









hive是一个基于hadoop文件系统之上的数据仓库架构。它为数据仓库的管理提供了很多功能:数据ETL(抽取、转换、加载)工具、数据存储管理和大型数据集的查询和分析能力。同时,hive定义了类sql的语言——hive ql。hive ql允许用户进行和sql相似的操作,还允许开发人员方便地使用mapper和reducer操作,这对mapreduce框架是一个强有力的支持。
一、hive简介
hive是什么?
- hive是建立在hadoop体系架构上的一个数据仓库基础工具,用来处理结构化数据,使得查询和分析方便;
hive不是
- hive不是一个关系型数据库,不提供排序和查询cache功能,不提供在线事务处理,也不提供实时的查询和记录级的更新;
hive特点:
- 它是存储架构在一个数据库中,并处理数据到hdfs;
- 它是专为OLAP设计;
- 提供sql类型语言查询,叫做hive ql或hql;
- 可扩展、可延展性、良好的容错性和低约束的数据输入格式。
hive架构
- hive组件图的结构:

| 单元名称 | 操作 |
|---|---|
| 用户接口/界面 | Hive是一个数据仓库基础工具软件,可以创建用户和HDFS之间互动。用户界面,Hive支持是Hive的Web UI,Hive命令行,HiveHD洞察(在Windows服务器)。 |
| 元数据 | Hive选择各自的数据库服务器,用以储存表,数据库,列模式或元数据表,它们的数据类型和HDFS映射。 |
| HiveQL处理引擎 | HiveQL类似于SQL的查询上Metastore模式信息。这是传统的方式进行MapReduce程序的替代品之一。相反,使用Java编写的MapReduce程序,可以编写为MapReduce工作,并处理它的查询。 |
| 执行引擎 | HiveQL处理引擎和MapReduce的结合部分是由Hive执行引擎。执行引擎处理查询并产生结果和MapReduce的结果一样。它采用MapReduce方法。 |
| HDFS 或 HBASE | Hadoop的分布式文件系统或者HBASE数据存储技术是用于将数据存储到文件系统。 |
hive工作原理
- hive和hadoop之间的工作流程:

二、hive的安装部署
系统环境:
- 安装hive的前提是必需先安装好hadoop环境。本次安装使用hadoop-2.4.1版本。
- java版本是java1.7.0_65
hadoop的安装可以使用:
- 1.单机环境
- 2.伪分布环境(本次选用伪分布环境)
- 3.集群环境
hive的安装模式
- 1.嵌入模式
元数据信息被存储在hive自带的Derby数据库中;
只允许创建一个连接;
多用于Demo。 - 2.本地模式
元数据信息被存储在MySQL数据库中;
MySQL数据库与hive运行在同一台物理机上;
多用于开发和测试。 - 3.远程模式
元数据信息被存储在MySQL数据库中,但是hive和MySQL运行在不同的操作系统上;
允许创建多个连接;
多用于生产环境。
独立模式的安装
准备工作
- 下载hive安装包,hive-0.9.0.tar.gz。
- 下载mysql安装包,包括三个:
MySQL-client-5.5.31-2.el6.i686.rpm
MySQL-server-5.5.31-2.el6.i686.rpm
mysql-connector-java-5.1.10.jar。
开始安装
- 解压:
tar -zxvf hive-0.9.0.tar.gz/home/hadoop - 重命名:
mv hive-0.9.0 hive - 配置环境变量:
vim /etc/profile
在文件的最后添加hive的配置环境:
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_65/
export HADOOP_HOME=/home/hadoop/app/hadoop-2.4.1/
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HIVE_HOME=/home/hadoop/hive
export PATH=$HIVE_HOME/bin:$PATH
修改后需要使环境变量生效:
source /etc/profile - 配置hive相关文件:
进入hive的conf目录下,修改默认模板:
(1)在该目录下,执行命令
mv hive-default.xml.template hive-site.xml
mv hive-env.sh.template hive-env.sh
mv hive-log4j.properties.template hive-log4j.properties
进行重命名。结果如下:
-rw-rw-r--. 1 hadoop hadoop 2378 Apr 24 2012 hive-env.sh
-rw-rw-r--. 1 hadoop hadoop 2422 Apr 24 2012 hive-exec-log4j.properties.template
-rw-rw-r--. 1 hadoop hadoop 2899 May 11 23:02 hive-log4j.properties
-rw-rw-r--. 1 hadoop hadoop 48899 May 12 06:48 hive-site.xml
