









作者:有些代码不应该被忘记
原文链接:https://blog.csdn.net/scutjy2015/article/details/72810730
我们在学习使用深度学习的过程中最最重要的就是调参,而调参的能力是需要长期积累才能形成的,因为每一种数据库和每一种网络结构都需要不同的参数以达到最佳效果。而寻找这个最佳的参数的过程就叫做调参。
正文:
一. 参数是指那些?
参数其实是个比较泛化的称呼,因为它不仅仅包括一些数字的调整,它也包括了相关的网络结构的调整和一些函数的调整。下面列举一下各种参数:
1. 数据处理(或预处理)相关参数:
enrich data(丰富数据库),
feature normalization and scaling(数据泛化处理),
batch normalization(BN处理),
2. 训练过程与训练相关的参数:
momentum term(训练动量),
BGD, SGD, mini batch gradient descent(这里的理解可以看我之前的一篇博客:http://blog.csdn.net/qq_20259459/article/details/53943413 )。
number of epoch,
learning rate(学习率),
objective function(衰减函数),
weight initialization(权值初始化),
regularization(正则化相关方法),
3. 网络相关参数:
number of layers,
number of nodes,
number of filters,
classifier(分类器的选择),
二. 调参的目的以及会出现的问题
首先我们调参有两个直接的目的:1. 当网络出现训练错误的时候,我们自然需要调整参数。 2. 可以训练但是需要提高整个网络的训练准确度。
关于训练可能会出现的问题汇总:
1. 可能没法进行有效地训练,整个网络是错误的,完全不收敛(以下图片全部来源于我的实验,请勿盗用):
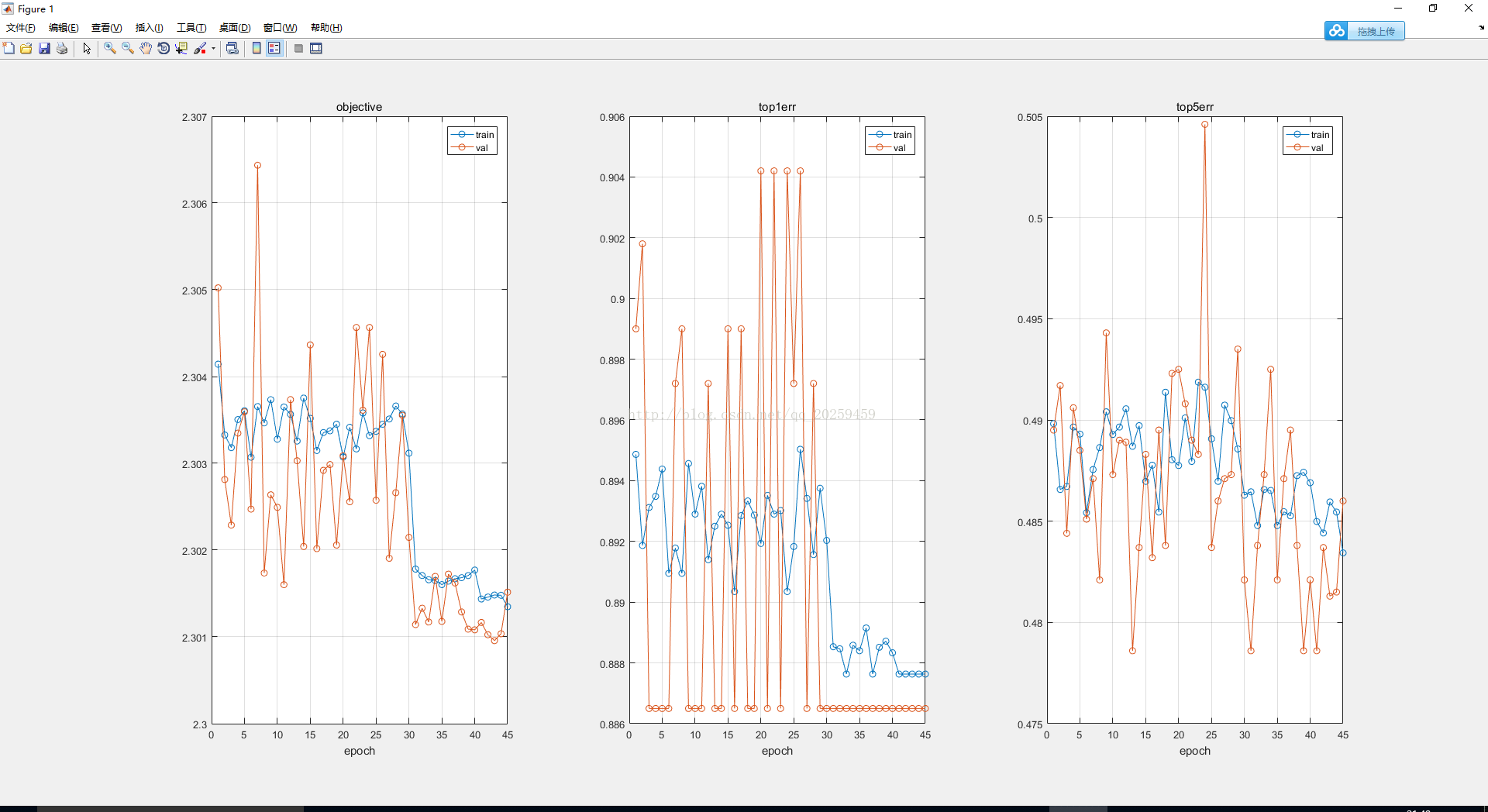
2. 部分收敛:

3. 全部收敛但是结果不好:

三. 问题分析理解
在深度学习领域我上面的三个例子可以说是比较全面的概括了问题的种类:完全不收敛,部分收敛,全部收敛但是误差大。
下面我们先进行问题分析,然后我再介绍如何具体调参:
1. 完全不收敛:
这种问题的出现可以判定两种原因:1,错误的input data,网络无法学习。 2,错误的网络,网络无法学习.
2. 部分收敛:
这种问题的出现是有多种多样的原因的,但是我们可以总结为:1,underfitting。 2, overfitting。
underfitting和overfitting在深度学习中是两个最最常见的现象,他们的本质是网络分类器的复杂度导致的。
一个过简单的分类器面对一个复杂的数据就会出现underfitting,举个例子:比如一个2类分类器他是无法实现XOR的问题的。
一个过复杂的分类器面对一个简单的数据就会出现overfitting。
说的更容易理解一点:
1.underfitting就是网络的分类太简单了没办法去分类,因为没办法分类就是没办法学到正确的知识。
2.overfitting就是网络的分类太复杂了以至于它可以学习数据中的每一个信息甚至是错误的信息他都可以学习。
如果我们放在实际运用中我们可以这样理解:
1.我们有两个数据A和B,是两个人的脸的不同环境下10张照片。A我们拿来进行训练,B则是用来测试,我们希望网络可以从A学习人脸的特征从而认识什么是人脸,然后再去判断B是不是人脸。
2.如果我们使用会导致underfitting的分类器时,这个网络在学习A的时候将根本学不到任何东西,我们本来希望它可以知道A是人脸,但是它却认为这是个汽车(把A分去不正确的label,错误的分类)。
3.而当我们使用会导致overfitting的分类器时,这个网络在学习A的时候不仅可以知道A是人脸,还认为只有A才是人脸,所以当它去判别B的时候它会认为B不是人脸(过度的学习了过于精确的信息导致无法判别其它数据)。
下面我们再用图来解释说明一下这两个问题:

以及用表格表示一下他们的训练结果:

3. 全部收敛:
这是个好的开始,接下来我们要做的就是微调一些参数。
四. 针对问题来调参
我在许多其他人的文章看过别人的调参方法的分享和心得,其中有许多人提出使用暴力调参和微调配合使用。这里我不是很同意这种观点,因为所谓的暴力调参就是无规律性的盲目的调整,同时调整多个参数,以寻找一个相对能收敛的结果,再进行微调。这种做法是一种拼运气的做法,运气好的话这个网络的深度和重要的参数是可以被你找到,运气不好的好你可能要花更多的时间去寻找什么是好的结果。而且最终即使有好的结果你自己本身也是不能确认是不是最好的结果。
所以再次我建议我们在调参的时候切忌心浮气躁,为了好的实验结果,我们必须一步一步的结果分析,解决问题。
下面我们谈谈如和调参:
现有的可调参数我已经在(一)中写出了,而这些参数其实有一些是现在大家默认选择的,比如激活函数我们现在基本上都是采用Relu,而momentum一般我们会选择0.9-0.95之间,weight decay我们一般会选择0.005, filter的个数为奇数,而dropout现在也是标配的存在。这些都是近年来论文中通用的数值,也是公认出好结果的搭配。所以这些参数我们就没有必要太多的调整。下面是我们需要注意和调整的参数。
1. 完全不收敛:
请检测自己的数据是否存在可以学习的信息,这个数据集中的数值是否泛化(防止过大或过小的数值破坏学习)。
如果是错误的数据则你需要去再次获得正确的数据,如果是数据的数值异常我们可以使用zscore函数来解决这个问题(参见我的博客: http://blog.csdn.net/qq_20259459/article/details/59515182 )。
如果是网络的错误,则希望调整网络,包括:网络深度,非线性程度,分类器的种类等等。
2. 部分收敛:
underfitting:
增加网络的复杂度(深度),
降低learning rate,
优化数据集,
增加网络的非线性度(ReLu),
采用batch normalization,
overfitting:
丰富数据,
增加网络的稀疏度,
降低网络的复杂度(深度),
L1 regularization,
L2 regulariztion,
添加Dropout,
Early stopping,
适当降低Learning rate,
适当减少epoch的次数,
3. 全部收敛:
调整方法就是保持其他参数不变,只调整一个参数。这里需要调整的参数会有:
learning rate,
minibatch size,
epoch,
filter size,
number of filter,(这里参见我前面两篇博客的相关filter的说明)
五. 大的思路和现在的发展
其实我们知道现在有许多的成功的网络,比如VGGNet和GoogleNet,这两个就是很划时代的成功。我们也由此可以发现网络设计或者说网络调参的主方向其实只有两种:1. 更深层的网络, 2. 更加的复杂的结构。
我们可以参见下面图片以比较几个成功网络的独特之处:
1. AlexNet(深度学习划时代的成功设计):
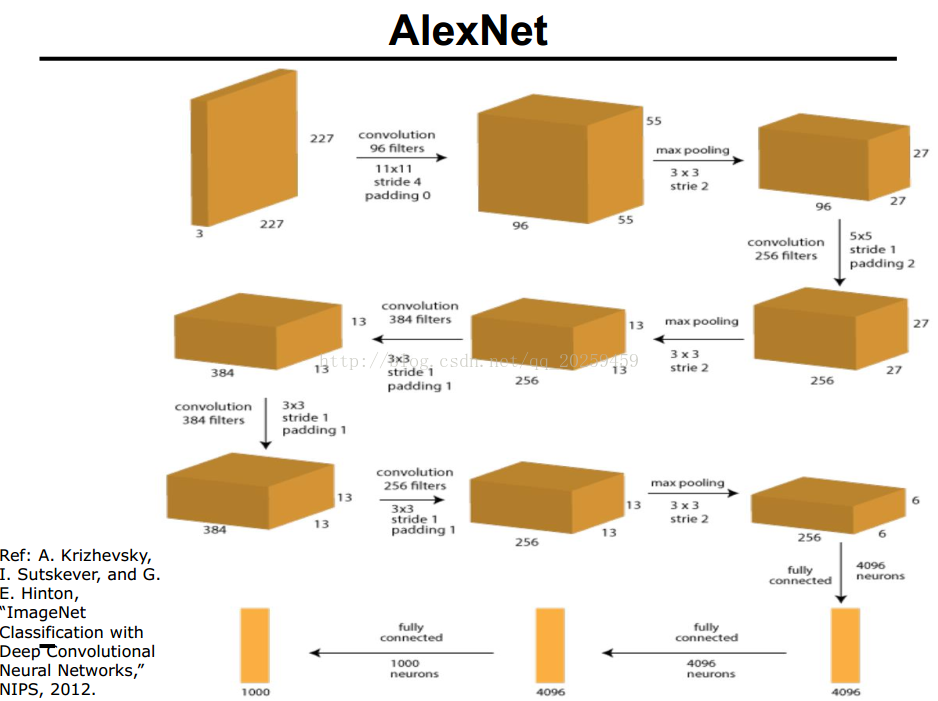
2. VGGNet(用小的filter得到更好的非线性和降低网络的权值以及实现了更深的构造):
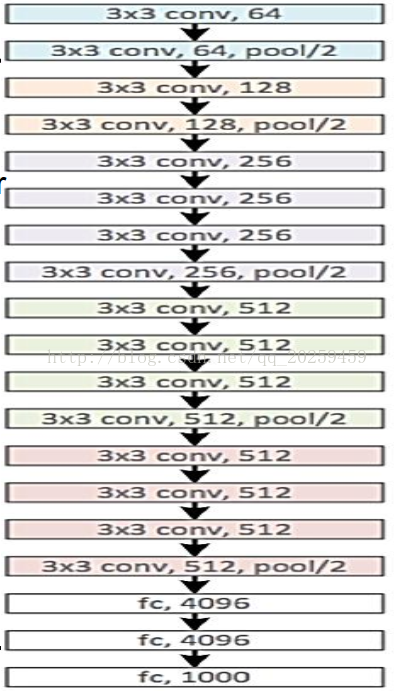
3. GoogleNet(新的结构的提出受启发于NiN,网络中的网络同时实现了更深和更非线性):

