







作者:Wang, Josh
一、Kafka的基本概述
1、Kafka是什么?
Kafka官网上对Kafka的定义叫:Adistributed publish-subscribe messaging system。publish-subscribe是发布和订阅的意思,所以准确的说Kafka是一个消息订阅和发布的系统。最初,Kafka实际上是LinkedIn用于日志处理的分布式消息队列,LinkedIn的日志数据容量大,但对可靠性要求不高,其日志数据主要包括用户行为(登录、浏览、点击、分享、喜欢)以及系统运行日志(CPU、内存、磁盘、网络、系统及进程状态)。
2、Kafka能做什么?
现今,Kafka主要用于处理活跃的流式数据,如分析用户的行为,包括用户的pageview(页面浏览),以便能够设计出更好的广告位,对用户搜索关键词进行统计以便分析出当前的流行趋势,比如经济学上著名的长裙理论:如果长裙的销量高了,说明经济不景气了,因为姑娘们没钱买各种丝袜了。当然还有些业务数据,如果存数据库浪费,而直接用传统的存硬盘方式效率又低下,这个时候,也可以使用Kafka的分布式进行存储。
3、Kafka中的相关概念
· Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker。一台Kafka服务器就是一个broker,一个集群由多个broker组成,一个broker可以容纳多个topic。
· Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic,Kafka中Topic可以理解为一个存储消息的队列。物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存在一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处。
· Partition
Partition是物理上的概念,Kafka物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。如创建topic1和topic2两个topic,且分别有13个和19个Partition分区,则整个集群上相应会生成32个文件夹。为了实现扩展性,一个非常大的topic可以分布到多个broker上,但Kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
· Producer
负责发布消息到Kafkabroker。
· Consumer
消息消费者,向Kafkabroker读取消息的客户端。
· Consumer Group(CG)
这是Kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个 topic可以属于多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个CG只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。每个consumer属于一个特定的Consumer Group, Kafka允许为每个consumer指定group name,若不指定group name则属于默认的group。
4、Kafka的特性:
1)数据在磁盘上存取代价为O(1),而一般数据在磁盘上是使用BTree存储的,存取代价为O(lgn)。
2)高吞吐率:即使在普通的节点(非常普通的硬件)上每秒钟也能处理成百上千的message。
3)显式分布式:即所有的producer、broker和consumer都会有多个,均匀分布并支持通过Kafka服务器和消费机集群来分区消息。
4)支持数据并行加载到Hadoop中。
5) 支持Broker间的消息分区及分布式消费,同时保证每个partition内的消息顺序传输。
6)同时支持离线数据处理和实时数据处理:当前很多的消息队列服务提供可靠交付保证,并默认是即时消费(不适合离线),而Kafka通过构建分布式的集群,允许消息在系统中累积,使得Kafka同时支持离线和在线日志处理。
7)Scale out:支持在线水平扩展。
二、Kafka的架构设计
1、 最简单的Kafka部署图
如果将消息的发布(publish)称作producer,将消息的订阅(subscribe)表述为consumer,将中间的存储阵列称作broker,这样可以得到一个最简单的消息发布与订阅模型:

2、Kafka的拓扑图:
Kafka是显示的分布式消息发布和订阅系统,除了有多个producer, broker,consumer外,还有一个zookeeper集群用于管理producer,broker和consumer之间的协同调用。
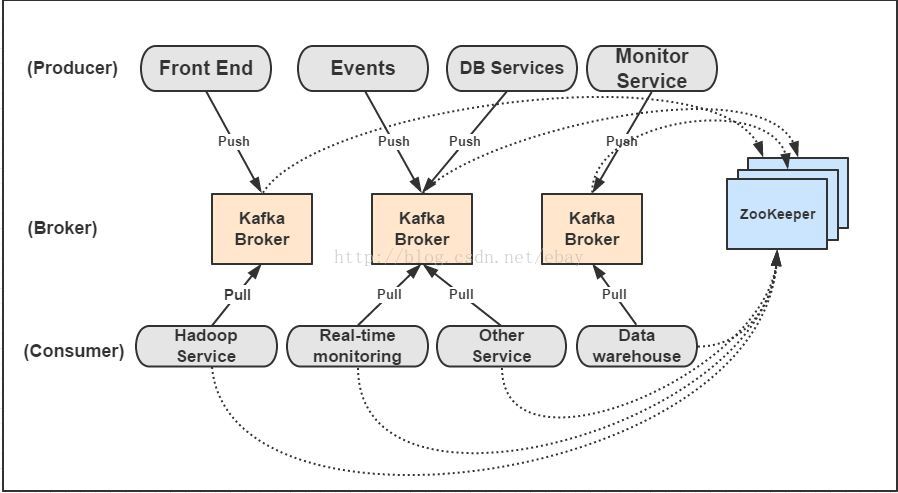
从图中可以看出,一个典型的Kafka集群中包含若干Producer(可以是web前端产生的PageView,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
图上有个细节需要注意,Producer到Broker的过程是push,也就是有数据就推送到Broker,而Consumer到Broker的过程是pull,是通过Consumer主动去拉数据的,而不是Broker把数据主动发送到Consumer端的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









