






公众号关注 「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !
如何让你的 Kubernetes 集群使用 GPU 节点
CUDA 驱动程序
如果您还没有这样做,请确保您已在 GPU 节点上安装了 NVIDIA CUDA 驱动程序。CUDA是来自 nvidia 的并行计算平台。
https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
成功安装后,nvidia-smi终端中的命令应该会提供与此类似的输出。在这个节点上,我有两个 GPU。请注意,CUDA 工具包的更新版本比我这里的可用。

用于 Docker 的 NVIDIA 容器工具包
下一步是为 docker 安装 nvidia 容器工具包。根据您拥有的操作系统版本,说明可能略有不同。如果有疑问,您可以随时查看NVIDIA 文档。
https://docs.nvidia.com/datacenter/cloud-native/kubernetes/dcgme2e.html#install-nvidia-container-toolkit-previously-nvidia-docker2
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
$ yum update
$ yum install -y nvidia-docker2我们需要将 docker 的默认容器运行时更改为 nvidia。我们可以通过编辑文件/etc/docker/daemon.jsonfile 并更改default-runtime.
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}是时候重新启动 docker以使更改生效。
$ systemctl daemon-reload
$ systemctl restart docker现在我们可以通过运行 nvidia 提供的简单镜像来测试我们的 docker 环境。
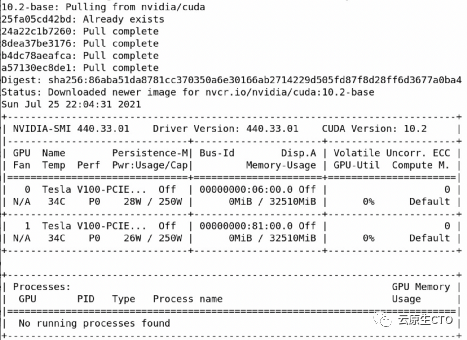
$ docker run --rm -it nvcr.io/nvidia/cuda:10.2-base nvidia-smi您应该会看到与此类似的输出。如上所述,您当然可以将来自 nvidia的 docker 镜像与更高版本的 cuda 工具包一起使用。
用于 Kubernetes 的 NVIDIA 设备插件
我们验证了 docker 环境已成功配置为支持 GPU加速容器。我们只需再迈出一步,我们也将为 Kubernetes 设置做好准备。让我们安装 NVIDIA 设备插件,以便我们的 Kubernetes 集群可以使用 GPU。最简单的方法是使用helm安装这个插件。如果没有 helm,安装也很简单。转到您的主节点并执行以下应安装 helm 的命令。
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 \
&& chmod 700 get_helm.sh \
&& ./get_helm.sh您将看到 helm 已安装。
Downloading https://get.helm.sh/helm-v3.6.3-linux-amd64.tar.gz
Verifying checksum... Done.
Preparing to install helm into /usr/local/bin
helm installed into /usr/local/bin/helm我们将 nvidia设备插件添加到helm存储库。
$ helm repo add nvdp https://nvidia.github.io/k8s-device-plugin \
&& helm repo update现在让我们安装插件。
$ helm install --generate-name nvdp/nvidia-device-plugin您可以通过检查kube-system命名空间中的 pod来验证已安装的插件。
$ kubectl get pods -n kube-system|grep -i nvidia
nvidia-device-plugin-daemonset-tl268 1/1 Running 3 4h
nvidia-device-plugin-daemonset-v2dn8 1/1 Running 8 4h测试一下
让我们测试我们的 Kubernetes 设置。为此,让我们创建一个 yaml 部署文件,例如,gpudemo-vectoradd.yaml包含以下内容。我们正在使用运行 GPU 的 nvidia cuda 示例容器。
apiVersion: v1
kind: Pod
metadata:
name: gpu-demo-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "nvidia/samples:vectoradd-cuda10.2"
resources:
limits:
nvidia.com/gpu: 1部署我们的 yaml文件。
$ kubectl apply -f gpudemo-vectoradd.yaml检查Pod。
$ kubectl get pods |grep gpu
gpu-demo-vectoradd 0/1 Completed 0 13s检查日志。它应该是这样的。
$ kubectl logs gpu-demo-vectoradd
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done我们验证了Kubernetes集群设置为运行GPU加速容器!在下一篇文章中,让我们看看如何暴露和监控这些GPU指标。
参考资料
[1]
参考地址: https://medium.com/@rajupavuluri/how-to-enable-your-kubernetes-cluster-to-use-gpu-nodes-1b2771b4a7f6
本文转载自:「云原生CTO」,原文:https://tinyurl.com/3nu9yuup,版权归原作者所有。欢迎投稿,投稿邮箱: editor@hi-linux.com。


你可能还喜欢
点击下方图片即可阅读

『小众摄影』01 期 :网红重庆•千年古镇磁器口
点击上方图片,『美团|饿了么』外卖红包天天免费领

更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!















 45
45

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









