







Meta 最新发布的 Llama4 模型引发了广泛争议。一方面,其被指在大模型竞技场中作弊,提交了经过“针对人类偏好优化”的实验版,而非开源社区熟悉的版本,导致其排名从第二位暴跌至第 32 位。这种行为被认为是为了在排行榜中获得更好名次而进行的“特供”优化,严重损害了社区对 Meta 的信任。另一方面,Llama4 的真实水平也备受质疑。在实际测试中,其编程能力表现欠佳,如在 KCORES 基准测试中,Llama4 Scout 和 Llama4 Maverick 落后于 GPT-4o 等模型。此外,Llama4 在长文本处理、上下文理解等方面也未达到预期,甚至出现了生成内容违背物理规律等问题。这些都表明 Llama4 的实际表现与官方宣传存在较大差距,其真实水平仍需进一步验证。
接下来我们通过8大领域300多项能力维度,来评估Llama4真实水平。
Llama4目前公开发布的有2个模型:
-
Llama-4-Scout-17B-16E-Instruct:总参数109B,激活参数17B。后续简称Llama-4-Scout。
-
Llama-4-Maverick-17B-128E-Instruct:总参数400B,激活参数17B。后续简称Llama-4-Maverick。
1、首先对比上一代Llama3
(1)Llama-4-Scout VS Llama-3.3-70B-Instruct
| 领域 | Llama-3.3-70B-Instruct | Llama-4-Scout | 变化 |
| 总分 | 59.98 | 61.99 | ↑3% |
| 医疗 | 59.21 | 65.42 | ↑10% |
| 教育 | 62.68 | 75.99 | ↑21% |
| 金融 | 56.89 | 62.11 | ↑9% |
| 法律 | 32.07 | 31.67 | ↓1% |
| 行政公务 | 66.40 | 55.50 | ↓16% |
