







文章目录
任务4:7~8天
1.学习目标
1.1 散列表(哈希表)
实现一个基于链表法解决冲突问题的散列表
实现一个 LRU 缓存淘汰算法
1.2 字符串
实现一个字符集,只包含 a~z 这 26 个英文字母的 Trie 树
实现朴素的字符串匹配算法
1.3 对应的 LeetCode 练习题
哈希表
并完成leetcode上的两数之和(1)及Happy Number(202)!(要求全部用哈希思想实现!)
字符串
Reverse String (反转字符串)
英文版:Loading…
中文版:Loading…
Reverse Words in a String(翻转字符串里的单词)
英文版:Loading…
中文版:Loading…
String to Integer (atoi)(字符串转换整数 (atoi))
英文版:Loading…
中文版:Loading…
2. 学习内容
2.1 哈希表
定义:根据关键码值(key value)而进行访问的数据结构
通过把关键码值映射到表中的一个位置来访问记录,加快查找速度
散列函数/散列表
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后能得到包含该关键字的记录在表中的地址,则称M为哈希表,函数f(key)为哈希函数
哈希表查找的步骤
使用哈希函数:将被查找的键转化为数组的索引
除留余数法
直接地址法
数字分析法
平方取中法
折叠法
处理哈希碰撞冲突(开放寻址法、拉链法)
优点:时间和空间上的平衡
键值作为索引,查找的时间复杂度:O(1)
开放寻址法
如果有冲突发生,那么尝试选择另外的单元,直到找出空的单元为止
Hi=(H(key) + di) MOD m , i=1,2,…,k(k<=m-1)
di = 1,2,3,4…m-1,线性探测再散列
di = di = 12,-12,22,-22,32,…,±(k)^2,(k<=m/2),称二次探测再散列;
di = 伪随机数序列,称为随机探测再散列
拉链法(链表法)
2.1.1基于链表法解决冲突问题的散列表
class ListNode:
def __init__(self, key):
self.key = key
self.next = None
class HashMap:
def __init__(self, tableSize):
self.table = [None] * tableSize
self.n = 0 # n代表结点的数量
def __len__(self):
return self.n
def hash(self, key):
return abs(hash(key)) % len(self.table)
def __getitem__(self, key):
j = self.hash(key)
node = self.table[j]
while node is not None and node.key != key:
node = node.next
if node is None:
raise KeyError('KeyError' + repr(key))
return node
def insert(self, key):
try:
self[key]
except KeyError:
j = self.hash(key)
node = self.table[j]
self.table[j] = ListNode(key)
self.table[j].next = node
self.n += 1
def __delitem__(self, key):
j = self.hash(key)
node = self.table[j]
if node is not None:
if node is not None:
if node.key == key:
self.table[j] = node.next
self -= 1
else:
while node.next is not None:
pre = node
node = node.next
if node.key == key:
pre = node
node = node.next
if node.key == key:
pre.next = node.next
self.n -= 1
break
2.1.2 LRU缓存淘汰算法
LRU:淘汰掉最不经常使用的
核心思想:如果数据最近被访问过,那么将来被访问的几率也就越高
设计一个LRU缓存,使得放入和移除都是O(1)
为什么散列表和链表经常一起使用

