







 本文探讨了多层神经网络的容量问题,通过示例解释了如何通过增加隐藏单元来创建复杂的非线性决策边界。接着,介绍了神经网络训练的基础,包括经验风险最小化(ERM)和随机梯度下降(SGD)算法,强调了正规化项在防止过拟合中的作用,并概述了训练过程的主要步骤。
本文探讨了多层神经网络的容量问题,通过示例解释了如何通过增加隐藏单元来创建复杂的非线性决策边界。接着,介绍了神经网络训练的基础,包括经验风险最小化(ERM)和随机梯度下降(SGD)算法,强调了正规化项在防止过拟合中的作用,并概述了训练过程的主要步骤。
上一章主要讨论了单个神经元的容量问题,本章将着重讨论多层神经网络的容量和训练问题。
一、多层神经网络的容量问题
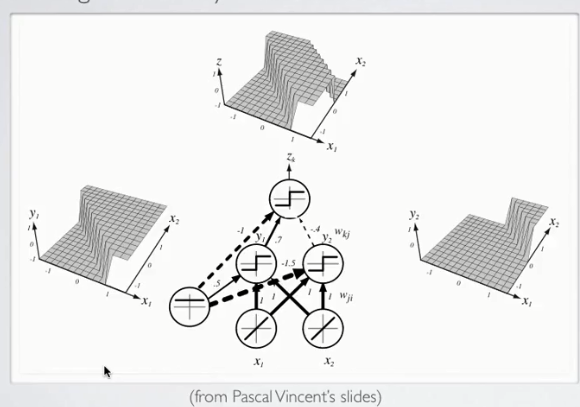
如图是一个具有两个隐藏单元的单隐层神经网络,左网格图是左侧隐层神经元的输出激励,右侧网格图是右侧隐层神经元的输出激励,则最终的输出激励是二者的叠加(至于是求和还是做差,取决于连接权值的选取,在本例中,是做差的过程)
如果我们增加隐层神经元个数,我们可以得到更为复杂的输出激励:
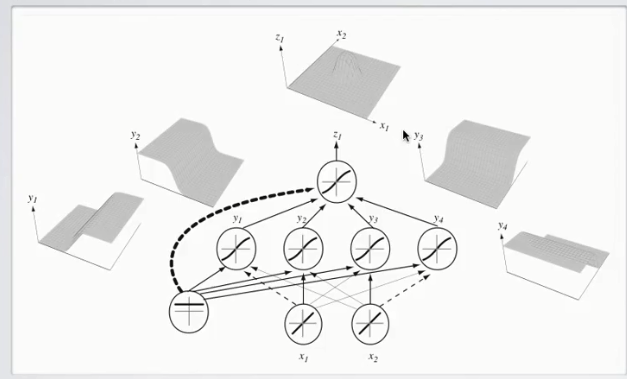
这里,我们总共有四个隐层神经元,这四个简单的线性分类器叠加后,就可以产生更为复杂的、高度非线性的决策边界。
这里直接给出描述神经网络容量问题的Universal Approximation定理(Hornike,2001):
只要给定足够多的隐藏单元,一个带线性输出单元的单隐层神经网络可以模拟出一切连续函数
以上结论可以推广至采用Sigmoid激励函数和Hyperbolic Tangent激励函数的情形。
二、神经网络训练概述
上面我们只是谈到了神经网络的表示问题和容量问题,我们知道选择正确的参数
w
和
1.Empirical Risk Minimization
经验风险最小化(Empirical Risk Minimization)是设计学习算法的一个框架,它可以将训练神经网络这一抽象问题转化成为一个求某个目标函数最小值的具体优化问题。其目标函数定义如下:
分析目标函数,可知目标函数由以下几个部分组成:
- 误差函数均值 1T∑tl(f(x(t);θ),y(t))
- 正规化项 Ω(θ)
- 平衡权重 λ
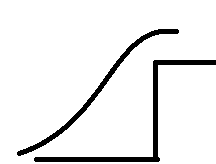
理想状况下,我们应该直接对分类误差进行优化,但往往分类误差不是光滑的,这就导致在某些点上函数是不可导的,这对我们后续学习算法的设计是很不利的。因此,我们引入误差函数
l(f(x(t);θ),y(t))
作为分类误差的代替,写入优化目标。一般误差函数是实际分类误差的上界,如图:
正规化项 Ω(θ) 的作用是对 θ 进行惩罚,防止过拟合(Overfitting)现象的产生,而参数 λ 则控制了在目标函数中,误差函数均值和正规化项之间的平衡。若 λ 过大,则可能导致欠拟合(Underfitting),训练效果较差;若 λ 过小,则可能导致过拟合,泛化效果较差。
2.Stochastic Gradient Descent
随机梯度下降是一个经典的神经网络学习算法,其主要思想是向目标函数梯度的反方向调整参数大小,从而实现对数据的拟合。
其主要步骤如下:
- 初始化各个参数 θ , θ={w(1),b(1),...,w(L+1),b(L+1)}
- 循环
N
次
- 对于每一个训练样本
(x(t),y(t)) - 求目标函数的反梯度方向,即 Δ=−∇θl(f(x(t);θ),y(t))−λ∇θΩ(θ)
- 更新参数 θ←θ+αΔ
为了实现上述算法,我们需要:
- 误差函数 l(f(x(t);θ),y(t))
- 计算参数导数 ∇θl(f(x(t);θ),y(t)) 的方法
- 正规化项 Ω(θ) 及其导数
- 初始化个参数的方法
下一章将按顺序解决以上问题。
- 对于每一个训练样本















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









