







1. 数据库的专业术语
- DB(数据库):database,用来存储数据的地方,存放了许多有组织的数据;
- DBMS(数据库管理系统):database Management System,数据库是DBMS创建和操作的容器;(我们一般安装的就是DBMS,用来操作DB)
- SQL(结构化查询语言):用来增删改查的语言;几乎所有的DBMS都支持SQL语言;
- DBMS分为两类:一类是基于共享文件系统的DBMS(例如Access);另一类是基于客户端_服务器端的DBMS(例如MYSQL,Oracle等);
- 一般情况下,在安装目录中有一个my.ini文件;这里面是一些MySQL的配置,比如端口号,比如数据存储的位置;
- 注释:使用#进行单行注释,获得是使用"-- "其中空格是必须的;多行注释:使用/**/;
- DQL(data query language):数据查询语言(查询Select);
- DML(数据操作语言):插入,修改,删除;
2. 在命令行的一些基本操作
启动数据库,(启动使用Windows的cmd时,一定要使用管理员权限)
net start mysql
关闭数据库;这里的mysql和启动时的mysql都是服务名(就是你安装时为mysql设置的,一般默认时mysql);
net stop mysql
用账号密码登录mysql;这个命令里面的mysql是命令,不是服务名;这里localhost是主机名(host),3306是端口号(port),root是用户(user),还有一个密码会在下一行单独输入,p就是它的简写(password);
mysql -h localhost -P 3306 -u root -p
显示数据库:之所以加分号,是因为现在已经到了mysql里面,本来是可以输入多行命令的,所以这个分号,意思就是说,你已经可以执行了;
show databases;
选中数据库,应该怎么选呢?
use library;
选中数据库之后就可以直接显示其中的表了;
show tables;
除了使用上面的方式显示一些指定数据库中的表,还可以使用如下命令显示(就像是下面语句,如果先运行了上面的use library,那么目前依旧处于library数据库,而非security数据库);
show tables from security;
如何查找当前属于哪个数据库,使用如下命令;
select database();
查看表结构
desc +表名;
退出使用exit命令;
3. MySQL的基础查询操作语句
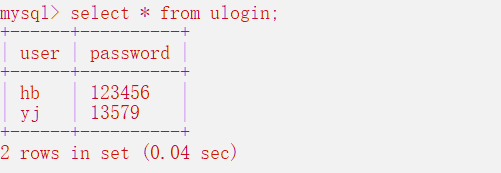
后面的所有语句暂时以上面的表作为依据;
-
基本查询:
select 属性 from 表名;使用的时候属性可以加上(``);(需要注意的是,查询的是一个虚拟的表格,所以并不会真的保存下来;)select `user`,`password` from ulogin;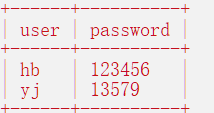
1.1. 为了查询到的数据更加清晰明了的显示,可以给不同的属性设置不同的名称
使用as进行设置(除此之外,as可以省略);select `user` as '用户名',`password` as '密码' FROM ulogin;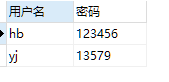
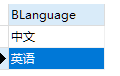
1.2. 去除重复查询到的数据,只保留单本;(这里以下面的表为例)

