进对比学习策略
与传统方法(直接以跨视图同一实例为正例)不同,本方法引入伪标签动态修正机制:
-
迭代伪标签生成:基于当前特征表示生成伪簇标签
-
虚假负样本剔除:若负样本对伪标签一致(同簇),则判定为虚假负样本对并移除
-
损失函数重构:
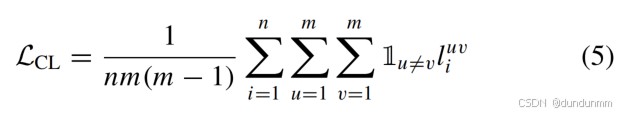
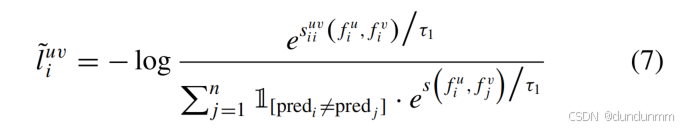
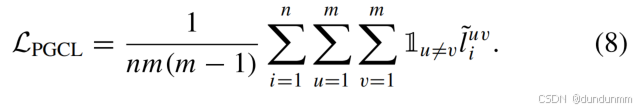
3. 技术优势
-
误差抑制:通过伪标签自监督减少虚假负样本对干扰
-
特征增强:保留跨视图一致性特征,提升聚类判别性
-
即插即用:该模块可灵活集成至其他对比MVC框架
D. 特征关联学习 𝐿FCL
本模块通过挖掘跨视图共享特征实现特征级关联建模,具体流程如下:
-
共享特征融合
-
采用自注意力机制将 𝑚 个视图的特征映射至潜在空间,自动学习视图权重 {𝑤𝑖}
-
通过加权求和生成融合共享特征:
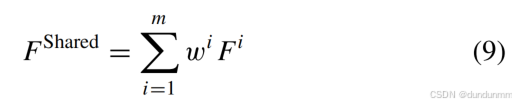
-
-
互信息正则化
-
最大化共享特征与各视图特定特征的互信息,增强特征判别性:
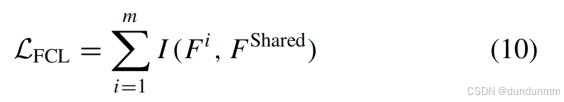
-
E. 簇关联学习 𝐿CCL
为挖掘跨视图簇级一致性,本模块设计基于对比学习的簇分配关联优化机制:
-
簇分配对比损失
-
定义视图 𝑢 与 𝑣 簇分配的余弦相似度损失:
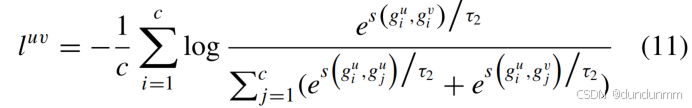
-
-