4. Latest(接受请参见:https://arxiv.org/abs/1608.06993 ):
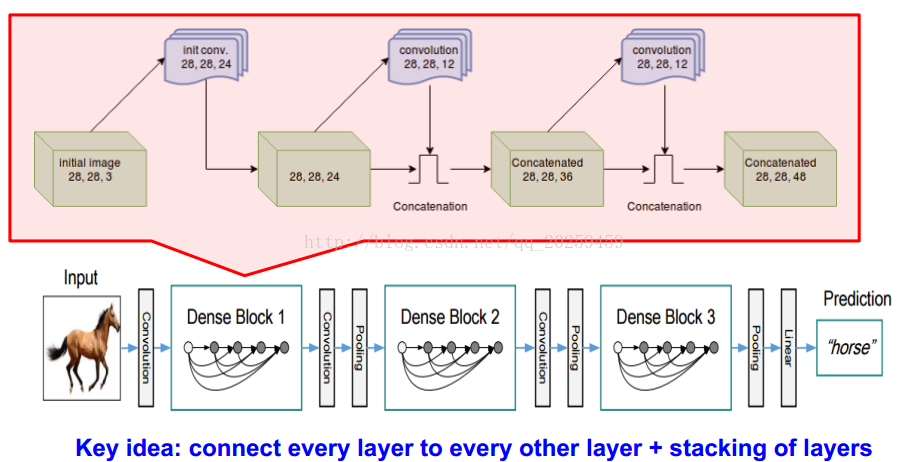
5. 比较分析:
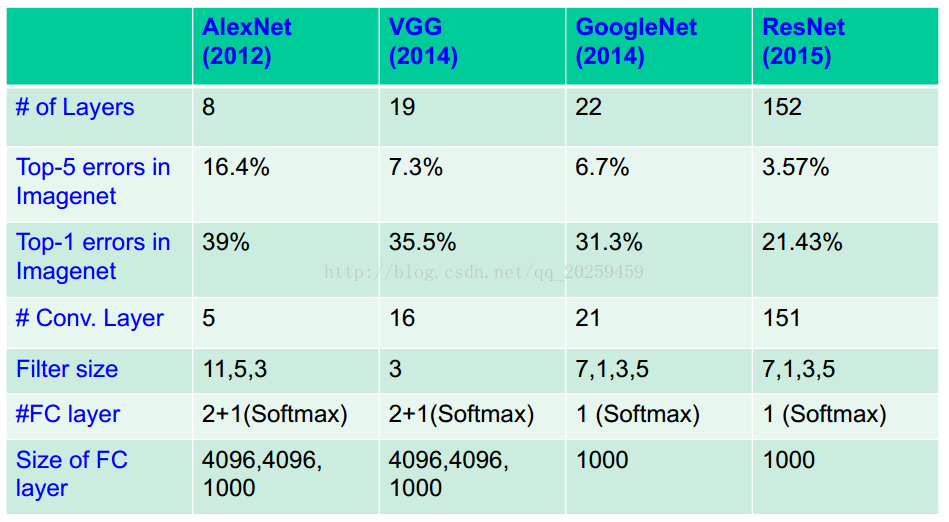
这里我们可以看出,不管你怎么调整网络,调整参数,你的目的只有一个就是让网络变得更加深层,更加非线性。














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









