







3 自定义的聚合函数
所谓“聚合函数( Aggregate Function ) ”,其实就是对数据集合进行某种处理后得到的单一结果,比如统计一批数值型数据的平均值、最大值、最小值等。在 PLINQ 中,我们可以使用 ParallelEnumerable 类的扩展方法 Aggregate() 自定义一个聚合函数。
ParallelEnumerable. Aggregate() 有好几个重载形式,我们来看一个最复杂的:
public static TResult Aggregate<TSource, TAccumulate, TResult>(
this ParallelQuery<TSource> source, // 指明此扩展方法适用的数据类型
TAccumulate seed, // 聚合变量的初始值
// 用于更新聚合变量的函数,此函数将对每个数据分区中的每个数据项调用一次
Func<TAccumulate, TSource, TAccumulate> updateAccumulatorFunc,
// 用于更新聚合变量的函数,此函数将对每个数据分区调用一次
Func<TAccumulate, TAccumulate, TAccumulate> combineAccumulatorsFunc,
// 用于获取最终结果的函数,在所有工作任务完成时调用
Func<TAccumulate, TResult> resultSelector
);
这个函数声明拥有 5 个参数,看上去有些吓人,但只要耐下心来分析一下,还是可以理解的。
首先,第一个参数的 this 关键字表明可以对任何一个 ParallelQuery<TSource> 类型的变量调用 Aggregate() 方法,请注意 ParallelEnumerable. AsParallel< TSource >() 方法的声明:
ParallelQuery<TSource> AsParallel<TSource>(
this IEnumerable<TSource> source);
这意味着任何一个实现了 IEnumerable<TSource> 接口的对象都可以很方便地转换为 ParallelQuery<TSource> 类型的对象。所以,我们可以使用以下公式来调用自定义聚合函数:
实现了 IEnumerable<TSource> 接口的对象 .AsParall<TSource>().Aggregate< U,T,V>(…);
另外,请牢记所有聚合函数返回单一值,因此,会有一个值在 Aggregate() 函数的剩余几个参数间“传递”,这个值不妨称之为“聚合变量 ”。聚合变量的类型由 Aggregate() 函数的类型参数 TAccumulate 指定。
Aggregate() 函数的第 2 个参数 Seed 给聚合变量指定一个初始值。
Aggregate() 函数的后面几个参数都是处理并修改聚合变量的。这里有一个背景知识:您必须知道 PLINQ 是如何执行查询的。
在 19.3.3 小节介绍 Parallel.For 和 Parallel.ForEach 时,曾介绍过数据“分区”的概念。不妨重述如下:
当有一批数据需要处理时,TPL 会将这些数据按照内置的分区算法(或者你可以自定义一个分区算法)将数据划分为多个不相交的子集,然后,从线程池中选择线程并行地处理这些数据子集,每个线程只负责处理一个数据子集。
回到针对“自定义聚合函数”的讨论中来,在这里, TPL 会将指定的数据处理函数应用于每个数据子集中的每个元素,然后,再把每个数据子集的处理结果(由“聚合变量”所保存)组合为最终的处理结果。
现在我们可以讨论 Aggregate() 函数的剩余几个参数的含义了。
Aggregate() 函数的第 3 个参数 updateAccumulatorFunc 用 于引用一个数据处理函数,针对每个数据分区中的每个数据项,此函数都会调用一次。请注意这个被多次调用的函数接收两个参数,一个是聚合变量,另一个则是数 据分区中的每个数据项,函数返回值将作为聚合变量的“新值”。另外,要注意对于每个数据分区都关联着一个不同的聚合变量,而对于每个数据分区而言,是以“ 串行”方式对每个数据项调用数据处理函数的,因此,在数据处理函数内部不需要给聚合变量加锁就可以安全地访问它。
当所有数据分区的数据处理工作完成以后,每个数据分区会产生一个结果,此结果由本分区关联的“聚合变量”保存,由此得到了另一个数据集合:
{ 分区 1 的处理结果,分区 2 的处理结果,……,分区 n 的处理结果 }
