







文章目录
前言
复杂的神经网络也是由许多神经元组成,在深度学习领域,神经元即感知机。深度学习通过许多感知机,尽可能的学习一个任务的复杂数学表示。神经网络在模拟生物神经元时,创造性的引入非线性的函数,通过判断是否达到阈值,来觉得信号是否输出,完成信息传递。因此,在阶跃函数的基础上,进一步优化,拓展,得到sigmoid激活函数、Relu、leak ReLu等,细细品味,你将发现这构思的巧妙性、合理性。
本节主要MNIST的代码实现,关于感知机,激活函数等介绍,大家可以参考入手这本书,通俗易懂,内容详实,极具阅读价值。
pdf 地址如下,仅供学习参考:
链接: https://wwe.lanzous.com/ieOE2noazwj.

一、Torch相关包介绍
torch.nn :完成神经网络一些相关操作,包含了在计算机视觉任务中常用到的卷积,池化等一些列API接口实现。
torch.nn.fubctional : 可以比nn更进一步接触实现底层代码的修改。
torch.nn.optim:优化器,提供了学习率设置,及更好的梯度下降方式的选择。
torchvision:计算机视觉任务的工具,提供了常用的数据集,模型,转换函数等。实现视觉类任务如分类、目标检测、分割必不可少的。
导入所需包(示例):
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
若提示出错,可使用命令行窗口,进行 conda install 安装。或者在pycharm中进行安装,以pycharm为例:输入要安装的包,点击安装即可。
二、搭建多层感知机
1.MNIST介绍
MNIST简介: 包含0-9 共10个手写数字,每个数字由7000张(高度28*宽度28)的图像,将70k数据,分为了训练集60K,测试集10大小。本节,通过感知机实现对MNIST手写数字的分类。
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.下载MNIST数据集
如果下载失败,也可使用下载好的数据集,还在目录下:
链接: https://wwe.lanzous.com/b01c9d0sj.
密码:3dii

