








不到现场,照样看最干货的学术报告!
嗨,大家好。这里是学术报告专栏,读芯术小编不定期挑选并亲自跑会,为大家奉献科技领域最优秀的学术报告,为同学们记录报告干货,并想方设法搞到一手的PPT和现场视频——足够干货,足够新鲜!话不多说,快快看过来,希望这些优秀的青年学者、专家杰青的学术报告 ,能让您在业余时间的知识阅读更有价值。
人工智能论坛如今浩如烟海,有硬货、有干货的讲座却百里挑一。“AI未来说·青年学术论坛”系列讲座由中国科学院大学主办,百度全力支持,读芯术、paperweekly作为合作自媒体。承办单位为中国科学院大学学生会,协办单位为中国科学院计算所研究生会、网络中心研究生会、人工智能学院学生会、化学工程学院学生会、公共政策与管理学院学生会、微电子学院学生会。2020年7月26日,第17期“AI未来说·青年学术论坛”百度奖学金特别专场论坛以“线上平台直播+微信社群图文直播”形式举行。南京大学赵鹏带来报告《动态环境在线学习的算法与理论研究》。
南京大学赵鹏做“动态环境在线学习的算法与理论研究”主题报告分享
赵鹏,南京大学计算机系在读博士生。主要从事机器学习与数据挖掘方面的研究,在ICML, AISTATS, AAAI, UAI, KDD, ICDM等会议发表多篇文章。曾获得2019年百度奖学金。

动态环境在线学习的算法与理论研究

首先,赵鹏介绍了动态环境下在线学习的研究动机。考虑监督学习这一经典的学习范式,其基本流程是通过一些有标记的训练样本执行学习算法获得学习模型,然后这个模型会在未见的测试样本上面进行预测。这里一个重要的潜在假设是:训练和测试样本的数据分布要是相同的。但是在很多真实情况中,训练和测试的分布往往是不同的。例如训练数据可能是一些标准格式的图片,如从电商网站上面找到的图片。但真实测试可能是办公室或实验室环境,因此训练和测试的数据分布有很大差异。如果不加以考虑这种分布变化,学习算法的性能及理论保障都会丧失。这还只是两阶段的分布变化,在很多真实的场景中,数据是以在线的方式获得的。例如视频图像、天气预测、语音识别等任务中,数据随时间不断累积,而且环境不断发生变化,因此数据分布也会不断发生变化。这就要求我们重新思考并发展一些技术以对这类场景进行建模和分析。这就是动态环境下在线学习算法设计和理论研究的整体出发点。
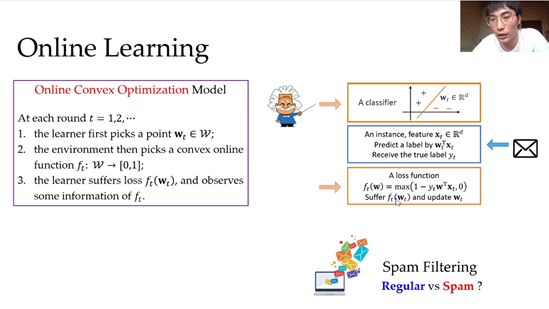
然后,赵鹏对动态在线学习问题进行了形式化。我们考虑的具体模型是在线凸优化(Online Convex Optimization,OCO)模型,该模型建模了学习者和环境不断交互的过程。在每一轮,学习者首先从凸集W指定一个决策点w_t(可以理解为一个模型),环境会选择一个凸损失函数,然后学习者会遭受损失并观测到函数的一定的信息,从而更新决策。以垃圾邮件判别为例,学习者就是学习器,初始为一个d维的w_t向量;之后来了一封邮件,我们希望判断它是垃圾邮件还是正常邮件。这就需要:第一步,获得它的属性信息,基于此可以做一个标记的预测。第二步,我们用真实的邮件标记定义出损失函数。通过该损失函数以及反馈的信息,我们就知道模型的表现,从而更新模型得到w_{t+1}。周此往复迭代这个学习过程。
同时,根据学习者能够接受到的环境信息,我们可把在线学习分为完全信息在线学习和部分信息在线学习,后者也称之为赌博机在线学习。完全信息在线学习好比赛马,一轮下来不仅知道押注的马的名次,其他马的名次也全都知道。赌博机在线学习好比玩多臂老虎机,一轮下来只知道选择的摇臂的奖赏,而不知道其他摇臂的情况。在这个报告中,我们主要关心赌博机在线学习,因为这个模型对真实世界建模的约束较少。OCO框架是一个非常有用的框架,在计算学习理论、计算经济学、信息论、理论计算机方面都有非常多的应用。