| 心理健康 | 49.62 | 54.00 | ↑9% |
| 推理与数学计算 | 74.21 | 75.91 | ↑2% |
| 语言与指令遵从 | 77.97 | 76.19 | ↓2% |
更多细分维度结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
从上表可知:
-
整体效果上,Llama-4-Scout没有明显提升。
-
但在医疗、教育、金融、心理健康等领域,普遍有明显改善,提升幅度都达9%以上。
-
然而,Llama-4-Scout在行政公务领域效果远不如上一代的Llama-3.3-70B-Instruct。
(2)Llama-4-Maverick VS Llama-3.1-405B-Instruct
| 领域 | Llama-3.1-405B-Instruct | Llama-4-Maverick | 变化 |
| 总分 | 61.47 | 71.02 | ↑16% |
| 医疗 | 66.06 | 75.83 | ↑15% |
| 教育 | 59.11 | 82.29 | ↑39% |
| 金融 | 59.32 | 71.09 | ↑20% |
| 法律 | 36.77 | 48.00 | ↑31% |
| 行政公务 | 64.20 | 69.00 | ↑7% |
| 心理健康 | 53.88 | 59.00 | ↑10% |
| 推理与数学计算 | 73.15 | 82.41 | ↑13% |
| 语言与指令遵从 | 77.90 | 81.61 | ↑5% |
注:Llama-4-Maverick使用fp8
更多细分维度结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
从上表可知:
-
相比Llama-3,Llama-4-Maverick无论在整体还是各个细分领域都有明显改善。
-
进展最突出的是教育、金融、法律等领域。
-
