








文章目录
进程相关概念
什么是进程?
关于什么是进程这个问题, 一般都会用一句简单的话来回答:运行起来的程序就是进程
这句话不能说是错的, 但也不全对。如果运行起来的程序就是进程, 那么进程和程序又有什么区别呢?
当一个程序运行起来的时候, 此程序会被加载到内存中, 那么进程与程序的区别 就只是 是否被加载到内存中吗?很显然并不是这样的.
其实 运行起来的程序就是进程, 这句话并不准确。
事实上, 操作系统中的一个进程 除了包含运行起来的程序之外, 还存在一个包含此进程所有属性数据的数据结构, 这两者结合, 才足够被称为是一个进程
也就是说, 进程 = 运行的程序 + 属性数据结构
而这个包含着进程所有的属性数据的数据结构, 通常被称为 PCB
进程的属性:PCB
PCB 即 Process Control Block, 意为 进程控制块 (并不是PCB板的PCB)
PCB 是集合了进程所有属性的一个集合, 是一种数据结构。当一个程序被运行时, 操作系统会自动生成一个PCB 并与程序结合 作为一个进程加载到内存中
Linux系统中的PCB, 叫 struct task_struct{}是一个结构体
Linux中的PCB
PCB是一个统称, 不同的操作系统中一般存在不同的具体的PCB, 而Linux系统中的PCB具体是一个结构体——struct task_struct{}
此结构体描述了进程的所有属性, 在Linux2.6内核中, 关于此结构体的代码超过300行:

此结构体所包含的进程的属性包括:
- 进程标识符
- 进程状态
- 进程优先级
- 内存指针
- 上下文数据
- I/O状态信息
- …………
基本上包含了此进程的所有属性
Linux进程
* 系统调用
在实际介绍Linux中关于进程的操作之前, 需要先介绍一个名词:系统调用
什么是系统调用?
用一个简单的例子来类比一下操作系统:银行
仔细思考银行的服务体系其实可以发现, 银行其实是一个封闭的体系。银行为了安全着想, 无论我们去银行办理什么业务, 一定是通过银行指定的业务窗口进行办理, 而不是自己直接动手操作办理。通过服务窗口, 客户可以办理其能办理的任何业务
操作系统也是一样的。为了安全着想, 操作系统不会将自己的底层直接交给用户操作, 而是通过给用户提供接口的方式给用户提供服务的。
这样由操作系统给用户提供的操作接口, 就被称为 系统调用
而 Linux系统的内核是用C语言写的, Linux的系统调用本质上其实是C语言的函数调用
Linux进程查看
了解了什么是进程之后, 那么在Linux系统中, 该如何查看进程呢?
1. ps
ps是Linux提供的指令, 使用 man ps的指令可以看到:
ps后还可以使用各种选项, 具体可以在系统中查看
当使用ps ajx时:

系统会以指定的格式 将当前的进程显示出来
并且, 当我们自己的程序正在运行时, 我们还可以使用ps将其找出来:
#include <iostream>
#include <unistd.h>
using std::cout;
using std::end;
int main() {
while() {
cout << "I am a Process" << endl;
sleep(1);
}
return 0;
}
将上述代码使用g++编译生成名为 AMProcess的可执行程序, 并执行此程序, 然后使用ps ajx | grep "AMProcess"搜索进程:
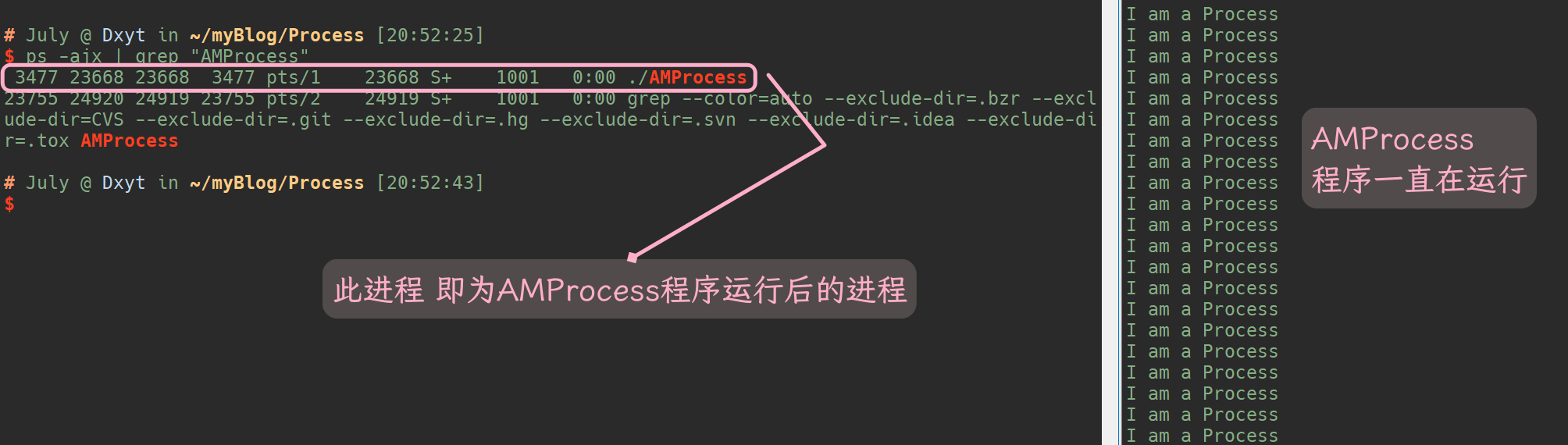
可以看到, 我们自己编写的程序运行起来, 可以在系统中找到其进程(暂时忽略前面的数字)
使用
ps ajx | grep "AMProcess"指令之后, 可以看到第一个进程就是我们程序的进程, 那么第二个相关的进程是什么呢?我们自己编写的程序运行之后, 加载到内存中成为了一个进程
在查找进程时, 我们使用了 grep指令来查找与AMProcess相关, 而grep其实也是一个程序, 使用grep 即 将grep运行了此时grep也就加载到内存中成为了一个程序, 此时grep又是用来查找AMProcess相关的, 所以进程中的 grep进程包含一个AMProcess关键词
当 再次基础上 使用
| grep -v grep排除 grep相关进程之后:
可以发现, 此时ps展示的只有 AMProcess程序运行之后成为的进程
2. 进入/proc路径
Linux系统中, 存在一个实时维护进程的路径, 即 /proc路径。此目录在 /路径下
进入 /proc路径 查看此路径下的文件, 可以看到 一堆数字名称的目录
这些目录就是此刻系统中存在的进程
那么这些数字是什么意思呢?其实, 这些数字是进程的 PID
当前路径
当我们创建一个进程, 并进入此进程数字目录之后, 可以看到目录下的文件:

可以看到, /proc目录下的表示一个进程的目录下存在着许多的文件, 其中有两个文件是当前我们可以理解的:
-
exe, 此文件表示了此进程的可执行文件的所在路径 -
cwd, 此文件则表示了此进程当前所运行的路径, 简称为当前路径(此当前路径与目录的当前路径不同)即,
当前路径其实是指此进程所运行的路径, 而不是可执行程序的路径
当我不结束此进程的运行, 并将 a.out 文件移动到其他位置时, 再查看proc目录下表示此进程的目录下的cwd和exe文件时:

PID 和 PPID
PID
Linux系统中, 每一个进程都存在一个唯一的标识符, 此标识符叫 Process ID, 简称PID. 每个进程的PID是唯一的, 用来表示此进程, 就像每个人都有一个全国唯一的身份证号一样
那么该怎么知道每个进程所对应的PID是什么呢?我们编写的程序, 其进程的PID又是什么呢?
进程的PID 也可以用ps查看
上面使用 ps 查看系统进程时, 可以看到每个进程占了1-2行来表示, 前面有数字, 后面有时间等, 但是并不知道具体是什么
如果想要知道的话, 只需要使用 ps ajx | head 将头栏显示出来, 就可以知道哪一栏是进程的PID了:
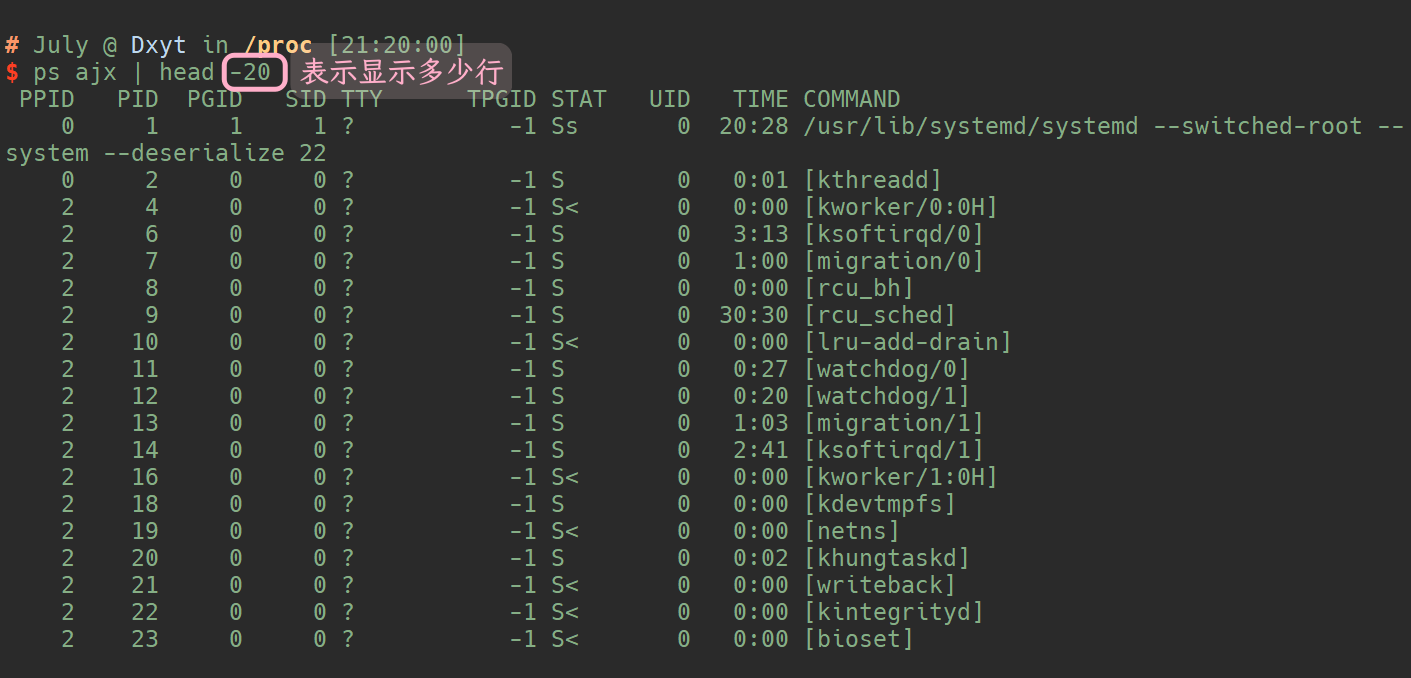
所以, 其实使用 ps ajx 查看系统进程的时候, 第2列 就表示进程的 PID
所以 我们编写程序的进程 的PID, 也可以以此查看(ps ajx | head -1 && ps ajx | grep "AMProcess" | grep -v grep):

可以看到 ./AMProcess进程的 PID是23668, 这个数字也可以在 /proc路径下找到:
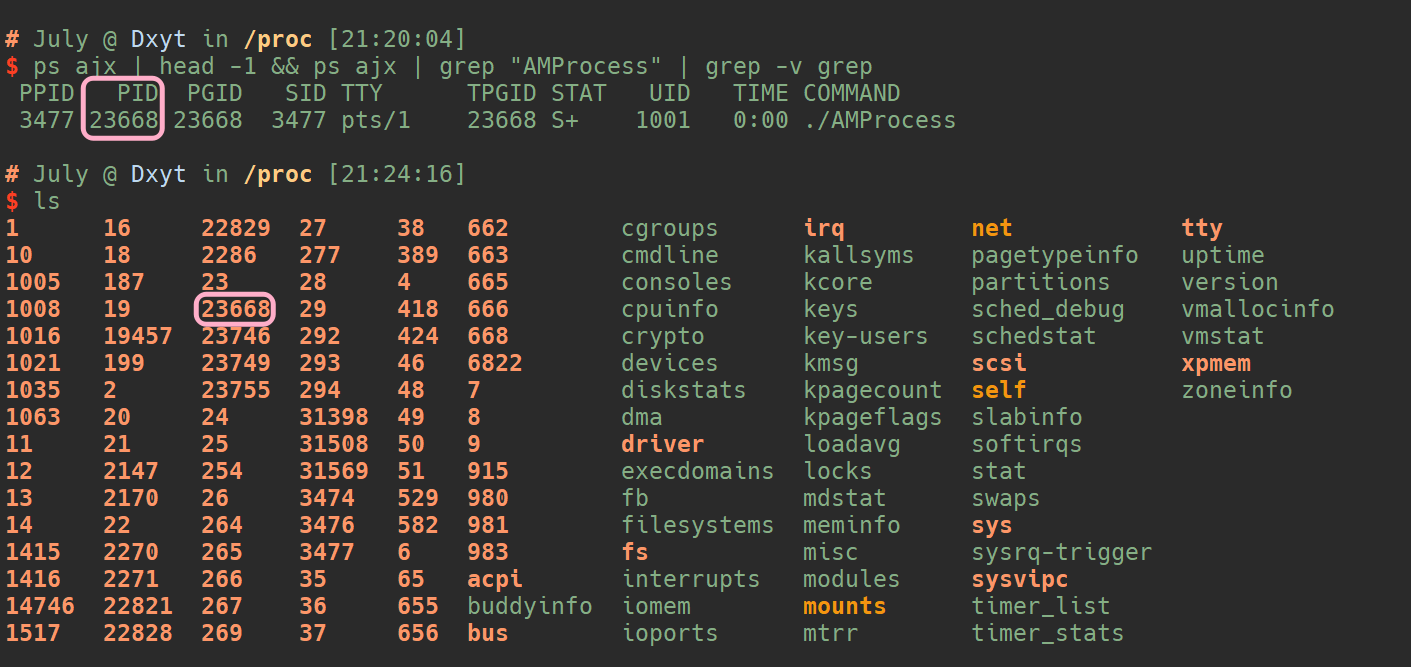
进入 23668 这个路径, 可以看到 此路径即为 维护./AMProcess进程的路径:

如果, 还是不能确定的话 可以使用 kill指令, 将23668进程kill掉:

AMProcess进程被kill掉, 当再次运行AMProcess程序时:


发现, 此程序在系统中的进程的PID已经不再是 23668, 而是 5359, /proc 路径下也没有了 23668, 却有 5359
这表明, 每次运行相同的程序而生成的进程的PID是不固定的
getpid() 获取PID
除了使用 ps ajx | head 指令获取头栏 然后得出PID的方法之外, Linux提供了系统调用可以在程序中得到PID
即 getpid()系统调用:

查看系统调用可以用 man 2或3 系统调用 指令来查看, 但是在使用 man 2或3 之前, 需要安装 man-pages
CentOS 下的指令是
sudo yum install man-pages
此系统调用可以直接在程序中使用:

此时, 编译运行程序:
可以输出此程序的PID, 使用kill指令进行验证:

PPID
PID 是 Process ID, 表示进程的标识符。PPID 又是什么意思呢?
PPID 其实是 Parent Process ID, 即 父进程的PID
顾名思义, 一个进程的PPID, 其实就是此进程的父进程的PID。
在使用 ps ajx | head 指令查看系统进程时, 第一列数据就是PPID, 第二列数据才是PID:

getppid() 获取PPID
与 getpid()一样, getppid() 也是Linux提供的系统调用

同样可以在程序中使用:

并打印出来:

父进程 与 子进程
既然存在PPID(Parent Process ID), 那么也就说明其实进程之间是存在父子关系的
我们自己编写的c++程序也存在父进程
在这个例子中, ./AMProcess进程的父进程是28528号进程
如果不小心将此进程结束了, 再次运行此程序:
可以发现, 无论重新运行程序多少次, 生成进程之后PID会发生变化, 但是PPID始终不变 恒为28528
这是为什么呢?这个28528进程究竟是什么呢?

在我这里, 28528进程是-zsh
如果没有更改过shell, 应该是-bash(刚使用Linux大概率没有更改)
这个-zsh(-bash)是什么呢?
其实 zsh 和 bash 都是一种shell, shell其实是泛指为所有用户提供操作界面的程序, 翻译为外壳(与之对应的就是内核)
shell可以分为
GUI(图形化界面) shell和CLI(命令行) shell而 zsh 和 bash 都属于
CLI shell,CLI shell其实就是用户输入指令的界面程序
既然 zsh 和 bash 都是用户输入指令的界面, 那也就不难理解为什么 ./AMProcess进程的父进程是 -zsh或-bash进程了
因为 ./AMProcess指令 就是通过 zsh或bash 提供的界面执行的
fork()创建子进程
我们使用 ./可执行程序 指令, 目的是运行程序创建一个进程
而我们知道, 进程是分父子的。那么可不可以创建一个由我们编写的程序作为父进程的一个进程(即创建一个子进程)呢?
答案当然是可以的, fork() 就是一种方法
fork()是Linux提供的系统调用:

通过man手册查看fork, 只看一小部分 仿佛fork()只是一个简单的返回pid_t类型数据的函数
那么fork()究竟返回什么呢?

man手册中, 关于fork()的返回值是这样描述的:
如果创建成功, 则返回子进程的PID给父进程, 还要返回 0 给子进程;如果创建失败, 则返回 -1 给父进程, 没有子进程被创建, 并且设置errno(用于异常接收)
!看手册的意思是, fork()将会返回两个返回值, 可是C语言函数应该是没有办法返回两个返回值的。这是什么情况?
这个问题, 暂时不解释, 先来看看 fork()该如何使用:
#include <iostream>
#include <unistd.h>
using std::cout;
using std::endl;
int main() {
pid_t id = fork(); //直接接收fork()的返回值
cout << "Hello, id = " << id << endl;
return 0;
}
将代码编译为CreatCProcess可执行程序, 并运行:
可以惊奇的发现, 居然输出了两次, 并且输出内容不同, 而源文件中只存在一个输出语句。
这又是为什么?为什么一个输出语句执行了两次?为什么fork()可以返回两个返回值?为什么一个id变量可以接收两个不同的返回值?
这三个问题, 我们一一来解释:
1. 为什么一个输出语句执行了两次
答案其实就藏在man手册关于fork()的解释中:

我们都知道, 一个程序应该是有内容的, 当程序被加载到内存中成为了进程, 程序的内容也就被加载到了内存中
而使用 fork()系统调用时, 我们并没有指定子进程的内容, 那么通过fork()创建的子进程就没有内容吗?
其实, 通过fork()创建的子进程的内容, 是从父进程中继承过来的, 其实就是复制使用了父进程中fork()系统调用之后的所有代码
然后将复制使用的代码作为程序运行, 加载到内存中, 也就将子进程添加到了进程的运行队列中
什么是运行队列?
其实系统中所有的进程可以看成排列在一个队列中, 遵循先进先出的原则, 一一执行
当子进程被添加到运行队列中, 一般情况就是父进程先运行, 子进程再运行
也就是说 fork()结束之后, 父进程会接着运行之后的代码, 输出 Hello, id = 子进程标识符,
接着子进程开始运行, 同样运行从父进程中复制过来的fork()之后的代码, 再输出一次 Hello, id = 0, 然后子进程运行结束
这就是 程序中 fork()之后只有一个输出语句, 但是却输出了两句的原因
2. 为什么fork()可以返回两个返回值
在解释这个问题之前, 我们要明确另一个问题, 当一个函数即将返回一个返回值时 此函数的主体功能是否已经完成了?
只有回答了这个问题, 才能明白为什么fork()可以返回两个返回值
当一个函数即将返回一个返回值时, 说明什么?说明此函数的已经走到了结尾, 只需要返回一个返回值来说明函数执行的情况就好, 所以其实函数返回值一般是作为一个对函数执行结果的判断的功能, 而函数的主体功能代码已经执行完毕了无论是成功了还是失败了。
也就是说, 当函数即将返回一个返回值时, 此函数的需要实现的具体功能一般已经完成了。在fork()这个系统调用中也是一样的, fork()实际上是用C语言所写的一个函数。
在一个程序中调用了fork(), 且此程序已经运行成为了一个进程, 那么在此进程运行至fork()即将返回一个返回值时, 其实此进程的子进程已经被创建完成了, 否则根本无法获取并返回子进程的标识符
在上边我们提到, 子进程所运行的程序代码可以看作是从父进程程序代码中fork()之后的部分复制过来的
那么, 依旧以此例来说明:
#include <iostream>
#include <unistd.h>
using std::cout;
using std::endl;
int main() {
pid_t id = fork(); //直接接收fork()的返回值
cout << "Hello, id = " << id << endl;
return 0;
}
当此程序运行起来时, fork()执行完毕, 此时子进程创建完毕 其相关程序代码就应该是:
#include <iostream>
#include <unistd.h>
using std::cout;
using std::endl;
int main() {
pid_t id = 0;
cout << "Hello, id = " << id << endl;
return 0;
}
在父进程运行结束之后, 子进程会接着运行至结束, 此时就可以做到 先输出 Hello, id = 子进程标识符, 在输出 Hello, id = 0
















 24万+
24万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