代码如下:
‘./data’:设置要保存的下载目录。
train=True:设置要下载的是60k的训练数据集。
download=True:如果当前文件夹没有数据集,则从网上下载。
transforms.ToTensor():下载的数据集为numpy格式,需要转换为张量格式。
transforms.Normalize((0.1307,), (0.3081,):(此项非必要设置项)为了更好的训练结果,因为图像的数据值是0-1之间,将数据值正则花在0左右,对模型梯度下降效果更好。
batch_size=batch_size, shuffle=True:设置批次大小,随机打算数据。
测试集设置类似
#MNIST 数据集
#设置训练的批次大小、学习率、及训练代数
batch_size=200
learning_rate=0.001
epochs=20
#下载数据集
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
3.搭建神经网络层
1.权重和偏置
代码如下:
w1,b1:第一层网络感知机。输入图像大小是28*28=784,因此输入为784,输出设置为100(这个参数随意设置,可以尝试不同的数目查看效果)因为W要转置所以输入放后面,输出放前面。b1为第一层网络对应的偏置项。
w2, b2:与上叙述类似。
==w3, b3 ==:注意输出要与分类的10个数字类别数一致,其他与上述类似。
requires_grad=True:此项设置为True,表示要对w,b求梯度。
#生成 三个神经网络成,对应感知节分别为第一层100,第二成200,第三层10,即要分类的数目
w1, b1 = torch.randn(100, 784, requires_grad=True),\
torch.zeros(100, requires_grad=True)
w2, b2 = torch.randn(200, 100, requires_grad=True),\
torch.zeros(200, requires_grad=True)
w3, b3 = torch.randn(10, 200, requires_grad=True),\
torch.zeros(10, requires_grad=True)
2.定义前向计算网络
代码如下:
relu激活函数:确保网络的非线性,实现更好的分类效果。
#定义前向网络计算,每层神经网络输出后增加relu激活函数,确保网络的非线性,实现更好的分类效果
def forward(x):
x = x@w1.t() + b1
x = F.relu(x)
x = x@w2.t() + b2
x = F.relu(x)
x = x@w3.t() + b3
x = F.relu(x)
return x
3.定义梯度优化器及损失函数设置
代码如下:
.CrossEntropyLoss():损失采用交叉熵损失函数。
.SGD:采用随机梯度下降,并设置学习率。
#定义优化器,采用SGD随机梯度下降的方式对w1, b1, w2, b2, w3, b3进行优化
optimizer = optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate)
#定义采用交叉熵作为损失函数
criteon = nn.CrossEntropyLoss()
4.完成程序设计
代码如下:
#设置迭代次数
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
#将数据打平为(批次,高度*宽度),-1代表所有
data = data.view(-1, 28*28)
#将数据输入到网络中
cal_data = forward(data)
#将计算的数据与目标数据求误差损失
loss = criteon(cal_data, target)
#将梯度值初始化为0
optimizer.zero_grad()
#pytorch计算梯度值
loss.backward()
#更新梯度值
optimizer.step()
#每隔25*batcsize(200) = 5000 打印输出结果
if batch_idx % 25 == 0:
print('训练代数: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
#将测试误差及正确率清0
test_loss = 0
correct = 0
#取测试集数据及目标数据
for data, target in test_loader:
data = data.view(-1, 28 * 28)
logits = forward(data)
#误差累加
test_loss += criteon(logits, target).item()
#取出预测最大值的索引编号,即预测值
pred = logits.data.argmax(dim=1)
#统计正确预测的个数
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
#打印输出测试误差及准确率
print('\n测试集: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
三、完整代码程序
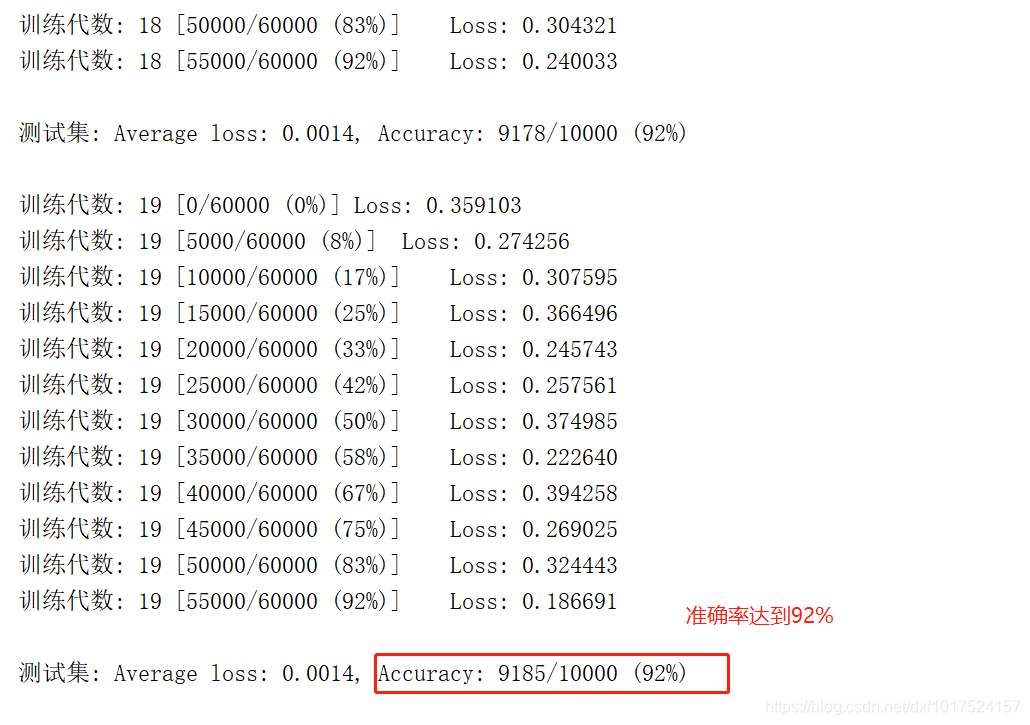
因为我们自己随机生成的初始化 w1,w2,w3,达到的性能并不好。所以我们可以采用大神何凯明的初始化权重对w1,w2,w3 进行初始化赋值,准确率可以达到90%。小伙伴们可以尝试下,将初始化赋值代码屏蔽,对比查看效果。
代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
#MNIST 数据集
#设置训练的批次大小、学习率、及训练代数
batch_size=200
learning_rate=0.001
epochs=20
#下载数据集
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
#生成三层神经网络成,对应感知机分别为第一层100,第二成200,第三层10,即要分类的数目
w1, b1 = torch.randn(100, 784, requires_grad=True),\
torch.zeros(100, requires_grad=True)
w2, b2 = torch.randn(200, 100, requires_grad=True),\
torch.zeros(200, requires_grad=True)
w3, b3 = torch.randn(10, 200, requires_grad=True),\
torch.zeros(10, requires_grad=True)
#采用何凯明大神的初始化权重,准确率更高,权重的合理初始化很重要
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)
#定义前向网络计算,每层神经网络输出后增加relu激活函数,确保网络的非线性,实现更好的分类效果
def forward(x):
x = x@w1.t() + b1
x = F.relu(x)
x = x@w2.t() + b2
x = F.relu(x)
x = x@w3.t() + b3
x = F.relu(x)
return x
#定义优化器,采用SGD随机梯度下降的方式对w1, b1, w2, b2, w3, b3进行优化
optimizer = optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate)
#定义采用交叉熵作为损失函数
criteon = nn.CrossEntropyLoss()
# 设置迭代次数
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
# 将数据打平为(批次,高度*宽度),-1代表所有
data = data.view(-1, 28 * 28)
# 将数据输入到网络中
cal_data = forward(data)
# 将计算的数据与目标数据求误差损失
loss = criteon(cal_data, target)
# 将梯度值初始化为0
optimizer.zero_grad()
# pytorch计算梯度值
loss.backward()
# 更新梯度值
optimizer.step()
# 每隔25*batcsize(200) = 5000 打印输出结果
if batch_idx % 25 == 0:
print('训练代数: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 将测试误差及正确率清0
test_loss = 0
correct = 0
# 取测试集数据及目标数据
for data, target in test_loader:
data = data.view(-1, 28 * 28)
logits = forward(data)
# 误差累加
test_loss += criteon(logits, target).item()
# 取出预测最大值的索引编号,即预测值
pred = logits.data.argmax(dim=1)
# 统计正确预测的个数
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
# 打印输出测试误差及准确率
print('\n测试集: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
输出结果:
总结
这一节,我们从底层搭建了一个三层的感知机神经网络,对手写数字数据集MNIST进行训练和测试,达到了92%的正确率。权重的随机初始化,对结果是很重要的,但在torch更高层的API使用中提供了很好的初始化,会在下一节中进行讲解。最后劳烦小伙伴,动手点个赞吧,给予我爆发小宇宙的能量。














 3027
3027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