Aggregate() 函数的第 4 个参数 combineAccumulatorsFunc 引用另一个数据处理函数对此“数据集合”进行处理。此数据处理函数的第一个参数也是“聚合变量”,第二个参数代表上述数据集合中的每个数据项,此数据处理函数的返回值将成为“聚合变量”的新值。
现在开始介绍 Aggregate() 函数的最后一个参数 resultSelector ,同样地,此参数也引用一个数据处理函数,这个函数只有一个参数,其值就是前面两个数据处理函数被执行之后所得到的“聚合变量”的最终值。 resultSelector 引用的函数可以对这个“聚合变量”进行最后的“加工”,得到整个 Aggregate() 函数的最终处理结果。
相信上述文字可能会让读者“头大”了,通过一个实例可能更好理解。我们在第 19.3.2 节中介绍过使用 TPL 计算数据的总体方差,为方便起见,这里将求方差的公式重新列出:
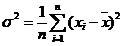
请看示例项目 UseAggregateFunc ,它使用聚合函数来计算方差,为简化起见,数据集合为 5 个随机生成的 1~10 间的整数。某次运行结果如下:
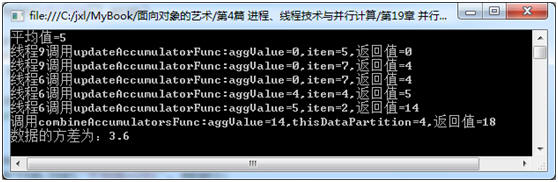
分析图 19 ‑ 22 ,我们可以发现:
TPL 将数据分为两个“区”,一个区包含 2 个数据,由线程 9 负责处理,另一个区包含 3 个数据,由线程 6 负责处理。
请注意每个线程刚开始执行时,聚合变量 aggValue 值都为初始值 0 ,每次执行数据处理函数 updateAccumulatorFunc 时,其返回值都成为 aggValue 的新值。
等每个分区数据处理完成时,得到一个新的“数据集合”,其成员为两个分区的“聚合变量”的当前值:
{14 , 4}
这时另一个数据处理函数 combineAccumulatorsFunc 被调用,将两个分区的处理结果累加起来。在示例中,只有两个数据分区,所以只需调用一次数据处理函数即可。如果有多个分区结果需要组合,此数据处理函数可能会调用多次。
以下列出这个示例程序中的聚合函数代码片断,请读者仔细阅读注释:
// 生成测试数据放到整型数组 source 中 ...( 代码略 )
// 计算平均值
double mean = source.AsParallel().Average();
Console.WriteLine(" 总体数据平均值 ={0}", mean);
// 并行执行的聚合函数
double VariantOfPopulation = source.AsParallel().Aggregate (
0.0, // 聚合变量初始值
// 针对每个分区的每个数据项调用此函数
(aggValue, item) => {
double result = aggValue + Math.Pow((item - mean), 2);
Console.WriteLine(……);
return result;
},
// 针对分区处理结果调用此函数
(aggValue, thisDataPartition) =>
{
double result = aggValue + thisDataPartition;
Console.WriteLine(……);
return result;
},
// 得到最终结果
(result) => result / source.Length
);
// 输出最终结果
Console.WriteLine(" 数据的方差为: {0}", VariantOfPopulation);
使用聚合函数比较繁琐,不易理解,但代码量较小,程序执行性能也不错,更关键的是它不需要考虑线程同步问题,还是比直接使用线程和 Task 更方便,因此,还是值得花费点时间弄明白它的用法。
4 中途取消 PLINQ 操作
PLINQ 采用统一线程取消模型来中途取消查询操作,只需在查询中使用 WithCancellation() 扩展方法就行了。
以下是示例代码:
CancellationTokenSource cs = new CancellationTokenSource();
// ……
var query=from data in DataSource.AsParallel().WithCancellation(cs.Token)
select data;
// ……
