







 本文介绍了两种使用Java实现的爬虫方法,从酷安网抓取用户头像。方法一通过解析HTML,获取用户个人中心链接,然后下载头像;方法二则是遍历用户ID,正则匹配头像URL。涉及的库包括Jsoup用于解析HTML,HttpClient用于下载图片。
本文介绍了两种使用Java实现的爬虫方法,从酷安网抓取用户头像。方法一通过解析HTML,获取用户个人中心链接,然后下载头像;方法二则是遍历用户ID,正则匹配头像URL。涉及的库包括Jsoup用于解析HTML,HttpClient用于下载图片。
方法一:
爬虫思路
以酷安网用户粉丝较多的用户的个人中心为进口,获取该用户的全部粉丝的个人中心链接,用户头像链接和用户名,并分别放入队列。开启两个线程获取信息,一个线程获取队列中的用户的信息并放入队列,另一个线程负责从头像链接队列中取出链接并下载用户头像。
爬虫分析
用浏览器打开一个用户的粉丝列表(http://coolapk.com/u/[用户id]/contacts)
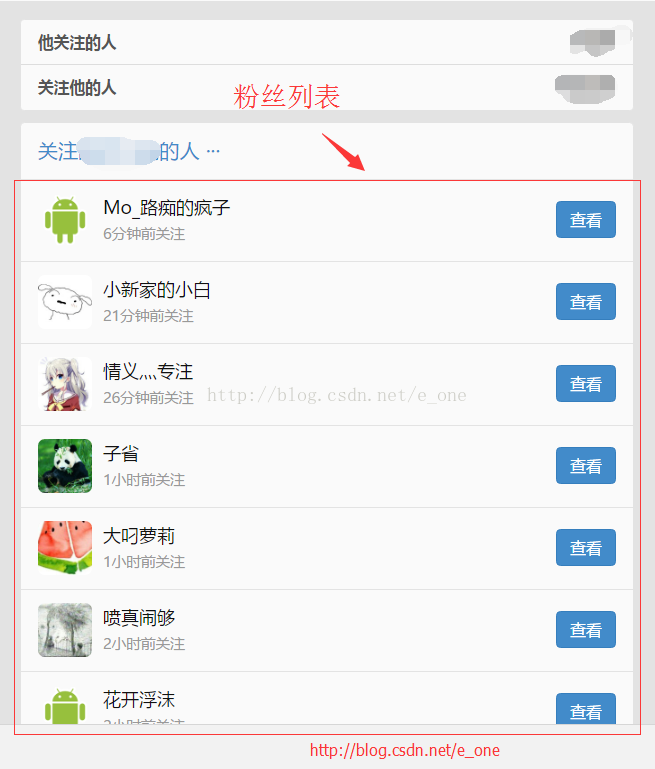
并查看源码

我们可以看到粉丝列表以HTML的ul标签显示,并且其id为dataList,ul标签中的各个li标签即为每一个用户的信息啦~再进一步分析,li标签中的img标签为用户头像。h4标签的内容即为用户名,h4标签中的a标签的href属性为用户的个人中心链接。
通过观察我们还知道:用户的粉丝列表链接=个人中心链接+ "/contacts"
这样我们就可以开始爬取头像了
用到的库
Jsoup:
作用:解析和操作HTML元素。下载地址:https://jsoup.org/download
HttpClient:
作用:下载图片。下载地址: http://hc.apache.org/downloads.cgi
代码
Main.java
package main;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class Main {
//浏览器UA
private static String UA="Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36";
//主机地址
private static final Strin 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









