







 这篇笔记探讨了神经网络中利用链式法则求解隐层误差梯度的问题。从链式求导法则出发,详细介绍了如何计算隐层误差的偏导数和梯度,旨在简化复杂的求解过程。
这篇笔记探讨了神经网络中利用链式法则求解隐层误差梯度的问题。从链式求导法则出发,详细介绍了如何计算隐层误差的偏导数和梯度,旨在简化复杂的求解过程。
上一章我们讨论了求输出层激励的梯度和输出层预激励的梯度的方法,可以发现,求解过程极其复杂,本章将从链式法则入手,推导出各隐层的参数梯度的一般形式。
一、链式求导法则
回顾高数的知识,若一个函数可写成若干个中间结果,即 p(a)=p(q1(a),...qi(a),...,qn(a)) ,则有
∂p(a)∂a=∑i∂p(a)∂qi(a)∂qi(a)∂a
即所谓“连线相乘,分线相加”。
为了求隐层参数梯度,可以令:
| 参数 | 含义 |
|---|---|
| a | 某隐层中的某个单元 |
|
|
上一个隐层的预激励 |
| p(a) | 误差函数 |
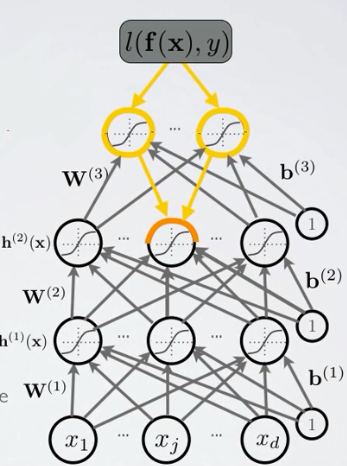
如上图所示,对于第2个隐层的第 j 个单元,按照上述对应关系,我们有:
| 参数 | 此处对应的元素 |
|---|---|
二、隐层误差梯度1.隐层误差偏导对于第 k 个隐层的第
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









