







大家好,我是才哥。
在 Excel 中IF 函数是最常用的函数之一,它可以对值和期待值进行逻辑比较。 因此IF 语句可能有两个结果: 第一个结果是比较结果为 True,第二个结果是比较结果为 False。
例如,=IF(C2=”Yes”,1,2) 表示 IF(C2 = Yes, 则返回 1, 否则返回 2)。
那么,在Pandas里我们可以怎么来轻松搞定这一操作呢?
今天,我们就来了解一下!
目录:
1. 案例需求
原始数据如下,是一份虚构的学生成绩单
| 姓名 | 语文 | 数学 | 英语 | 性别 |
|---|---|---|---|---|
| 才哥 | 91 | 95 | 92 | 1 |
| 小明 | 82 | 93 | 91 | 1 |
| 小华 | 82 | 87 | 94 | 1 |
| 小草 | 46 | 55 | 58 | 0 |
| 小红 | 51 | 41 | 70 | 0 |
| 小花 | 58 | 59 | 40 | 0 |
| 小龙 | 70 | 55 | 59 | 1 |
| 杰克 | 53 | 44 | 42 | 1 |
| 韩梅梅 | 45 | 51 | 67 | 0 |
现在我们有两个需求:
- 语数英三科评级,低于60分标记为不及格、60-89为及格、90分以上为高分;
- 性别中1为男性、0为女性。
2. Excel轻松搞定
如果用Excel来处理,首先可以想到用IF函数的方法
对于语数英科目评级中,可以用到以下公式实现:
=IF(B2<60,"不及格",IF(B2<90,"及格","高分"))
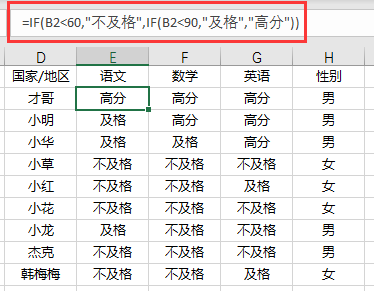
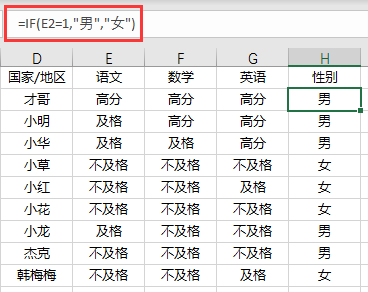
对于性别标识来说,可以用以下公式实现:
=IF(E2=1,"男","女")
当然了,以上是IF函数的方法,我们还可以用lookup进行实现:
# 语数外三科评级
=LOOKUP(B2,{0,"不及格";60,"及格";90,"高分"})
# 性别标识
=LOOKUP(E2,{0,"女";1,"男"})
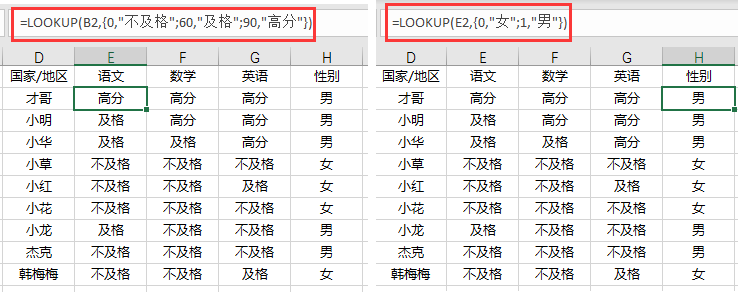
需要注意的是,LOOKUP中的条件是向后兼容哈
3. Pandas处理
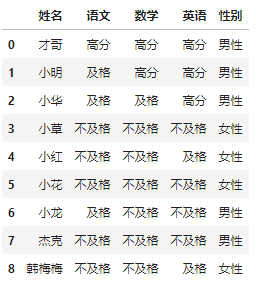
这里通过df.where和np.where两个函数来实现需求,先看代码,然后我们再讲解下
import pandas as pd
# 读取数据
df = pd.read_excel(r'F:\Python\pandas数据处理\案例数据.xlsx')
# 筛选 语数外 评分
score = df.loc[:,'语文':'英语']
# 评级
data = score.where(score>100, np.where(score<60,"不及格", np.where(score<90,"及格","高分")))
# 性别
data['性别'] = df['性别'].where(df['性别']>100, np.where(df['性别']==0, '女性', '男性'))
data.insert(0,'姓名', df['姓名'])
data
以上实现方案中,用到的两个where函数,其实就和excel里的if很类似。
df.where
该函数可以将满足条件的函数筛选出来,将不满足条件的值赋值为另外一个值,默认情况下为NaN。
Signature:
df.where(
cond,
other=nan,
inplace=False,
axis=None,
level=None,
errors='raise',
try_cast=<no_default>,
)
Docstring:
Replace values where the condition is False.