而在通用能力方面(推理与数学计算、语言与指令遵从),改进则稍微小一些。
2、对比其他顶尖开源模型
我们用Llama-4-Maverick来对比qwen、qwq、deepseek等顶尖开源模型。
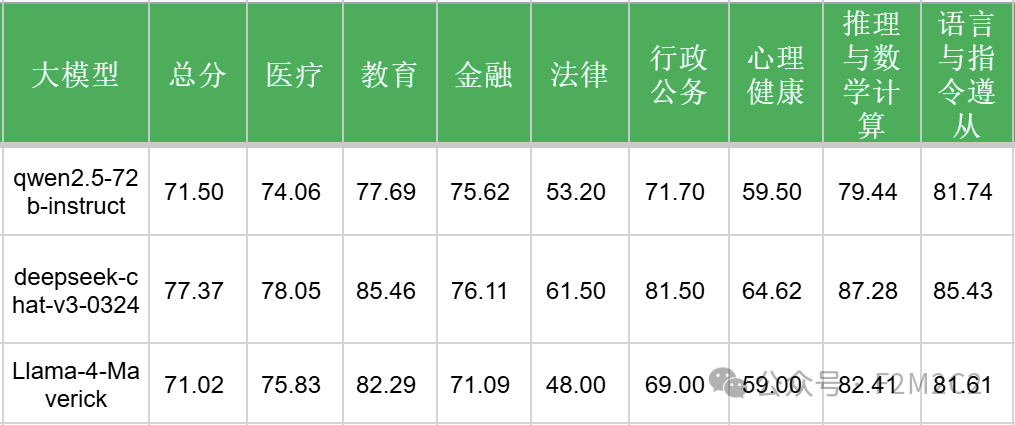
对比普通instruct模型
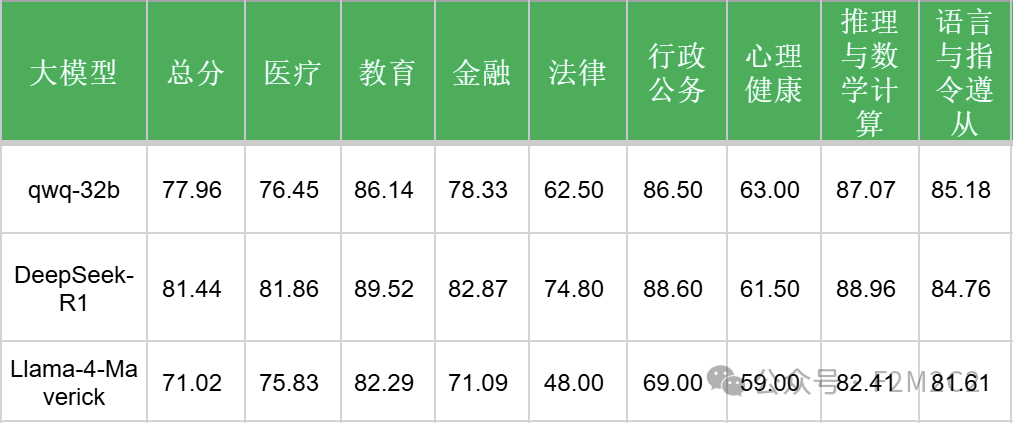
对比推理类模型
更多细分维度结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
可知:
-
相比普通instruct模型,Llama-4-Maverick和qwen2.5-72b基本处于同一水平,但都远落后于deepseek-chat-v3-0324。
-
对比推理类模型,差距则更大!基本上相差一个档次。
3、对比同价位的大模型
以输出价格(元/百万token)为准,Llama-4-Scout、Llama-4-Maverick分别为:2元、4元。
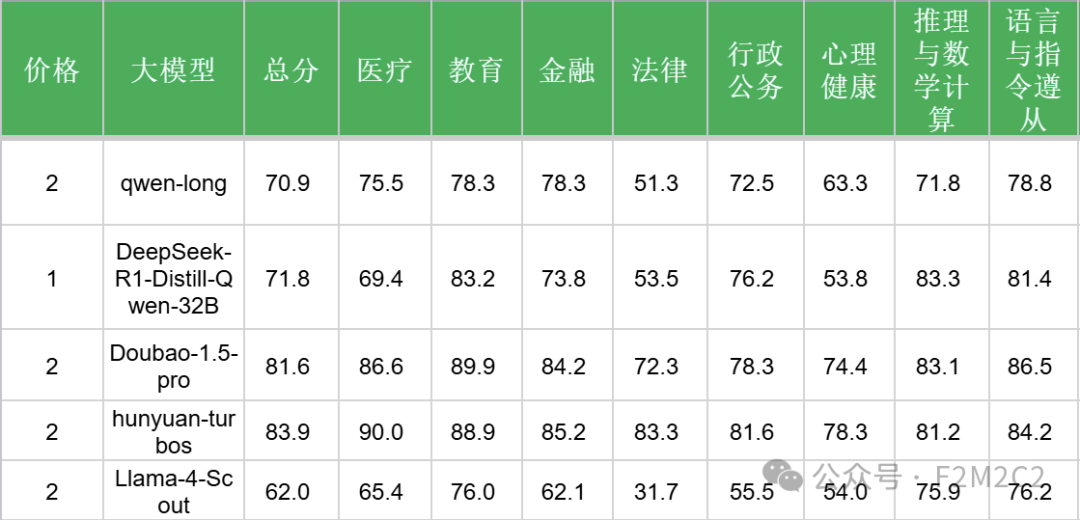
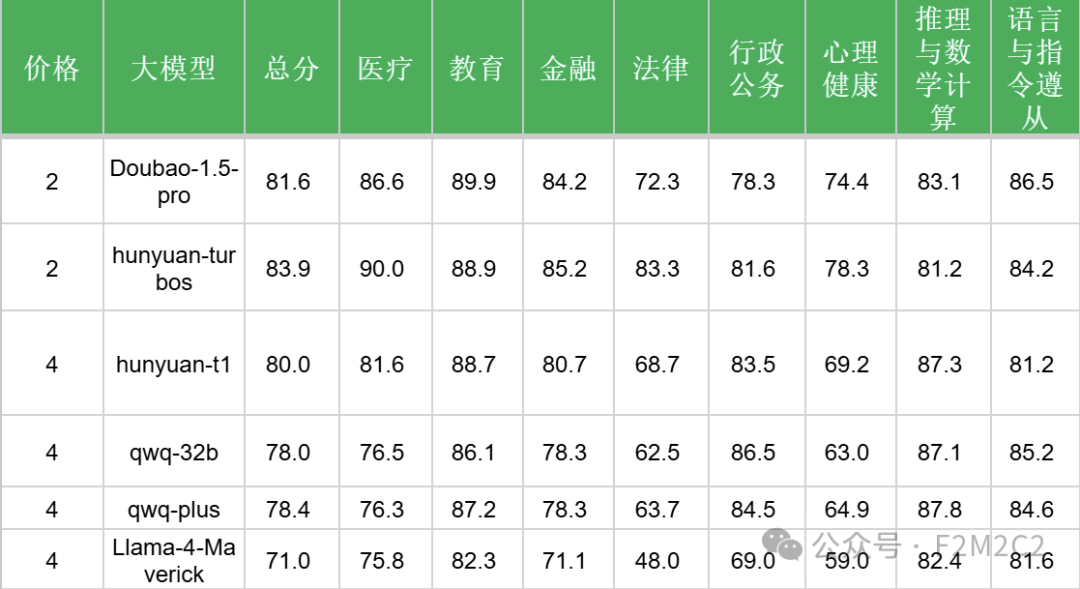
无论是整体还是各个细分领域,Llama-4-Scout、Llama-4-Maverick都分别远远弱于同等(甚至更低)价位的其他模型。
关于大模型评测EasyLLM:https://easyllm.site
-
最全——全球最全大模型评测平台,已囊括200+大模型、300+评测维度
-
最新——每周更新大模型排行榜
-
最方便——无需注册/梯子,国内外各个大模型可一键评测
-
结果可见——所有大模型评测的方法、题集、过程、得分结果,可见可追溯
-
错题本——百万级大模型错题本
-
免费——为您的私有模型提供免费的全方位评测服务,欢迎私信



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









