






最近工作中遇到了G711a音频编码,之前只用到wav和pcm,特写此文对G711格式了解一番。
文章目录
- 采样和量化
- G711简介
- 二进制文件格式
- 参考来源
采样和量化
首先需要明确的两个概念,“采样”和“量化”。对于给定的一个波形,采样是从时间上将连续变成离散的过程,而采样得到的值,可能还是不能够用给定的位宽(比如8bit)来表示,这就需要经过量化,即从我们能够表示的离散值里面找一个跟采样值接近的值,近似地表示它。一般来说,量化是模拟音频到数字音频(PCM)过程中产生误差的唯一一个地方。
下面我们举个例子来说明,首先用matlab生成一个正弦波: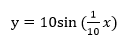
所以这个波形的周期: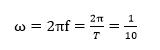
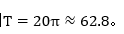
matlab代码为:
x=0:1:300;
y=10*sin(x/10);
plot(x,y,'r')
axis([0,300,-12,12]);
set(gca, 'XTickMode','manual','XTick',[0:20:300]);
set(gca,'YTickMode','manual','YTick',[-10:1:10]);grid
hold on
a=0:20:300;
b=10*sin(a/10);
plot(a,b,'*')
然后以20的采样周期采样得到图上的16个蓝色点。
16个点的坐标为:
[0, 9.092974268, -7.568024953, -2.794154982, 9.893582466, -5.440211109, -5.36572918, 9.906073557, -2.879033167, -7.509872468, 9.129452507, -0.088513093, -9.05578362, 7.625584505, 2.709057883, -9.880316241]
这些小数存储时要占用大量的空间,因此我们要通过量化,将其舍入到近似的整数,这样采样值就能用一个±16范围的整数来存储(5bit)。
根据采样定理,用大于信号最高频率两倍的频率,对周期信号进行采样,可以保证完全重构原始信号。由于G711主要用于传递话音,而人声最大频率一般在3.4kHz,所以只要以8k的采样频率对人声进行采样,就可以保证完全还原原始声音。
而人耳朵能够感知的声音频率在20kHz范围内,所以只要以大于40kHz频率采样,就可以完全重建原始声音。我们常常能见到44.1kHz采样的音乐文件,甚至更高采样频率,也是由于这个道理。之所以会取一个大于40k的采样频率比如44.1k、48k甚至更高的96k,我认为有以下几个原因:
(1)实际音频的频谱不是带宽限制的,在带外还有高频信号。因此我们需要先经过一个低通滤波器将高频信号滤掉。而实际的低通滤波器不是完整的在截止频率将信号截断,而是一个很陡峭的曲线,所以留出了一些余量保证滤除带外信号后不影响带内信号。(这个分析比较靠谱)
(2)采样之后需要经过量化,这带来了一些误差,重建出来的音频和原始的模拟音频有微小区别,通过增加量化深度或者采样频率能减少这种误差。(原作者的这个观点有待商榷,量化误差是幅值精度的问题,而采样率是频谱带宽的问题,不是一个维度上的,怎么能用增加采样率来补偿量化误差呢?)
(3)实际的采样窗口不是无限长的,加窗操作引入了一些大于奈奎斯特频率的信号,导致频率出现了混叠,影响了原始信号的恢复值。(这个分析比较靠谱)
(4)在音频制作过程中采用96k、192k甚至更高,可以满足一些后期处理的需要。而播放端播放96k的音频未必会比44.1k有更好的效果,两者的区别可能更多来自于前3条的原因。
G711简介
G711编码的声音清晰度好,语音自然度高,但压缩效率低,数据量大常在32Kbps以上。常用于电话语音(推荐使用64Kbps),sampling rate为8K,G.711 标准下主要有两种压缩算法。一种是u-law algorithm (又称often u-law, ulaw, mu-law),主要运用于北美和日本;另一种是A-law algorithm,主要运用于欧洲和世界其他地区。其中,后者是特别设计用来方便计算机处理的。
G.711就是语音模拟信号的一种非线性量化, bitrate 是64kbps. 详细的资料可以在ITU 上下到相关的spec,下面主要列出一些性能参数:
G.711(PCM方式)
• 采样率:8kHz
• 信息量:64kbps/channel
• 理论延迟:0.125msec
• 品质:MOS值4.10
G711算法采用8kHz采样率,有A-law和μ-law两种压扩方式,分别是将13bit和14bit编码为8bit,因此G711固定码率是8kHz*8bit=64kbps。两者都是对数变换,A-law更加方便计算机处理。μ-law提供了略微高一些的动态范围,但代价是对于弱信号的量化误差相对A-law高一些。两者均采用对数变换的原因也正是由于人耳对于声音的感知不是线性变化而是对数型变化的特性。
