






公众号关注 「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !

故障过去八天后,腾讯云发布了 4.8 号大故障的 复盘报告 。我认为是一件好事,因为阿里云双十一大故障的官方故障复盘至今仍然是拖欠着的。
公有云厂商想要真正成为 —— 提供水与电的公共基础设施,那就需要承担起责任,接受公众监督 —— 云厂商有义务披露自己故障原因,并提出切实的可靠性改进方案与措施。
那么我们就来看一看这份复盘报告,看看里面有哪些信息,以及可以从中学到什么教训。
事实是什么?
按照腾讯云官方给出的复盘报告(官方发布的“权威事实”)
1.15:23,监测到故障,立即执行服务的恢复,同时进行原因的排查;2.15:47,发现通过回滚版本没能完全恢复服务,进一步定位问题;3.15:57,定位出故障根因是配置数据出现错误,紧急设计数据修复方案;4.16:02,对全地域进行数据修复工作,API服务逐地域恢复中;5.16:05,观测到除上海外的地域API服务均已恢复,进一步定位上海地域的恢复问题;6.16:25,定位到上海的技术组件存在API循环依赖问题,决定通过流量调度至其他地域来恢复;7.16:45,观测到上海地域恢复了,此时API和依赖API的PaaS服务彻底恢复,但控制台流量剧增,按九倍容量进行了扩容;8.16:50,请求量逐渐恢复到正常水平,业务稳定运行,控制台服务全部恢复;9.17:45,持续观察一小时,未发现问题,按预案处理过程完毕。
复盘报告给出的原因是:云API服务新版本向前兼容性考虑不够和配置数据灰度机制不足的问题
本次API升级过程中,由于新版本的接口协议发生了变化,在后台发布新版本之后对于旧版本前端传来的数据处理逻辑异常,导致生成了一条错误的配置数据,由于灰度机制不足导致异常数据快速扩散到了全网地域,造成整体API使用异常。
发生故障后,按照标准回滚方案将服务后台和配置数据同时回滚到旧版本,并重启API后台服务,但此时因为承载API服务的容器平台也依赖API服务才能提供调度能力,即发生了循环依赖,导致服务无法自动拉起。通过运维手工启动方式才使API服务重启,完成整个故障恢复。
这份复盘报告中有一个存疑的点:复盘报告将故障归因为:向前兼容考虑不足。向前兼容性(Forward Compatibility)指的是老的版本的代码可以使用新版本的代码产生的数据。如果管控回滚到旧版本,无法读取由新版本产生的脏数据 —— 那这是确实是一个前向兼容性问题。
但在下面的解释中:是新版本代码没有处理好旧版本数据 —— 而这是一个典型的向后兼容性(Backward)问题。对于一个 ToB 服务产品,我认为这样的用词严谨性是有问题的。