修改hive-log4j.properties:
#log4j.appender.EventCounter=org.apache.hadoop.metrics.jvm.EventCounter
log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter
在命令行输入:hive即可进入hive。
至此,hive的嵌入式模式安装完成!可以建立一个简单的hive表:
create table student
(
name string,
sex string,
age int
);
查看表:
show tables;
查看student表的结构:
desc student;
下面安装独立模式,并选择mysql作为元数据库。 - 创建mysql元数据库:
删除linux上已经安装的mysql相关库信息(切换至root用户):
rpm -e xxxxxxx --nodeps
检查是否删除干净:
rpm -qa |grep mysql
安装mysql服务端:
rpm -i MySQL-server-5.5.31-2.el6.i686.rpm
启动mysql服务端:
mysqld_safe &
安装mysql客户端:
rpm -i MySQL-client-5.5.31-2.el6.i686.rpm
用root账户进入mysql:
mysql -uroot
为hive创建相应的mysql账户(账户和密码均为hive),创建hive元数据库,并赋予足够的权限:
create user 'hive' identified by 'hive';
create database hive;
grant all privileges on *.* to 'hive'@'localhost' identified by 'hive';
使之立即生效:
flush privileges;
退出mysql,并使用刚才的hive进行连接:
mysql -uhive -p
提示输入密码,输入hive即可进入mysql。 - 使用mysql作为hive的metastore:
把mysql的jdbc驱动包放置到hive的lib目录下:
cp /home/hadoop/mysql-connector-java-5.1.10.jar /home/hadoop/hive/lib
在hdfs上创建目录,并修改权限:
hadoop fs -mkdir /tmp/hive
hadoop fs -chmod -R 777 /tmp/hive
配置相应的hive-site.xml文件,修改如下信息:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property> - 启动hive shell:
hive
或启动静默模式:
hive -S
至此hive的独立模式安装完毕! - 远程模式和独立模式差不多,区别就是mysql安装在另一台设备上面。需要修改:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://<远程主机IP>:3306/hive</value>
</property>
三、hive的操作
安装好了hive以后,就可以使用不同的方式对hive数据仓库中的数据进行管理。hive为我们提供了几种不同的方式来管理数据。hive的启动方式:
- CLI(命令行)方式(重点介绍)
- Web界面方式
- 远程服务启动方式
CLI(命令行)方式
- 直接输入hive(hive -S静默模式)
- 输入hive –service cli
常用的CLI命令
- 清屏:
Ctrl+l或者!clear- 查看数据仓库中的表:
show tables;- 查看数据仓库中内置的函数:
show functions;- 查看表的结构:
desc 表名;- 查看HDFS上的文件:
dfs -ls 目录;- 在hive里面操作linux操作系统的命令:
! 命令;- 执行HQL语句:
select *** from ***;- 执行SQL的脚本:
source SQL文件;- 在linux操作系系统上执行hive命令:
hive -e 'hive命令';
hive -S -e 'hive命令';(静默模式)hive的数据类型
hive是一个数据仓库,本质上也是一个数据库。所以可以在hive里面创建表,保存数据。创建表就会有相对应的列,而列就有相对应的类型。hive里面可以将数据类型分为一下三种:
- 基本数据类型
- 复杂数据类型
- 时间数据类型
基本数据类型
- tinyint/smallint/int/bigint:整数类型
- float/double:浮点数类型
- boolean:布尔类型
- string:字符串类型
复杂数据类型
- Array:数组类型,由一系列相同数据类型的元素组成
- Map:集合类型,包含key->value键值对,可以通过key来访问元素
- Struct:结构类型,可以包含不同数据类型的元素。这些元素可以通过“点语法”的方式来得到所需要的元素
时间类型
- Date:从hive0.12.0开始支持
即日期,分为年、月、日。 - Timestamp:从hive0.8.0开始支持
与时区无关。
当前系统的时间戳:
select unix_timestamp();hive的数据模型
hive的数据存储
- 基于HDFS
hive是基于hadoop上的数据仓库,所以hive上的数据都是保存在HDFS文件系统之上的。在hive上创建一个表同时会自动地在HDFS上创建一个文件夹,在表中保存的数据就对应于该文件夹下的文件。 - 没有专门的数据存储格式
可以用一个文本文件、CSV文件代表表中的数据。因为我们在创建一张表的时候,可以指明列跟列之间的分隔符,所以在hive中没有专门指定的数据存储格式。默认情况下,使用的是制表符。 - 存储结构主要包括:数据库、文件、表、视图。
- 可以直接加载文本文件(.txt文件等)。
- 创建表时,指定hive数据的列分隔符与行分隔符。
hive中表的分类:
- Table内部表
1.与数据库中的Table在概念上是类似的;
2.每一个Table在hive中都有一个相应的目录来存储数据;
3.所有的Table数据(不包括External Table)都保存在这个目录中;
4.删除表时,元数据与数据都会被删除。
几条常用命令:
create table t1
(tid int,tname string,age int);//创建一个内部表
----------
create table t2
(tid int,tname string,age int)
location '/mytable/hive/t2';//在HDFS具体的目录上创建一个表
----------
create table t3
(tid int,tname string,age int)
row format delimited fields terminated by ',';//指明分隔符,此处用的逗号分隔符,可直接导入CSV的文件
----------
create table t4
as
select * from sample_data;//以其他表中的内容创建另一个表
----------
alter table t1
add columns (english int);//为t1增加新的列
----------
drop table t1;//删除一个表(到回收站)- Partition分区表
1.Partition对应于数据库的Partition列的密集索引;
2.在hive中,表中的Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中
create table partition_table(sid int,sname string)
partitioned by (gender string)
row format delimited fields terminated by ',';//创建分区表
----------
insert into table partition_table partition(gender='M') select sid,sname from sample_data where gender='M';
insert into table partition_table partition(gender='F') select sid,sname from sample_data where gender='F';//插入数据当数据量很大的时候,进行分区可以提高查询的效率。那怎么知道效率提高了呢?可以通过执行计划来看
explain select * from sample_data where gender='M';
explain select * from Partition_tablewhere gender='M';- External Table外部表
1.指向已经在HDFS中存在的数据,可以创建Partition;
2.它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异;
3.外部表只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅删除该链接。
4.hive数据仓库,创建外部表,只需要指明列的名字、类型就行,因为其存在外部,不需要知道其来源,但需要指明location,其指向hdfs中的数据。
a.创建若干文件,放入HDFS中:
hadoop fs -put student01.txt /input
hadoop fs -put student02.txt /input
hadoop fs -put student03.txt /inputb.建立外部表,指向创建的文件:
create external table external_student
(sid int, sname string, age int)
row format delimited fields terminated by ',' // 列之间的分隔符
location '/input';//这张表指向创建的文件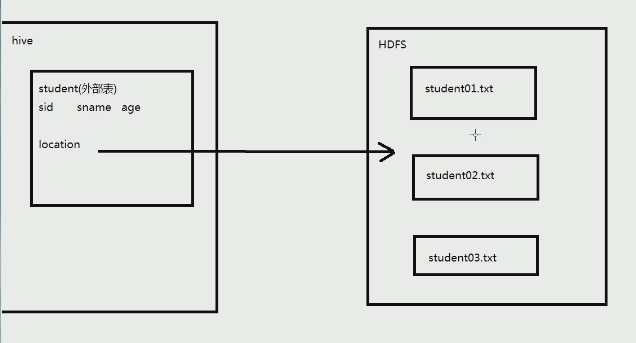
* Bucker Table桶表
桶表是对数据进行哈希取值,然后放到不同文件中存储。















 763
763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









