







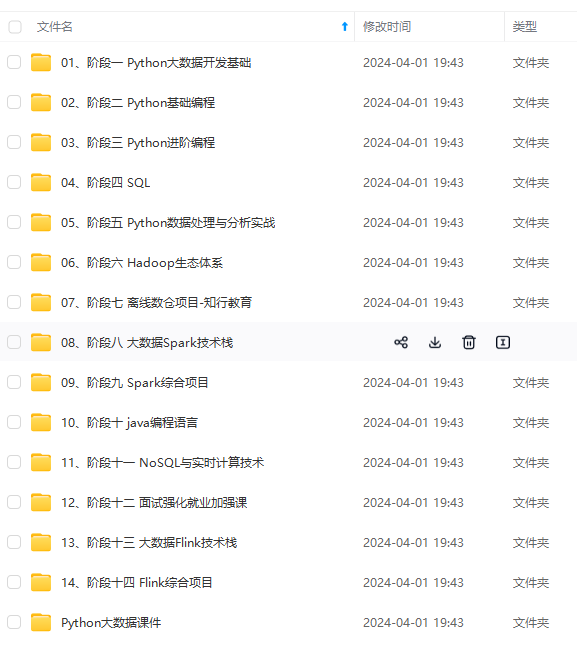
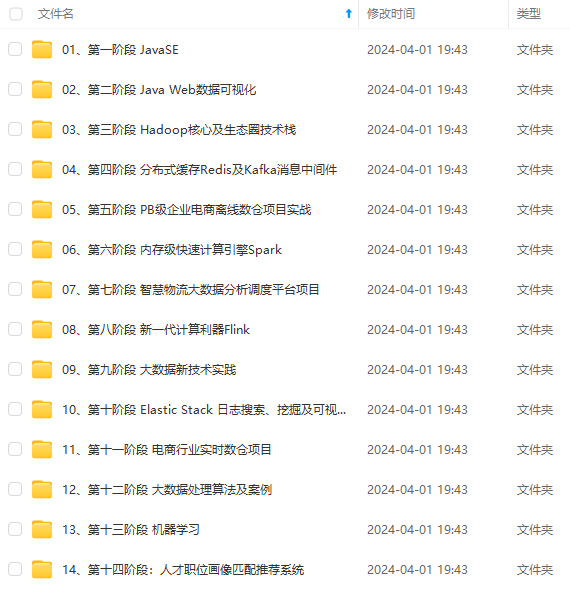
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
每天一道大厂SQL题【Day17】腾讯外包(微信相关)真题实战(二)
大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题,以每日1题的形式,带你过一遍热门SQL题并给出恰如其分的解答。
一路走来,随着问题加深,发现不会的也愈来愈多。但底气着实足了不少,相信不少朋友和我一样,日积月累才是最有效的学习方式!
每日语录
真正的勇士,敢于直面银行卡上的余额,敢于正视磅秤上的数字。
第17题:查询当天阅读最多的 100 篇文章
需求列表
第2题 查询当天阅读最多的 100 篇文章
上述结果上传 HIVE 表 t_log_clean ,字段分别为 ftime uid postid , 请计算 2020 年 1 月 1日 当天阅读最多的 100 篇文章
思路分析
- 筛选出指定日期的数据:我们可以使用 where 子句来过滤出 ftime 字段等于 ‘2020-01-01’ 的数据,这样就只保留了当天的日志记录。
- 统计每篇文章的阅读次数:我们可以使用 group by 子句和 count 函数来对 postid 字段进行分组和计数,这样就得到了每篇文章当天的阅读次数。
- 按照阅读次数降序排序:我们可以使用 order by 子句和 desc 关键字来对阅读次数进行降序排序,这样就把阅读最多的文章排在前面。
- 取出前 100 篇文章:我们可以使用 limit 子句和 100 参数来限制返回的结果集数量,这样就只保留了前 100 篇文章。
答案获取
建议你先动脑思考,动手写一写再对照看下答案,如果实在不懂可以点击下方卡片,回复:大厂sql 即可。
参考答案适用HQL,SparkSQL,FlinkSQL,即大数据组件,其他SQL需自行修改。
加技术群讨论
点击下方卡片关注 联系我进群

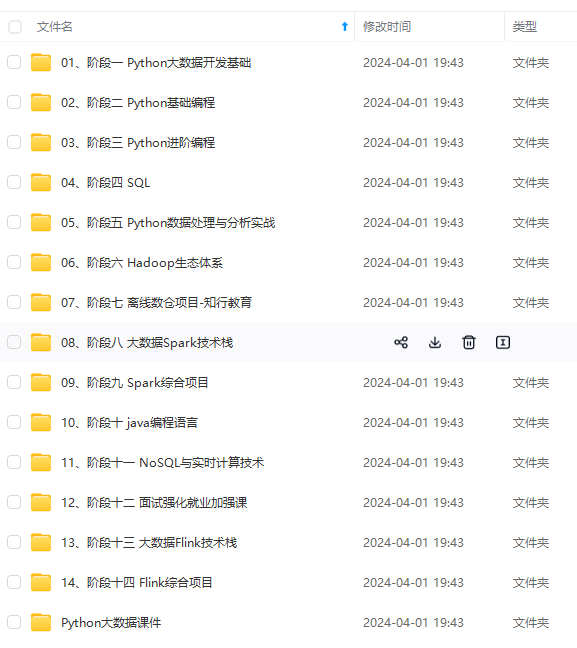
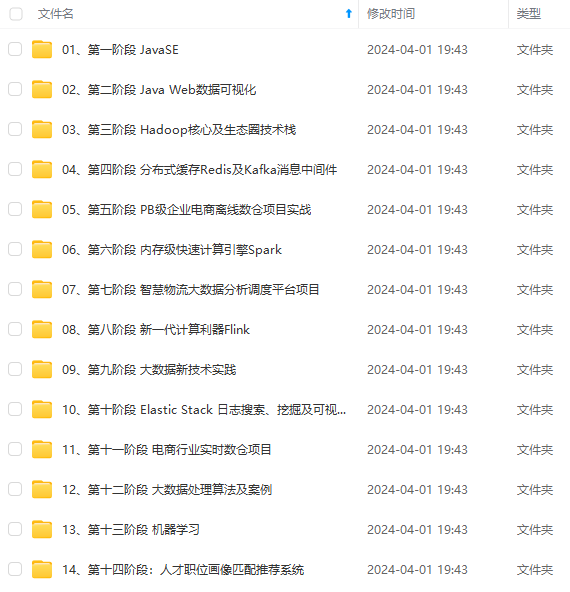
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
续更新**















 621
621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