原因是什么?
作为客户,我也在此前获取到私下流传的故障复盘过程,一份具有较高置信度的小道消息:
1.15:25 平台监控到云API进程故障告警,工程师立即介入分析;2.15:36 排查发现异常集中在云API现网版本,旧版本运行正常,开始进行回滚操作;3.15:47 官网控制台所用集群回滚完成,通过监控确定恢复;4.15:50 开始回滚非控制台集群;5.15:57 定位出故障根因是配置系统中存在错误数据;6.16:02 删除配置数据的错误数据,各地域集群开始自动恢复;7.16:05 由于历史配置不规范,导致上海集群无法通过回滚快速恢复,决策采用流量调度方式恢复上海集群;8.16:40 上海集群流量全量切换到其他地域集群;9.16:45 经过观测和现网监控,确认上海集群已经恢复。
应该说,官方发布的版本在关键点上基本上和几天前私下流出的版本是一致的,只是私下流传的版本更加详细地指出了根因: 相较旧版本,现网版本新引入逻辑存在对空字典配置数据兼容的bug,在读取数据场景下触发bug逻辑,引发云API服务进程异常 Crash。
根据这两份故障复盘信息,我们可以确定,这是一次由人为失误导致的故障,而不是因为天灾(硬件故障,机房断电断网)导致的。我们基本上可以推断出故障发生的过程分为两个阶段 —— 两个子问题。
第一个问题是,管控 API 没有保持良好的双向兼容性 —— 新管控 API 因为老配置数据中的空字典崩掉了。这体现出一系列软件工程上的问题 —— 处理空对象的代码基本功,处理异常的逻辑,测试的覆盖率,发布的灰度流程。
第二个问题是,循环依赖(容器平台与管控API)导致系统无法自动拉起,需要运维手工介入进行 Bootstrap。这反映出 —— 架构设计的问题,以及 —— 腾讯云并没有从去年阿里云的大故障中吸取最核心的教训。
影响是什么?
在复盘报告中,腾讯云用了大篇幅来描述故障的影响,解释管控面故障与数据面故障的区别。用了一些酒店前台的比喻。其实类似的故障在去年阿里云双十一大故障已经出现过了 —— 管控面挂了,数据面正常,在《我们能从阿里云史诗级故障中学到什么》中,我们也分析过,管控面挂了确实不会影响继续使用现有纯 IaaS 资源。但是会影响云厂商的核心服务 —— 比如,对象存储在腾讯云上叫 COS。
对象存储 COS 实在是太重要了,可以说是云计算的“定义性服务”,也许是唯一能在所有云上基本达成共识标准的服务。云厂商的各种“上层”服务或多或少都直接/间接地依赖 COS,例如 CVM/ RDS 虽然可以运行,但 CVM 快照和 RDS 备份显然是深度依赖 COS 的,CDN 回源是依赖 COS 的,各个服务的日志往往也是写入 COS 的。所以,任何涉及到基础服务的故障,都不应该糊弄敷衍过去。