接下来,赵鹏介绍非稳态动态赌博机在线凸优化(BCO)方面的一些进展,包含单点反馈和两点反馈两种模型。在单点反馈模型中,学习者每轮只能送一个决策点(可以理解为模型),然后获得该点的函数值信息。注意,学习者只能获得函数值信息,没有函数梯度、Hessian矩阵等等,相当于是零阶优化的设定。两点反馈模型是上述单点反馈模型的泛化,学习者每一轮可以送两个决策点,然后获得这两个点的函数值信息。同样我们只有函数值的信息,而没有函数梯度、Hessian矩阵等信息。上述赌博机凸优化模型在网络路由、在线推荐、计算广告中都有非常广泛的应用。例如在线个性化推荐中,可以把广告主看作学习者,他需要从众多商品中挑选出客户可能感兴趣的一部分商品进行陈列,选出来的这些商品可以理解为上述模型中的一个单点决策。客户是否点击或者购买即为对广告主单点决策的反馈,而客户并不会给其他点(未展示商品)进行反馈。

紧接着,赵鹏介绍了针对BCO问题的评价指标。在线学习中一个广用的评价指标是regret(遗憾)。遗憾定义为算法产生序列的累计损失和离线算法的累计损失之差。但是这样的评价指标在动态场景中有一定不足之处,因为在动态环境下很难有一个固定的最优离线决策——固定的单点很难在动态环境中一直表现得很好。在动态环境下,每个时刻的最优决策都可能发生变化,这就要求我们考虑新的评价指标。一个做法是把求最小化操作放到求和号里面,这样展开后可以发现是将算法的决策跟每轮的最优决策进行对比,这样的评价指标称之为动态遗憾(dynamic regret)。进一步的,我们可以要求和任意一个决策序列进行比对,这样的评价指标更通用。

下面我们对三种评价指标做一个比对。大家最早关心的这类评价指标叫做 static regret,它适合于静态环境的在线学习,所有轮的决策只跟一个固定单点进行比较,比较偏乐观。第二个评价指标被称之为worst-case动态遗憾,它是和每一轮的最优值进行比较,比较偏悲观。特别是当环境并不是那么敌对,而只是有一些噪音,每轮函数的最优值可能会发生很大变化,如果强行去拟合每轮最优值就会产生过拟合的风险。最后一种,我们这里提的universal动态遗憾,它是和任意的决策序列进行对比,因此它更加自适应和一般化。而且注意到static遗憾和worst-case动态遗憾都可以看作是universal动态遗憾的特例。因此我们会特别关心这样一类评价指标。