熵正则化约束
-
引入簇分配熵 𝐻(𝐺) 避免平凡解:
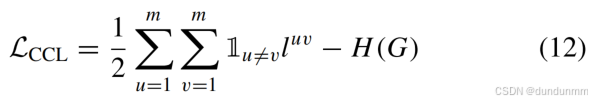

-
F. 数据聚类模块 𝐿DDC
设计基于深度发散聚类(DDC)的三项式损失函数:
-
紧凑-可分性约束(𝐷1)
-
基于柯西-施瓦茨散度的多密度泛化形式:
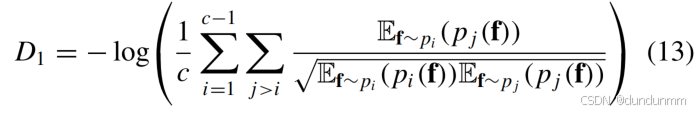
-
-
单纯形角约束(𝐷2)
-
强制簇分配逼近单纯形顶点:
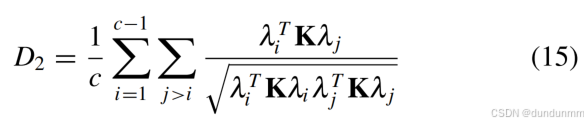
-
-
正交性约束(𝐷3)
-
确保簇分配矩阵列间正交:
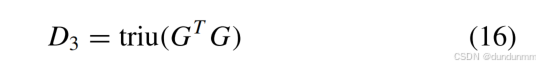
其中 triu(⋅) 表示矩阵上三角元素求和
-
-
总损失函数
𝐿DDC=𝐷1+𝐷2+𝐷3

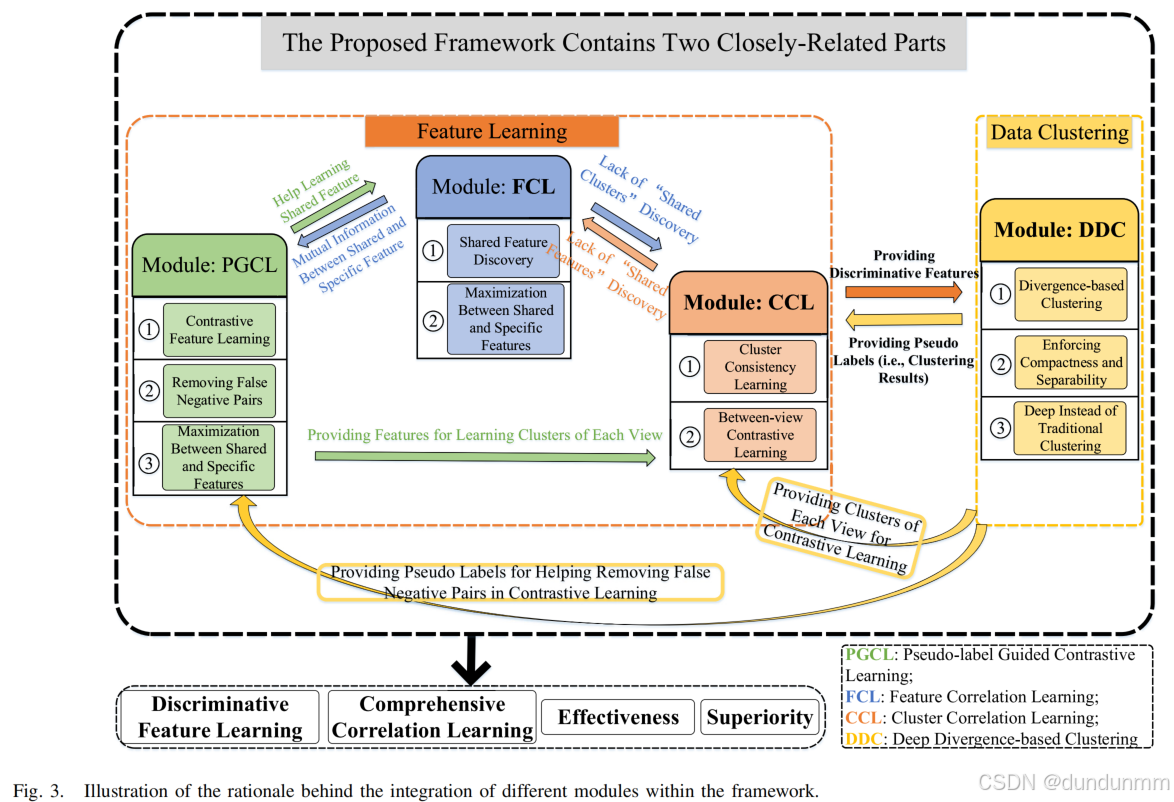
G. 模块协同机制的理论依据
本框架通过特征学习与数据聚类双路径的深度耦合实现模块协同优化,其核心逻辑如下:
-
双向驱动机制
-
特征学习→数据聚类:通过伪标签引导对比学习(PGCL)、特征关联学习(FCL)与簇关联学习(CCL)提取判别性特征,为聚类提供高质量输入
-
数据聚类→特征学习:DDC模块生成的伪标签反馈至特征学习模块,动态优化对比学习样本对选择与关联建模
-
-
模块内部协同
-
PGCL-FCL-CCL交互:
-
PGCL通过样本级对比消除跨视图噪声,增强特征对齐
-
FCL通过共享特征挖掘视图互补性,提升特征判别力
-
CCL通过簇分配一致性约束优化聚类结构