从函数介绍来看,它能做到的只有一种条件判断,然后只能对不满足要求的值进行赋值操作,比如:
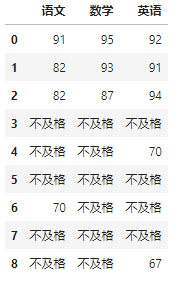
# 显示≥60的值,低于60分显示为 不及格
df[['语文','数学','英语']].where(df[['语文','数学','英语']]>60, '不及格')
np.where
既然df.where无法对多种情况进行分别赋值, 那么np.where就来了
Docstring:
where(condition, [x, y])
Return elements chosen from `x` or `y` depending on `condition`.
Parameters
----------
condition : array_like, bool
Where True, yield `x`, otherwise yield `y`.
x, y : array_like
Values from which to choose. `x`, `y` and `condition` need to be
broadcastable to some shape.
Returns
-------
out : ndarray
An array with elements from `x` where `condition` is True, and elements
from `y` elsewhere.
和Excel中IF函数更接近的其实就是np.where这个函数,如果条件满足则赋值x,否则赋值y。
比如:
>>> import numpy as np
>>> a = np.arange(10)
>>> a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.where(a < 5, a, 10*a)
array([ 0, 1, 2, 3, 4, 50, 60, 70, 80, 90])
上述例子中,如果值小于5,则显示值本身;反之则 乘以10。
我们就可以构建对科目评分进行评级的双层条件,具体如下:
# 如果小于60就不及格,否则再进行后面的判断
np.where(score<60,"不及格", np.where(score<90,"及格","高分"))

基于以上的介绍,我们要完成本次的需求就有了以下的实现方案:
# 筛选 语数外 评分
score = df.loc[:,'语文':'英语']
# 评级
data = score.where(score>100, np.where(score<60,"不及格", np.where(score<90,"及格","高分")))
# 性别
data['性别'] = np.where(df['性别']==0, '女性', '男性')
需要注意的是,这里咱们对性别标识的处理稍微区别于开头的完整代码中的,大家知道为什么可以这么写吗?(DataFrame和Series的小区别)
以上,就是本次用Pandas实现Excel里IF函数方法的操作了,感兴趣的你可以试试哦!
4. 延伸
tips one
既然有 df.where 筛选满足条件的值显示,不满足的进行赋值。那么,是不是有筛选满足条件的值进行赋值,不满足的值显示呢?
答案是肯定的!
这便是df.mask函数方法,其效果和df.where基本相反。
>>> import pandas as pd
>>> s = pd.Series(range(5))
>>> s.where(s > 0)
0 NaN
1 1.0
2 2.0
3 3.0
4 4.0
dtype: float64
>>> s.mask(s > 0)
0 0.0
1 NaN
2 NaN
3 NaN
4 NaN
dtype: float64
>>> s.where(s > 1, 10)
0 10
1 10
2 2
3 3
4 4
dtype: int64
>>> s.mask(s > 1, 10)
0 0
1 1
2 10
3 10
4 10
dtype: int64
tips two
其实吧,实现我们今天案例的需求还有很多方案,这里再简单介绍几种思路(答案可见后续推文)
- 通过 自定义函数 if else来处理,然后apply或map调用
- 通过 cut分箱 来处理
- 通过 replace 来处理
- 又或者 where与mask组合来处理
- 其他方案
感兴趣的朋友,可以试试哦,然后我们一起交流交流
添加作者微信 gdc2918,加入交流群搞起~~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