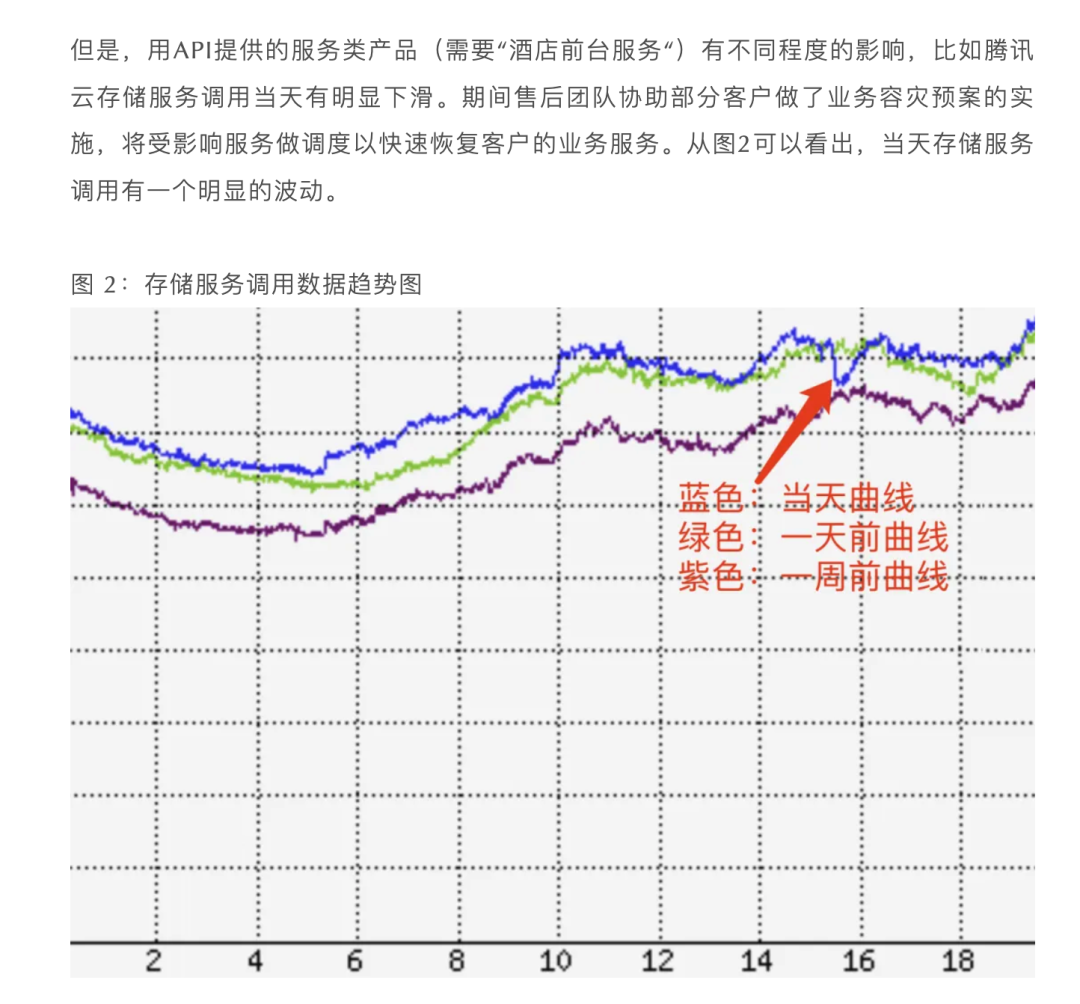
在腾讯云复盘报告中给出的这个图,确实是相当敷衍 —— 只有三条彩色线条,旨在证明这个故障其实非常轻微。但什么叫存储服务调用趋势图? —— 存储服务是对象存储还是块存储?图里的指标是什么?总请求数还是成功请求数?还是 IOPS,还是其他什么?是几分钟的聚合指标?有没有计算方式,能不能反应故障期间的影响?—— 甚至截图连 Y 坐标轴都没有。
评论与观点
马斯克的推特 X 和 DHH 的 37 Signal 通过下云省下了千万美元真金白银,创造了降本增效的“奇迹”,让下云开始成为一种潮流。云上的用户在对着账单犹豫着是否要下云,未上云的用户更是内心纠结。
在这样的背景下,作为本土云领导者的阿里云先出现史诗级大故障,紧接着腾讯云又再次出现了这种全球性管控面故障,对于犹豫观望者的信心无疑是沉重的打击。如果说阿里云大故障是公有云拐点级别的标志性事件,那么腾讯云大故障二次确认了这条投射线的方向。
这次故障再次揭示出关键基础设施的巨大风险 —— 大量依托于公有云的网络服务缺乏最基本的自主可控能力:当故障发生时没有任何自救能力,除了等死做不了别的事情。它也反映出了垄断中心化基础设施的脆弱性:互联网这个去中心化的世界奇观现在主要是在少数几个大公司/云厂商拥有的服务器上运行 —— 某个云厂商本身成为了最大的业务单点,这可不是互联网设计的初衷!
根据海恩法则,一次严重故障的背后有几十次轻微事故,几百起未遂先兆,以及上千条事故隐患。这样的事故对于腾讯云的品牌形象绝对是致命打击,甚至对整个行业的声誉都有严重的损害。Cloudflare 月初的管控面故障后,CEO 立即撰写了详细的事后复盘分析,挽回了一些声誉。腾讯云这次发布的故障复盘报告不能说及时,但起码比起遮遮掩掩的阿里云要好多了。
做一个故障复盘,也许会暴露更多草台班子的糗态 —— 看了这份复盘报告,我依然不会收回 “草台班子” 的评价。但是真正重要的是,通过故障复盘,提出改进措施,让用户看到改进的态度,对于用户的信心非常重要 —— 技术 / 管理草台是可以想办法改进的,但服务态度傲慢则是无药可医的。
公有云厂商想要真正成为 —— 提供水与电的公共基础设施,那就需要承担起责任来,并敢于接受公众与用户的公开监督。我在《腾讯云:颜面尽失的草台班子》中指出了腾讯云面对故障时的问题 —— 故障信息发布不及时,不准确,不透明。在这一点上,我欣慰的看到在复盘报告改进措施中,腾讯云能够承认这些问题并承诺进行改进。