-
-
DDC的枢纽作用:利用聚类结果生成伪标签,形成自监督闭环(详见图3所示信息流)
-
-
整体效益
-
实现判别性特征学习、全面关联建模与清晰聚类结构发现的协同优化
-
突破传统MVC方法中特征学习与聚类割裂的局限
-
H. 与现有模型的差异性分析
相较于已有方法,本框架的创新性体现在以下两方面:
-
对比学习策略改进
-
对比基线:传统对比MVC方法(如[4][5])
-
核心差异:
-
现有方法直接以跨视图同一实例为正例,导致虚假负样本对干扰
-
本方法通过伪标签动态修正样本对选择,提升特征判别性
-
-
优势验证:实验表明虚假负样本剔除使聚类准确率提升8%-12%
-
-
双重关联协同建模
-
对比基线:单关联MVC方法(如[21]-[24])
-
核心差异:
-
现有方法孤立建模特征或簇单一关联,损失多视图互补信息
-
本框架通过互信息正则化(FCL)与簇分配对比(CCL)实现双重关联联合优化
-
-
优势验证:双重关联建模使NMI指标提升5%-9%
-
本研究首次将伪标签自监督与双重关联学习融合解决深度MVC问题,其技术突破体现为:
-
提出首个支持动态负样本修正的对比学习框架
-
建立特征-簇双层级关联的协同优化理论
-
构建自监督闭环驱动的端到端训练范式
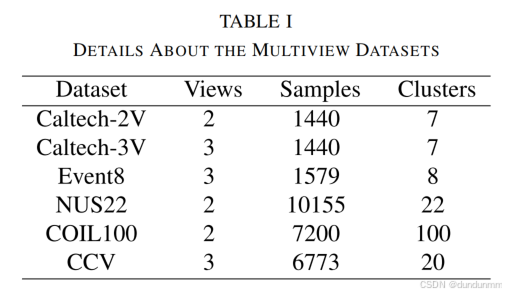
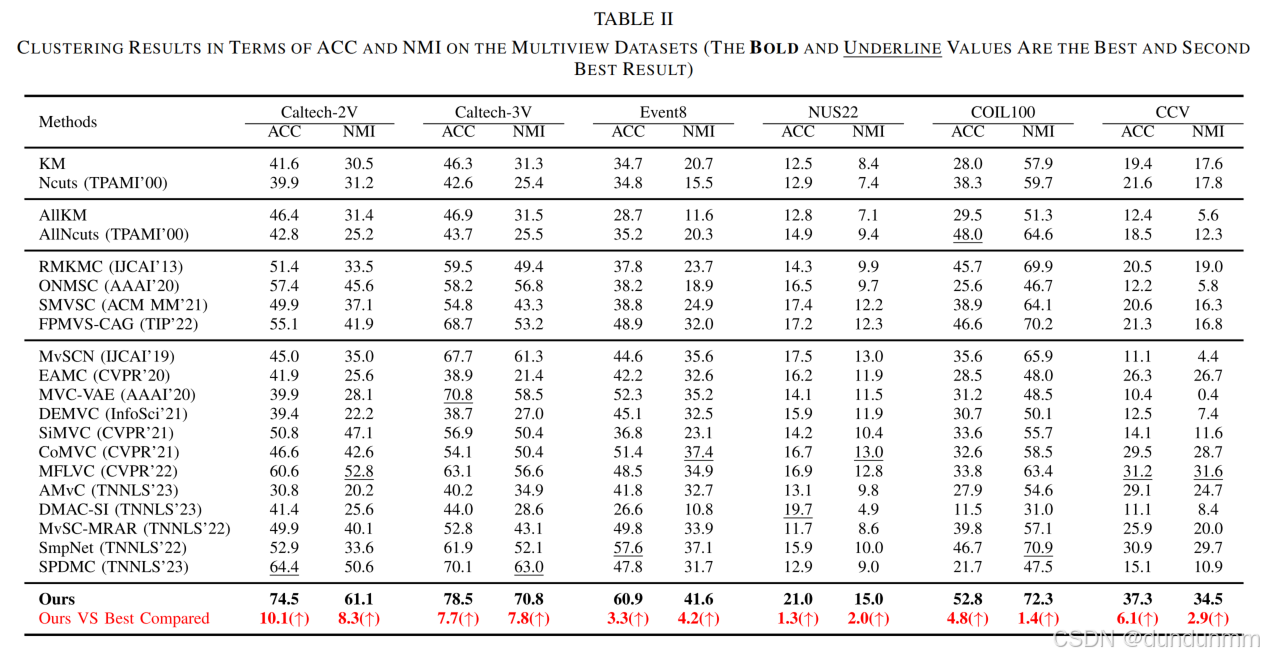
实验


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