#可以去除重复的; SELECT distinct BLanguage from book;结果:
1.3. 在MySQL中进行属性的拼接,可以使用到关键词concat;需要注意的点是,如果拼接的字符中有某个属性为null,则拼接完之后的属性就是null;select concat(`user`,`password`) as "用户及密码" FROM ulogin;
-
条件查询基本语法:
Select 属性 from 表名 where 条件;select `password` from ulogin where `user`="hb";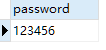
2.1常用的一些简单条件运算符>、<、=、不等于可以使用<>、>=、<=、like、between and、in、is null;逻辑运算符:and(且)、or(或)、not(非);#给出确定的,不确定的位置就使用%代替;中字前面也可以添加%(任意多个字符),只是这里没必要,因为它前面没有值,除了使用%,还有_(表示单个不确定的字符),; select `Bname` from book where `BLanguage` like '中%'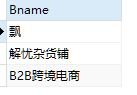
in的使用实例:#其实在这个in的括号里面,还可以添加一个sql的查询语句select; select `BName` from book where `BLanguage` in('英语','English%')在MySQL中如果某个值为空,你需要取这个值,不能直接使用where 属性=null(等于无法判断null),而应该写成where 属性 is null;IFNULL()用于判断属性是否为空,如果为空可以进行设置;如:IFNULL(属性,0),将为空的属性设置成0;
字段就是列;我这里的属性其实严格来讲叫字段; -
排序查询:通过order by和asc|desc等关键词来实现对查到的字段进行排序显示;其中
asc是升序(默认状态),desc是降序;
也可以进行多个字段的排序,如下只进行了一个字段的排序,还可以在其后添加,继续进行排序输出;比如还可以添加一个 price asc(按照价格升序),length(BName) desc(按名字字节降序)#括号里面可以有也可以没有 #select 查询字段 from 表 (where 条件) order by 排序列表 asc|desc; select BName,price from book ORDER BY price ASC; #上面的sql语句,同样可以由下面的语句替换(排序支持使用别名) select BName,price as 价格 from book ORDER BY 价格 ASC; #注意上面的价格(是指后面的第二个价格,不能使用单引号和双引号,其它的可以)不能使用单引号或者双引号修饰,它是别名;查询的结果:
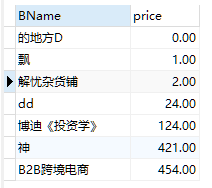
除此之外,还可以通过函数进行排序,但是前提是那个函数的结果可以用来比较(不管是比较字节,还是直接比较大小);
4.MySQL中已有的函数
4.1 单行函数:
concat():将一些字段拼接,遇到NUll字段,始终为空,字段之间使用","进行分隔;
length():得到一些字段的长度;
IFNULL(exp1,exp2):判断exp1是否为空,为空则取exp2设置的值;
upper():将字母全部转换为大写;
lower():将字母转换为小写;
substr():首先MySQL索引从1开始,指定的是字符长度,这里可以这样演示;例如:select SUBSTR(‘我的天啊’,2),2是指从哪个元素开始,包含这个元素;结果如下:
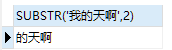
除此之外,substr还可以指明索引从哪个字符到达哪个字符,substr("wodt",1,2);结果是wo;如果只想截取一个字符,那就只需要取同一个字符索引就可以了;上面只想取“w”只需要在函数中将2换成1;
instr(exp1,exp2):用于返回exp2在字符串exp1中第一次出现的起始索引;
trim(exp1 from exp2):去除exp2中首尾含有exp1的字符串(只去掉首尾);
lpad(String exp1,int exp2, String exp3):用指定的exp3填充字符串exp1到达指定的长度exp2;
rpad():用法语lpad类似;
replace(exp1,exp2,exp3):替代函数;将字符串中的exp1中的exp2字符串替换成exp3字符串;
round():四舍五入;
ceil():向上取整;
floor():向下取整;
truncate(exp1,exp2):将数值exp1小数位取exp2位,如:truncate(1.33,1)=1.3;
now():返回当前系统的日期和时间;
curdate():返回当前的日期,不返回时间;
curdate():返回当前的时间,不返回日期;
------------------------------------------------------------------------------------------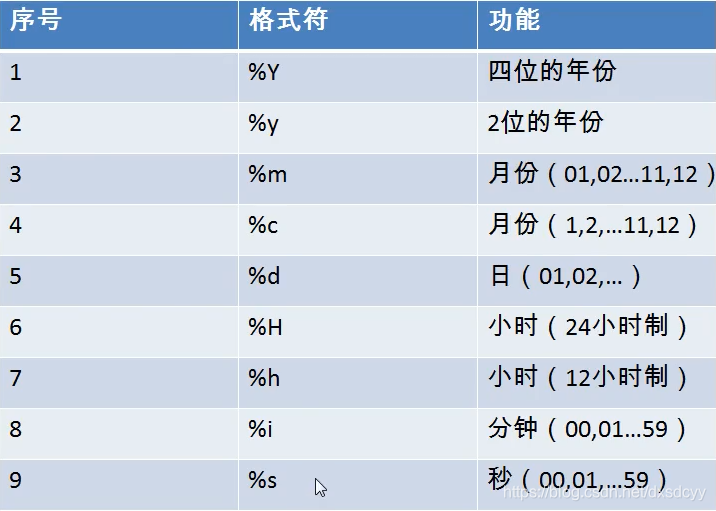
str_to_date(exp1,exp2):exp1是日期的字符串,exp2是自己设置的日期格式;例如:SELECT * FROMcontractwhere endtime in(str_to_date('7-4 2020','%c-%d %Y'));%y是年,%m是月,%d是日;当然既然是格式就不止这一种写法;
date_format( exp1,exp2):将日期转换为字符串; exp1为日期,exp2为转换的格式;也是按照上面的%Y,%m,%d(这三个分别代表年月日)进行格式转换;
if(exp1,exp2,exp3):就像是java的三元运算符,exp1是条件判断语句,如果条件成立,则输出exp2的结果,否则输出exp3的结果;
case:与Java中的switch.case类似,使用方法:
SELECT 字段
case 变量(即字段,但是不通过字符串列,我查了几遍发现查不出来,我的是MySQL5)
when 常量(像是条件一样) then 变化(比如某个字段的值进行修改等;)
...(可以放多个where)
else 变化(和面where都不一样的条件)
end as
FROM 表名
与if···else相似的判断,也是通过case实现:
SELECT 字段
case
when 条件比较(如price>100) then 变化(比如某个字段的值进行修改等;)
...(可以放多个where)
else 变化(和面where都不一样的条件)
end (as 自命名) (这里的as是用来为新创建的一列命名,当然也可以不给它单独命名,括号的意思就是可有可无)
FROM 表名
函数是可以嵌套使用的;
4.2 分组函数
用于统计;如:sun(),avg(),max(),min(),count();
在所有的分组函数中只是记录非空的条数; 而且可以与distinct关键词共同使用;例如:sun(distinct exp1),exp1是数值字段;
count()中加个常量值可以统计这个表的总行数(相当于新创建了一列单独用来统计);count(1):新创建一列字段,数据为1(这样表里面每一行都会有个1的数据,自然统计的就是所有的行);
4.3 group by的使用