当然,我依然要对腾讯云提出批评。在《云 SLA 是安慰剂还是厕纸合同》中我提出 —— 我自己作为腾讯云的用户,提了一个工单用于测试云上的 SLA 到底好不好使 —— 事实证明:不主张就不赔付,主张了不认账也可以不赔付 —— 这个 SLA 确实跟厕纸一样。
事后有朋友给我发了私信说,其实你只要狠狠的骂一顿客服就可以拿到 100 代金券,骂的狠一点还可以拿到两百。有人发了《腾讯云代金券背后的薅羊毛现象》还有几篇文章都提到了这个现象 —— 如果真是这样,那我只能说 —— 好好说话的真用户分文不付,来薅羊毛的骂一顿就乖乖上贡,这也太贱了。
但其实真正让我感到愤怒的是 —— 腾讯云选择在微信公众号上文章审核封口,以及给我的朋友施压撤稿 —— 这一点我不会原谅。社交媒体是个事实上的公共广场,而不是私人独立王国。微信公众号不让人批评腾讯云,阿里公关不让大家吃蒋太子的瓜,都是利用舆论平台在塑造群体意识。而公器私用,玩弄这种手段不会有好下场。
能学到什么?
往者不可留,逝者不可追,比起哀悼无法挽回的损失,更重要的是从损失中吸取教训 —— 要是能从别人的损失中吸取教训那就更好了。所以,我们能从腾讯云这场史诗级故障中学到什么?
不要把鸡蛋放在同一个篮子里,准备好 PlanB,比如,业务域名解析一定要套一层 CNAME,且 CNAME 域名用不同服务商的解析服务。这个中间层对于阿里云、腾讯云这样的全局云厂商故障非常重要,用另外一个 DNS 供应商,至少可以给你一个把流量切到别的地方去的选择,而不是干坐在屏幕前等死,毫无自救能力。
谨慎依赖需要云基础设施:
云 API 是云服务的基石,大家都期待它可以始终正常工作 —— 然而越是人们感觉不可能出现故障的东西,真的出现故障时产生的杀伤力就越是毁天灭地。如无必要,勿增实体,更多的依赖意味着更多的失效点,更低的可靠性:正如在这次故障中,使用自身认证机制的 CVM/RDS 本身就没有受到直接冲击。深度使用云厂商提供的 AK/SK/IAM 不仅会让自己陷入供应商锁定,更是将自己暴露在公用基础设施的单点风险里。
我的朋友/对手,公有云的鼓吹者瑞典马工和他的朋友AK王老板,一直主张呼吁用 IAM / RAM 做访问控制,并深度利用云上的基础设施。但是在这两次故障后,马工的原话是:
“我一直鼓吹大家用 IAM 做访问控制,结果两家云都出大故障,纷纷打我的脸。云厂商不管是 PR 还是 SRE,都在用实际行动向客户证明:“别听马工的,你用他那一套,我就让你系统完蛋”。
谨慎使用云服务,优先使用纯资源。在本次故障中,云服务受到影响,但云资源仍然可用。类似 CVM/云盘 这样的纯资源,以及单纯使用这两者的 RDS,可以不受管控面故障影响可以继续运行。基础云资源(CVM/云盘)是所有云厂商的提供服务的最大公约数,只用资源有利于用户在不同公有云、以及本地自建中间择优而选。不过,很难想象在公有云上却不用对象存储 —— 在 CVM 和天价云盘 上用 MinIO 自建对象存储服务并不是真正可行的选项,这涉及到公有云商业模式的核心秘密:廉价S3获客,天价EBS杀猪。
自建是掌握自身命运的终极道路:如果用户想真正掌握自己的命运,最终恐怕早晚会走上自建这条路。互联网先辈们平地起高楼创建了这些服务,而现在做这件事只会容易得多:IDC 2.0 解决硬件资源问题,开源平替解决软件问题,大裁员释放出的专家解决了人力问题。短路掉公有云这个中间商,直接与 IDC 合作显然是一个更经济实惠的选择。稍微有点规模的用户下云省下的钱,可以换几个从大厂出来的资深SRE 还能盈余不少。更重要的是,自家人出问题你可以进行奖惩激励督促其改进,但是云出问题能赔给你几毛钱的代金券?
明确云厂商的 SLA 是营销工具,而非战绩承诺
在云计算的世界里,服务等级协议(SLA)曾被视为云厂商对其服务质量的承诺。然而,当我们深入研究这些由一堆9组成的协议时,会发现它们并不能像期望的那样“兜底”。与其说是 SLA 是对用户的补偿,不如说 SLA 是对云厂商服务质量没达标时的“惩罚”。比起会因为故障丢掉奖金与工作的专家来说,SLA 的惩罚对于云厂商不痛不痒,更像是自罚三杯。如果惩罚没有意义,云厂商也没有动力去提供更好的服务质量。所以,SLA 对用户来说不是兜底损失的保险单。在最坏的情况下,它是堵死了实质性追索的哑巴亏;在最好的情况下,它才是提供情绪价值的安慰剂。
本文转载自:「非法加冯」,原文:https://url.hi-linux.com/quWKu,版权归原作者所有。欢迎投稿,投稿邮箱: editor@hi-linux.com。

最近,我们建立了一个技术交流微信群。目前群里已加入了不少行业内的大神,有兴趣的同学可以加入和我们一起交流技术,在 「奇妙的 Linux 世界」 公众号直接回复 「加群」 邀请你入群。

你可能还喜欢
点击下方图片即可阅读

Keep Screen On:只需打开网页,可以让电脑屏幕保持常亮
点击上方图片,『美团|饿了么』外卖红包天天免费领

更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!














 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