当 CancellationToken 置于 signaled 状态时 , PLINQ 会抛出一个 OperationCanceledException 异常 , 只需捕获此异常即可响应外界发出的 “取消”请求。
示例 PLINQCancel 展示了如何中途取消 PLINQ 操作,请读者自行阅读源代码。
提示:
由于PLINQ 在底层使用TPL ,所以,PLINQ 的异常处理机制与TPL 的一致。
19.4.3 深入探索 PLINQ
前面的章节已经对 PLINQ 编程做了介绍,本节我们来探讨一下 PLINQ 背后的运作机理,以便更好地使用 PLINQ 。
1 “自适应”的运行模式
如果代码中使用 AsParallel() 扩展方法将 LINQ 查询转换为 PLINQ ,在程序运行时, TPL 会自动分析此查询能否并行执行,如果可以,再考虑这种并行执行能否获得性能的提升,否则,仍然采用串行执行方式。这就是说:
PLINQ 查询并不一定以并行方式执行。
虽然 PLINQ 的设计者已经对很多种典型的场景进行了分析并且选择了相应的 PLINQ 查询运行模式,但不可能让 PLINQ 默认的方案适用于所有的场景,因此,如果你确信在任何情况下你的算法都是可以并行执行的,那么,你可以指定 PLINQ 不再进行分析而直接采用并行模式。
请看以下代码:
var parallelQuery = (from item in datasource.AsParallel()
.WithExecutionMode(ParallelExecutionMode.ForceParallelism )
select item;
上述代码使用 ParallelEnumerable.WithExecutionMode() 扩展方法强制以并行方式运行 PLINQ 查询。此方法接收一个 ParallelExecutionMode 枚举类型的参数用于指定执行模式。
2 设置工作线程数
默认情况下,到底使用多少个线程来执行 PLINQ 是在程序运行时由 TPL 决定的。但是,如果你需要限制执行 PLINQ 查询的线程数目(通常需要这么做的原因是有多个用户同时使用系统,为了服务器能同时服务尽可能多的用户,必须限制单个用户占用的系统资源),我们可以使用 ParallelEnumerable. WithDegreeOfParallelism() 扩展方法达到此目的。
请看以下示例代码:
var parallelQuery = from item in datasource.AsParallel()
.WithDegreeOfParallelism(4)
select item;
上述代码强制使用 4 个线程来执行 PLINQ 查询。
多懂一点:
设定执行并行循环的工作线程数
与PLINQ 类似,我们也可以设定执行并行循环的工作线程数。
在使用Parallel.For (或Parallel.ForEach )启动循环时,可以给其提供一个ParallelOptions 类型的参数,并指定其MaxDegreeOfParallelism 字段值。
ParallelOptions opt = new ParallelOptions();
opt.MaxDegreeOfParallelism = 4;
Parallel.For(0, 100, opt , (i) => Process(i));
上述代码中指定最多用4 个线程执行并行循环。
读者需要注意区分并行循环中使用的ParallelOptions.MaxDegreeOfParallelism 和PLINQ 中出现的WithDegreeOfParallelism() 扩展方法。
ParallelOptions.MaxDegreeOfParallelism 指明一个并行循环最多可以使用多少个线程。TPL 开始调度执行一个并行循环时,通常使用的是线程池中的线程,刚开始时, 如果线程池中的线程很忙, 那么, 可以为并行循环提供数量少一些的线程(但此数目至少为1 ,否则并行任务无法执行,必须阻塞等待)。等到线程池中的线程完成了一些工作, 则分配给此并行循环的线程数目就可以增加,从而提升整个任务完成的速度,但最多不会超过ParallelOptions.MaxDegreeOfParallelism 所指定的数目。
PLINQ 的WithDegreeOfParallelism() 则不一样,它必须明确地指出需要使用多少个线程来完成工作。当PLINQ 查询执行时,会马上分配指定数目的线程执行查询。
之所以PLINQ 不允许动态改变线程的数目,是因为许多PLINQ 查询是“级联[1] ”的,为保证得到正确的结果,必须同步参与的多个线程。如果线程数目不定,则要实现线程同步非常困难。