下面需要演示的表
/*
基本语法
select 字段
from 表名
(where筛选条件)
group by 字段(通过什么字段分组,如下是通过BName分组)
(having 属于整体的筛选条件,那个表里面筛选不出来,如果表中可以筛选,直接写where里)
(order by 字段)(按照什么字段排序)
*/
SELECT avg(price),BLanguage
from book
group by BLanguage


注意: having 关键词后面的筛选语句可以通过and增加;
最后:
在MySQL5.5以前存储引擎是MYISAM ,内部含有计数器,可以直接返回个数;在MySQL5.5以后存储引擎是INNODB;
5. 连接查询

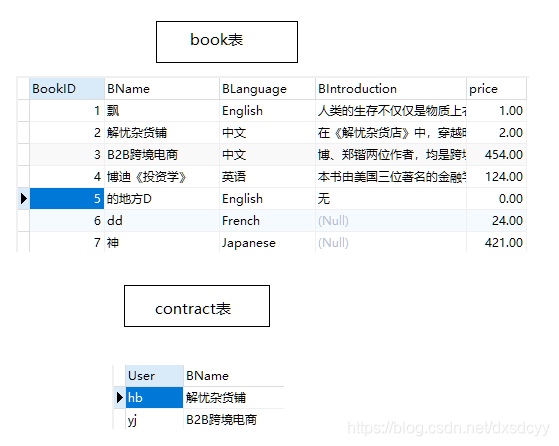
上面的表就是这里用来演示的表;
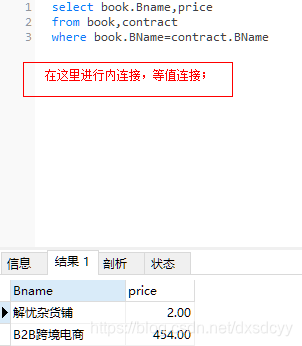
有时候如果表名比较长,在使用内连接的时候就很不方便,这是就可以给表起别名,但是起了别名就无法再用原来的基础名了,就必须全部使用表的别名;
非等值连接和等值连接相似,只不过是在进行筛选的时候将表达式变成<,>,<>等非等于符号;
5.1自连接:就是指在同一个表里面进行操作,进行的操作和等值连接类似;(区别就是一张表当两张表用);
5.2 连接查询
- 内连接
#基本语法
/*
select 需要字段
from 表1
连接类型【inner】 join 表2 ·····(1)
on 连接条件(是指两个表的连接条件,比如b.BName=c.BName之类的) ···(2)
(可能有多个表进行内连接,那么就需要多个(1)(2)语句)
【where筛选语句】
【group by 字段】
【having 字段】
【order by 字段】(和前面的区别不大,只是前面是sql92,这里是sql99)
*/
select b.Bname,price
from book b
join contract c
on b.BName=c.BName
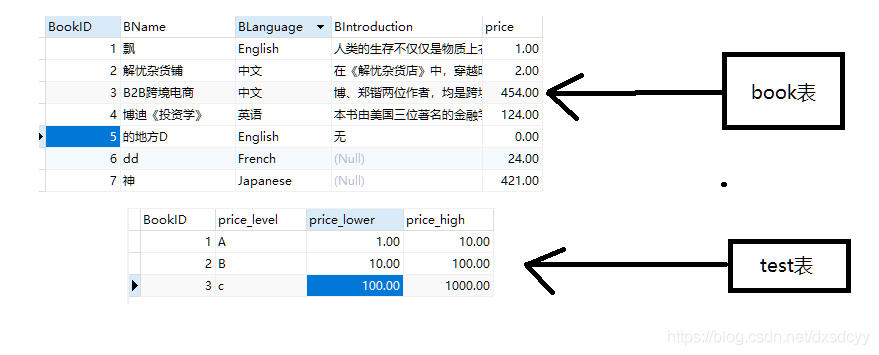
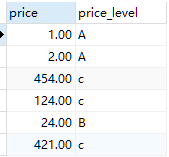
select price,price_level
from book
inner join test
#on price>price_lower and price<price_high可以用下面语句代替
on price between price_lower and price_high#(字段大小顺序不能错)
结果:
- 外连接

