










背景
Google 的文化就是数据驱动:不停实验,不断得到实验结果进行分析并进行改进,这样就会导致所有R&D(Researcher&Developer)都会有不断实验的冲动和需求。这就对实验框架提出了文中重点描述的三个需求:
1. More: 更多能够同时进行的实验
2. Better:不合法的实验不能在框架中实验, 而合法的实验, 但如果效果不佳, 则应该能够被及时发现并下线
3. Faster:实验应该能快速建立并启动
和google search engine面临的问题一样,推荐系统也存在大量实验,故文中的思想可以在后续关键词推荐的设计中借鉴。
原有相关工作
一般来说,进行实验的目的有以下两个:
1. 测试新的features
2. 在已有features上,测试各种参数的最优值及组合
而原有框架却有较多限制。例如google在2007年以前使用single Layer模式,该方式实现较为简单, 却有很多限制, 包括:
1. 每个请求最多只能做一个实验,可能导致很多实验流量不足
2. 添加条件进行分流时会使框架变得复杂
3. 上游模块做了较多流量划分后,下游模块可能出现stravation的状况
另一种方式:Mutil-factorialdesign,让每个参数都相对独立地做实验,最多能同时做N个实验,其中N为参数个数。缺点是不容易调整,且很多参数是不独立的,文中给的例子是UI显示文字,背景的颜色不能相同。
Overlapping Experiment Infrastucture
主要思想:
1. 将待实验参数划分为独立的N组subsets。例如,不同的binary功能不一样,则可以认为他们的parameters不相交,可划分到不同的subsets中
2. 定义domain, layer,experiment后,对流量进行划分及条件判断,其中:
l Domain: 流量的划分,domain之间流量是不能有交集的
l Layer:每组相关的subset参数组成一个实验layer
l Experiment:具体实验,在一个subset中,测试0个及多个测试参数
3. Domain, layer, experiment可以嵌套
如下图所示:
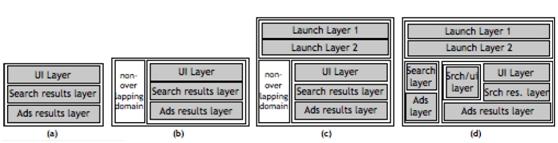
其中(a)为single layer,(b)为带有非覆盖domain的简单示例,(c)中包含两个launchlayer(d)中则存在更多嵌套
具体的参数设置, 既可以通过代码修改来实现, 也可以通过更新数据来制定(对应文中的binarypush 和data push,一般情况下data push 能够更快地进行更新)。
对于domain流量的划分,在searchengine 中一般是通过cookie来划分(不能通过request等非机器/用户属性进行划分,否则用户看到的效果可能出现跳动),而在Overlapping Experiment Infrastucture中,流量划分有以下原则:
1. Domain 流量不能有交集,一旦流量划分到某个domain,则流量不能再其他平级的domain中被使用,所以一般domain的划分可以使用。一般使用cookie,或是cookie-day,userid取模来进行划分。
2. Layer可以考虑使用不同的功能模块binary来进行划分参数。在各layers中,分流可使用mod =f(cookie, layer)进行流量划分
3. 在具体实验中,需要考虑condition(具体实验条件是否成立)
具体实验逻辑参见下图: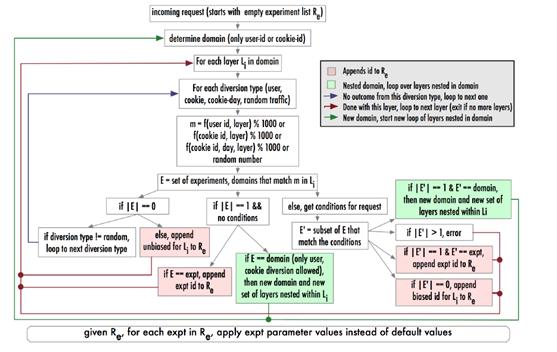
同时文中提到会使用配套数据校验工具校验数据格式正确性(其实这个是上线的必须具有的工具,并无新意),另外线上会时时关注重要指标,例如CTR,如果CTR等重要KPI超过异常边界,则新实验直接下线。这样的检测固然能保证避免异常,但是否会限制实验的上线速度需要思考,毕竟线上多个实验同时进行的话, CTR类似的KPI发生异常时,不能很快确认是哪个实验导致。
和传统方式一样, 实验框架提供的是实验流量的定位,但具体实验中,某次请求究竟是走了实验组逻辑,还是走了控制组逻辑,则仍需要从日志中分析。
其他
文中提到的以下内容也非常值得借鉴:
1. 文中提到了canary code的概念,表明google会在线上开实验,小流量测试代码正确性。也是正式,让google公司中RD/QA的比例很高(中国主要的search engine公司中,代码正确性更多是在线下验证,这就要求更多测试工程师)
2. 所有和实验框架的代码均被抽离成shared library的形式编译到各binary中,这样就让实验代码实现高度统一。但这里有一个问题:很多复杂系统中数据流是通过很多层binary后,才能得到最后的结果,如何控制各层之间的数据流向,设计时需要重点考虑。
需思考的问题
1. 涉及到多层次模块的架构中,如何控制各实验在各层之间的数据传输(如使用binary push的方式,则同一层的binary可能不一样,除非统一binary,而由data push控制)
2. 如何记录实验结果:文中使用logging的方式仍然会导致线下需要较多的logging事后分析的工作
也可关注我的微博: weibo.com/dustinsea
或直接访问 semocean.com















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