[1] 所谓“级联”,是指一个复杂的 PLINQ 查询可能包容多个的子查询,而这些子查询又可以包容它自己的子查询,从而形成一个多层嵌套的查询语句。
3 工作线程的数据提取策略
PLINQ 查询经常需要处理大量的数据,而这些处理工作是由线程执行的,为了实现并行处理,需要仔细考虑工作线程的数据存取方式。
方式一 :将所有数据全部装入到一个“临时”数组中,然后,将这个数组分成“几块”,交由不同的线程执行。
这种方式的优点是简单直观,可以实现高度的并行性,但缺点也是明显的:
( 1 ) 有可能需要使用巨大的内存空间。
( 2 ) 只有等数据全部装入完毕才能进行处理工作。
方式二 :根据需要提取数据。让所有的工作线程都共享同一个输入源,当某个线程需要访问数据时,它锁定此资源,取出数据,然后再释放锁。这实际上就是我们在第 17 章所介绍过“互斥”访问共享资源机制。这种方式也有几个缺陷:
( 1 ) 可能需要进行频繁的线程上下文切换,性能不好。
( 2 ) 无法对数据进行缓存,因为一次只从原始数据源中提取所需要的数据,而不能一次多提取一点“备用”。
( 3 )需要锁定共享资源,会导致程序性能受损。
方式三 :每次线程提取数据时都采用“批发”方式,比如一次提取 64 项。这就大大减少了锁定共享资源的需求。这个方法看上去不错,但仍有问题:
假设要处理的数据量很小(比如数据项数小于最小“批发数量” -64 项),但每个数据项要处理较长时间时,这个策略将导致事实上的“顺序”处理数据项,因为一个线程将所有“存货”都提取走了,其它线程都“无货可提”,导致“并行计算”有名无实。
方式四 :先将数据分区,为每个分区分配一个线程。每个线程第一次从所关联的分区中提取 1 项,第二次提取 2 项,第三次提取 4 项,……,第 n 次提取 2(n-1) 项。
这种策略综合了前述几个方式的优点,是当前版本的 PLINQ 默认采用的数据提取策略。
19.5 并行计算的应用实例
前面的章节已经对 .NET4.0 所 提供的并行扩展进行了详细介绍,读者一定对并行计算有了深刻的印象,并且您可能开始跃跃欲试地尝试在自己的开发实践中应用并行计算技术了。事实上,并行计 算是一个大趋势,拥有无限可能的应用前景。在本节中,我们通过一个应用实例介绍如何将并行计算应用于图像处理领域,然后再介绍一下 .NET 并行计算领域的未来发展。
19.5.1 图像处理——并行计算的应用实例
在计算机中显示的每张图像都由许多单个的像素构成,计算机图像处理通常可归结为对这些像素数据的算术操作。
组成彩色图像的每个像素的颜色通常都包含 R 、 G 、 B 三 个分量,通过修改特定像素的颜色,我们就实现了对图像的颜色变换。例如,如果把某张图像的所有像素的颜色值取反,我们就可以得到类似于“底片”的效果。我 们可以在计算机图形学领域找到许多图像变换公式,将这些公式施加于像素的颜色值,就可以实现许多图像处理特效(比如锐化、模糊、彩色图转为灰色图等)。许 多图像处理算法都是针对单个像素进行的,彼此之间相互独立,因此,在这个领域非常适合于应用“并行计算”来提升程序性能。
示例程序 MyImageProcessor 展示了一个简单的图像处理程序,它可以将一幅彩色图像反转为“底片”效果。
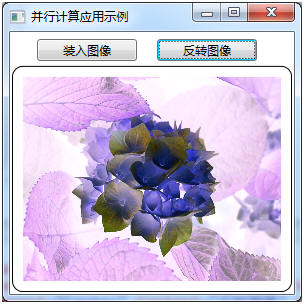
示例程序将图像的像素颜色数据装入到一个字节数组 ImagePixelData 中,然后,使用 Parallel.For() 方法对所有像素的颜色值取反,再显示到屏幕上,以下是实现并行图像处理的核心代码:
Parallel.For(0, ImagePixelData.Length, (i) =>
{
byte value = ImagePixelData[i];
ImagePixelData[i] = (byte)(~value);
});
有关此示例程序的技术关键点请看本节的“多懂一点”。
多懂一点:
示例程序MyImageProcessor 的学习指导
示例程序MyImageProcessor 是一个WPF 应用程序,下面简要介绍一下它的技术关键点。
在WPF 中,抽象类BitmapSource 类用于指代一个图像,其子类BitmapImage 代表一个“真实”的图像对象。
把图像文件路径字串作为参数,调用BitmapImage 的构造函数可以创建一个BitmapImage 对象。
在WPF 中,显示图像使用的是Image 控件,只需将它的Source 属性设置为一个BitmapSource 对象,它就能显示指定的图像, 参见以下代码