下面分别介绍两种算法:
A-law的公式如下,一般采用A=87.6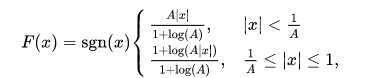
画出图来则是如下图,用x表示输入的采样值,F(x)表示通过A-law变换后的采样值,y是对F(x)进行量化后的采样值。
由此可见在输入的x为高值的时候,F(x)的变化是缓慢的,有较大范围的x对应的F(x)最终被量化为同一个y,精度较低。相反在低声强区域,也就是x为低值的时候,F(x)的变化很剧烈,有较少的不同x对应的F(x)被量化为同一个y。意思就是说在声音比较小的区域,精度较高,便于区分,而声音比较大的区域,精度不是那么高。
对应解码公式(即上面函数的反函数):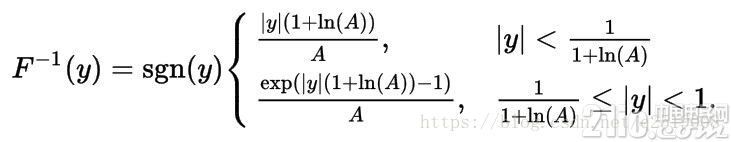
μ-law的公式如下,μ取值一般为255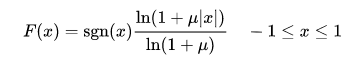
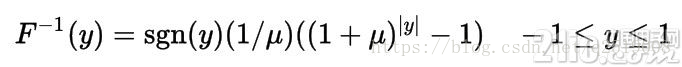
和A-law画在同一个坐标轴中就能发现A-law在低强度信号下,精度要稍微高一些。
以上是两种算法的连续条件下的计算公式,实际应用中,我们确实可以用浮点数计算的方式把F(x)结果计算出来,然后进行量化,但是这样一来计算量会比较大,实际上对于A-law(A=87.6时),是采用13折线近似的方式来计算的,而μ-law(μ=255时)则是15段折线近似的方式。
A-law如下表计算,第一列是采样点,共13bit,最高位为符号位。对于前两行,折线斜率均为1/2,跟负半段的相应区域位于同一段折线上,对于3到8行,斜率分别是1/4到1/128,共6段折线,加上负半段对应的6段折线,总共13段折线,这就是所谓的A-law十三段折线法
对应的解码公式则是: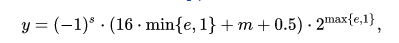
a-law也叫g711a,输入的是13位(其实是S16的高13位),使用在欧洲和其他地区,这种格式是经过特别设计的,便于数字设备进行快速运算。
运算过程如下:
(1) 取符号位并取反得到s
(2) 获取强度位eee,获取方法如下图所示
(3) 获取高位样本位wxyz
(4) 组合为seeewxyz,将seeewxyz逢偶数为取补数,编码完毕
示例1:
输入pcm数据为3210,二进制对应为(0000 1100 1000 1010)
二进制变换下排列组合方式(0 0001 1001 0001010)
(1) 获取符号位最高位为0,取反,s=1
(2) 获取强度位0001,查表,编码制应该是eee=100
(3) 获取高位样本wxyz=1001
(4) 组合为11001001,逢偶数为取反为10011100
编码完毕。
示例2:
输入pcm数据为1234,二进制对应为(0000 0100 1101 0010)
二进制变换下排列组合方式(0 00001 0011 010010)
1、获取符号位最高位为0,取反,s=1
2、获取强度位00001,查表,编码制应该是eee=011
3、获取高位样本wxyz=0011
4、组合为10110011,逢偶数为取反为11100110,得到E6
u-law也叫g711u,使用在北美和日本,输入的是14位,编码算法就是查表,没啥复杂算法,就是基础值+平均偏移值。
相应的μ-law的计算方法如下表:


示例1:
输入pcm数据为pcm=2345
(1)取得范围值
+4062 to +2015 in 16 intervals of 128
(2)得到基础值0x90
(3)间隔数128
(4)区间基本值4062
(5)当前值2345和区间基本值差异4062-2345=1717
(6)偏移值=1717/间隔数=1717/128,取整得到13
(7)输出为0x90+13=0x9D
示例2:
输入pcm数据为1234(以16bit的数据计算的,没有进行移位得到14bit的数据)
1、取得范围值,查表得 +2014 to +991 in 16 intervals of 64
2、得到基础值为0xA0
3、得到间隔数为64
4、得到区间基本值2014
5、当前值1234和区间基本值差异2014-1234=780
6、偏移值=780/间隔数=780/64,取整得到12
7、输出为0xA0+12=0xAC
二进制文件格式
发现忘了这一部分,罪过,后面补上
参考来源
本文参考来源为如下链接,感谢原作者们的工作,本文作为转载发布,转载的链接来源只能选择其中参考最多(不一定是内容最多,可能是最能说明要点的一篇)的一个作者的博文链接。
https://blog.csdn.net/zz460833359/article/details/82752468
https://blog.csdn.net/oHuiJian1/article/details/100674218















 2315
2315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