上图中我们给出了动态赌博机凸优化问题的理论刻画。基于前面所述的universal动态遗憾的评价指标,我们设计了算法并证明了动态遗憾上界。同时,我们也给出了下界的分析以刻画问题难度。注意到,上下界中都包含一个P_T的项,它是对比序列的累积变化。当对比序列变化程度越大,就说明环境的动态程度越高,因此P_T这个量反映了环境的动态程度。当P_T比较大时,即环境动态程度比较大时,算法的动态遗憾上界会越松,BCO问题的下界也会越高,也就意味这个问题越难。当P_T比较小时,下界也会越低,问题也越简单,同时上界也会越紧,说明算法也会对应地表现得更好。这说明我们的算法可以自适应于环境的非稳定程度。
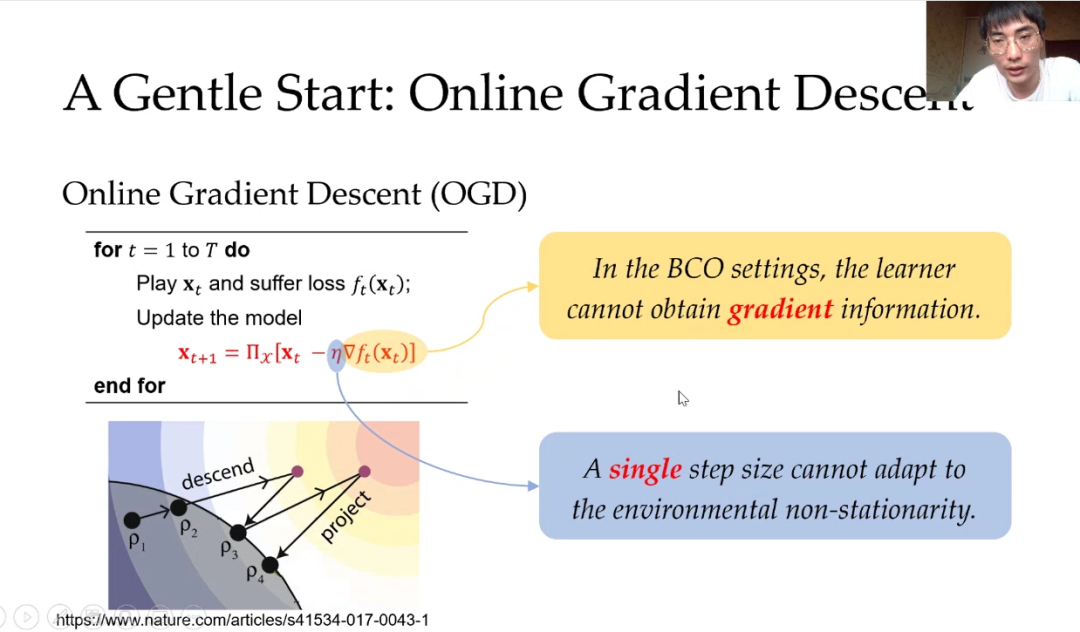
下面赵鹏从在线学习最常见的在线梯度下降优化算法开始讲起。介绍了该算法在动态赌博机场景中会遇到两个障碍:第一,BCO中没有函数梯度的反馈;第二,单一固定的步长很难适应于动态环境。赵鹏接下来的讲解围绕这两个点展开。

第一个想法是通过函数值来近似获得函数梯度。这里主要是使用文献[Flaxmanet al., 2015]中的技术,通过一个单点函数加扰动的做法获得函数梯度的无偏估计,可以证明它是这个函数平滑后的函数梯度的无偏估计。获得该梯度估计后,我们将其应用到在线梯度下降优化中便得到了Bandit Gradient Descent (BGD)算法。然后我们可以对BGD算法进行理论分析,推导发现动态遗憾的优化需要设置最优步长,然而最优步长需要提前预知环境的动态程度(即预知P_T),但真实情况下很难对动态环境有全面的把握。所以如何自适应步长也是一个挑战。下面我们会介绍如何自适应步长。

第二个想法就是用在线集成的想法来对冲环境的非稳定程度。主要分三步,第一步,把环境非稳态程度做一个离散化,通过log T数量级的点即可覆盖整个连续区间。第二步,对于步长池中选出每一个步长跑一个子算法。也就是说,如果步长池中有N个步长,则同时跑N个子算法。第三步,用在线集成的技术,将这些子算法的中间预测结果结合起来,从而得到每轮的最终预测。这样似乎看起来就已经解决问题了,但实际上在BCO设定下我们没法进行第二步,即没法跑多个子算法。这是因为在赌博机设定下缺乏足够的反馈(注意到我们每轮只有单点的函数值作为反馈)。而如果每一轮跑N个子算法,每轮最起码需要N个反馈,这在赌博机设定中是做不到的。这就需要进一步审视分析动态遗憾,我们发现本质上只需要优化平滑后的函数的动态遗憾即可,并证明这可以通过优化其线性化上界得到。基于此,我们设计了一种替代损失以供优化,从而可以在BCO设定下使用在线集成的方法。
最后,赵鹏做了总结。首先,这个工作引入并研究了动态环境下赌博机凸优化的问题,包括单点反馈和两点反馈模型。此外,设计了一种新颖的在线学习算法,并证明其具有良好的动态遗憾界保障。之后,通过下界的分析,对赌博机在线学习在动态遗憾这一评价指标下给出了难度的刻画。这个工作发表在AISTATS 2020上,长文版本在arXiv上可以看到,是在周志华老师的指导下,与王广辉同学、张利军老师共同完成的。
AI未来说*青年学术论坛
第一期 数据挖掘专场
1.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