BitmapSource bmpSource = new BitmapImage(new Uri( 图像文件名 ));
image1.Source=bmpSource; // 显示图像
示例程序的关键之处在于如何从BitmapSource 对象中提取像素的颜色数据。这里需要了解一下计算机图像处理领域的基础知识。
每个图像都有一个以像素个数为单位的尺寸,比如我们常用于设置桌面背景的壁纸通常拥有1024*768 的尺寸,这个尺寸指的是“图像宽为1024 个像素,高为768 像素”。
对于不同类型的图像文件,很有可能每个像素所关联的数据量是不同的,比如有的图像使用3 个字节来保存像素颜色的R 、G 、B 三个分量,而有的则使用4 个字节来保存像素的颜色数据(在R 、G 、B 三个分量的基础上再加上一Alpha 值,用于表示颜色的透明度)。
幸运的是,通过BitmapImage 对象的Format.BitsPerPixel 属性我们可以知道每个像素占用的位数,将其除以8 就得到了单个像素所占用的字节数,而不需要编写代码处理各种类型的图像文件。
另一个知识点是需要知道图像每行像素数据的总字节数(这个数值在计算机图像处理领域被称为做位图图像的“stride ”值)。为了提升性能,通常要求这个数值能被4 整除,但图像文件不可能总满足这个要求,为此,有可能需要“补”上若干个字节以“凑”成一个可被4 整除的数。
在WPF 中,BitmapSource 类提供了一个CopyPixels() 方法可以将图像的像素数据复制到一个字节数组里,而另一个它的另一个Create() 方法可以从字节数组中重新提取数据创建一个新的BitmapSource 对象。
掌握了以上知识,就能看得懂示例程序中的代码了,以下是示例程序中的代码片断:
BitmapSource bmpSource=null;
int stride=0;
byte[] ImagePixelData=null;
// 装入图像的像素数据到字节数组中。
private void LoadImage(string ImagePath)
{
// 创建 BitmapSource 对象
bmpSource = new BitmapImage(new Uri(ImagePath));
// 计算图像的 stide 值
stride = bmpSource.PixelWidth * bmpSource.Format.BitsPerPixel / 8;
stride += 4-stride % 4; // 补上几个字节,使其可以被 4 整除
// 创建字节数组,注意其大小要合适,可以放得下所有的图像数据
int ImagePixelDataSize = stride * bmpSource.PixelHeight *
bmpSource.Format.BitsPerPixel / 8;
ImagePixelData = new byte[ImagePixelDataSize];
// 复制图像数据到字节数组中
bmpSource.CopyPixels(ImagePixelData, stride, 0);
}
其余的代码就很好懂了,请读者自行阅读示例源码。
19.6.2 并行计算的未来之路
当前计算机中普遍装备了“双核” CPU ,一些新购置的计算机更是装备了“四核” CPU ,随着 CPU 在“多核化”之路上越走越远,并行计算已成为软件技术确定无疑的发展方向。
与 CPU 多核化趋抛同时出现的是计算机网络的“无孔不入”,由此可知,分布式的软件系统也将成为软件技术发展的另一个方向,而分布式的软件系统“天生”就是“并行”的,因此, 未来的软件系统一定同时兼具有“并行”和“分布”两大特点 。
要开发并行的程序,可以利用 .NET 4.0 新加入的并行扩展;要开发分布式的软件系统,可以使用 .NET 4.0 中功能得到进一步增强的 WCF 。本书第 9 篇将详细 WCF 。
如果将本章介绍的并行计算技术与本书第 9 篇介绍的 WCF 技术结合起来,在微软平台之上,我们就拥有了前所未有的强有力的开发工具,可以用它来开发高度分布和高度并行的软件系统,解决更为复杂的问题,其应用前景非常广阔。
我们看到, .NET 4.0 已经在并行计算之路上迈出了第一步,而这一步一旦迈出,就不会停止下来。
并行计算的大幕刚刚拉开,精彩的剧目即将上演,让我们拭目以待吧!
















 146
146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