这里记录一下它的使用基本语法:
select b.BName,price,user
from book b#它是主表,起个别名
left outer join contract c#从表
on b.Bname=c.Bname
- 交叉连接(直接使用cross 0.join)
这个就是一个笛卡尔积,每一条数据都相互对应另一条数据;(比如表1有m行,表2有n行,则将两个表进行交叉连接的结果就是m*n行)
6.子查询
特点:
- 子查询放在小括号内;
- 一般出现在条件的右侧;
- 标量子查询(只有子查询只有一行,配合单行操作符使用<,>,>=,<=,=,<>)进行比较;
- 列子查询,搭配多行操作符使用;(in、any/some、all);
select *
from book
where Bname in(
select Bname from contract#这个就有多个结果属于列子查询
)
上面就是一个最简单的子查询;
一个稍重要的难点是可以通过子查询创建一个虚拟的表,并且这个虚拟的表可以直接用来配合查询自己需要的数据;如下记录:
/*
查询中文书籍的平均价格在test表中的价格等级
*/
select av_g,price_level
from(
select avg(price) av_g#平均价格的别名
from book
where BLanguage="中文"
) ag #这张新建的表的别名;将子查询的结果作为表,必须要一个别名,不然不方便使用,还会报错;
,test
where ag.av_g between price_lower and price_high
结果:

强调,当子查询在select后面时,只允许出现含有一列的查询,【select (select * from book)】像这种多列的查询会报错,也就是标量子查询;
6.1 分页查询
limit 关键词,基本使用limit offset(起始索引,从0开始),size(目录条数,大致就是指多少行);放在最后;当需要分页时可以用这个公式limit(page-1*size,size)
如下用book表简单的记录一下:
#基本语法
/*
select 需要字段
from 表1
连接类型【inner】 join 表2 ·····(1)
on 连接条件(是指两个表的连接条件,比如b.BName=c.BName之类的) ···(2)
(可能有多个表进行内连接,那么就需要多个(1)(2)语句)
【where筛选语句】
【group by 字段】
【having 字段】
【order by 字段】
limit offset,size;(放在最后)
*/
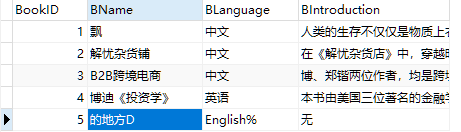
select *
from book
limit 1,2;
结果:(看结果中的编号就明白了)

6.2 联合查询(union)
将多条查询语句合并成一个结果;基本的语法就是使用union连接查询语句;
#需要注意的是,列的数目必须一致,否则报错;
#最好是相同的表,相同的列,不同的表和列好像不行(至少查到的东西不行,而且容易编码混乱);
#union关键词默认除重,就像是自带distinct;
#当然不同的表,但是显示的列是同类型的也是可以的;
#比如,下面虽然是不同的表,但是查询的列是类似的;
select BName from book where BLanguage="English"
union【all】#(all可以显示所有的行,而不会主动除重)
select BName from contract where user="hb";
Java杂记
1.在MySQL中存在转义,比如%等等
#第一种转义方式,第一个%代表任意的未知字符,第二个% 已经被\转义,就是普通的%;
select `Bname` from book where `BLanguage` like '%\%'
#第二种方式:使用escape关键词,自己设置转义符号;
select `Bname` from book where `BLanguage` like '%a%' escape 'a'
2.在使用MySQL进行查询时,如果条件中含有中文,则必须要用双引号(或单引号)引起来,例如:
select avg(price) from book where `BLanguage`='中文'
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