class LRUCache:
# @param capacity, an integer
def __init__(self, capacity):
self.cache = {}
self.used_list = []
self.capacity = capacity
# @return an integer
def get(self, key):
if key in self.cache:
if key != self.used_list[-1]:
self.used_list.remove(key)
self.used_list.append(key)
return self.cache[key]
else:
return -1
# @param key, an integer
# @param value, an integer
# @return nothing
def set(self, key, value):
if key in self.cache:
self.used_list.remove(key)
elif len(self.cache) == self.capacity:
self.cache.pop(self.used_list.pop(0))
self.used_list.append(key)
self.cache[key] = value
2.2 字符串
2.2.1 实现一个字符集,只包含 a~z 这 26 个英文字母的 Trie 树
Trie树:字典树(N叉树),一种特殊的前缀树结构
利用字符串公共前缀降低搜索空间,速度为O(k),k为输入的字符串长度
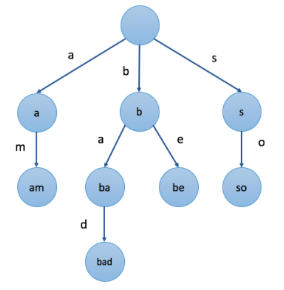
性质:
根节点不包含字符,除根结点以外的每个节点只包含一个字符
从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串
每个节点的所有子节点包含的字符串不相同
应用:
词频统计:比hash节省空间
搜索提示:输入前缀词的时候提示可以构成的词
作为辅助结构:如后缀树,AC自动机等辅助结构
只包含a~z的Trie树(字典树)
class Trie:
# word_end = -1
def __init__(self):
"""
Initialize your data structure here.
"""
self.root = {}
self.word_end = -1
def insert(self, word):
"""
Inserts a word into the trie.
:type word: str
:rtype: void
"""
curNode = self.root
for c in word:
if not c in curNode:
curNode[c] = {}
curNode = curNode[c]
curNode[self.word_end] = True
def search(self, word):
"""
Returns if the word is in the trie.
:type word: str
:rtype: bool
"""
curNode = self.root
for c in word:
if not c in curNode:
return False
curNode = curNode[c]
# Doesn't end here
if self.word_end not in curNode:
return False
return True
def startsWith(self, prefix):
"""
Returns if there is any word in the trie that starts with the given prefix.
:type prefix: str
:rtype: bool
"""
curNode = self.root
for c in prefix:
if not c in curNode:
return False
curNode = curNode[c]
return True
# Your Trie object will be instantiated and called as such:
# obj = Trie()
# obj.insert(word)
# param_2 = obj.search(word)
# param_3 = obj.startsWith(prefix)
朴素的字符串匹配算法
2.2.2 实现朴素的字符串匹配算法
朴素的字符串匹配算法
字符串匹配:
输入:原字符串和子串
输出:子串在原字符串中首次出现的位置
朴素算法(暴力搜索法)
预处理时间:O(0)
匹配时间复杂度:O(N*M)
主要过程:从原字符串开始搜索,若出现不能匹配,则从原搜索位置+1继续
KMP算法
def strMatching(s1, s2):
i, j = 0, 0
n, m = len(s1), len(s2)
while i < n and j < m:
if s1[i] == s2[j]:
i = i + 1
j = j + 1
else:
i = i - j + 1
j = 0
if j == m:
return i - j
return -1
2.3 对应的 LeetCode 练习题
2.3.1哈希表
两数之和(1)
def twoSum(nums, target):
map = {}
for i, num in enumerate(nums):
if target - num in map:
return map[target - num], i
else:
map[num] = i
Happy Number(202)
class Solution:
def isHappy(self, n):
"""
:type n: int
:rtype: bool
"""
record = {}
sq_sum = 0
while n != 1:
sq_sum = 0
sub_num = n
while sub_num > 0:
sq_sum += (sub_num % 10) * (sub_num % 10)
sub_num //= 10
if sq_sum in record:
return False
else:
record[sq_sum] = 1
n = sq_sum
return True
2.3.2 字符串
反转字符串
# 方法一:reverse()方法
s='helloword'
l=list(s)
l.reverse()
print("".join(l)) #把列表里的值拼接成一个字符串
# 方法二:使用栈
def func(s):
l = list(s) #模拟全部入栈
result = ""
while len(l)>0:
result += l.pop() #模拟出栈,pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
return result
r = func(s)
print(r)
# 方法三:递归函数
def func(s):
if len(s) <1:
return s
return func(s[1:])+s[0]
# 方法四 字符串切片的方法
s='helloword'
r=s[::-1]
print(r)
翻转字符串里的单词
def reverseWords(self, s: str) -> str:
list= s.split() # python 中字符串无法修改,要转为list
return ' '.join(list[::-1])# 将反转后的列表转为 str
字符串转换整数(atoi)
class Solution:
def myAtoi(self, str):
import re
pattern = r"[\s]*[+-]?[\d]+"
match = re.match(pattern, str)
if match:
res = int(match.group(0))
if res > 2 ** 31 - 1:
res = 2 ** 31 -1
if res < - 2 ** 31:
res = - 2 ** 31
else:
res = 0
return res















 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









